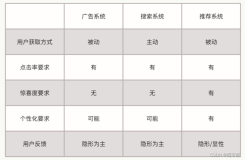
1. 跨域处理的问题
- Q1:源域数据与目标域的id不完全重叠。比如源域中有ID=100002的用户,但目标域中就没有。
解决方法:直接丢弃没有重叠的用户,使用不上这些数据
- Q2:源域数据与目标域重叠的id的曝光次数不一致(也就是行数不一致),无法直接拼接。比如ID=100002的用户,在源域中曝光次数有7条数据,但在目标域中的曝光次数只有1条数据。
解决方法:
1)把某一用户的历史曝光聚合成1条数据,这样尽管源域和目标域的曝光次数不一致,但一个用户最后总是可以聚合成一条数据,可以拼接在一起进行训练。但是会出现测试集无法聚合的问题,本质上还是要判断用户的当前行为是否会点击广告。
2)不聚合目标域,只聚合源域,把源域的每个用户数据聚合成1条,然后与目标域进行拼接。这样聚合的原因是源域的数据是用来辅助目标域来判断的,这样做的背后逻辑是为目标域的用户补充一个相同的源域信息。(可行)
- Q3:无论是源域还是目标域的数据集,其测试集都会出现训练集没有出现过的用户ID。
解决方法:
这个其实不算是问题,本质上只需要目标域的用户ID被源域的用户ID覆盖即可,而经过分析, 无论是训练集还是测试集,对于媒体这个领域的用户id号是均完全涵盖广告的用户id 。所以,这里只需要对源域的用户ID进行编码,如果用通用的方法对目标域的用户进行编码。然后安装训练的方法,把源域的用户ID信息聚合成1条,分别拼接在每个目标域的曝光行为上。
通过这样的方法,无论目标域与源域的数据之间的曝光次数多么的不匹配,总可以实现拼接在一起。
- Q4:特征处理问题,由于无法直接拼接,特征如何处理?如何进行Embedding操作?
解决方法:对源域某一用户的历史行为全部聚合成一条信息,再与对应目标域数据进行一一拼接,实现了数据的补充,以解决训练集与测试集数据分布不一致的问题
- Q5:列表数据的特征划分
源域所有特征作为补充数据。
目标域可以切分为用户本身特征与广告相关特征还有其他相关特征,而广告相关特征又可以分为目标广告特征与历史广告交互,下面进行汇总。
目标域的特征切分,主要分为4个大类:
1)用户本身特征(user_info)
[user_id, age, gender, residence, city, city_rank, series_dev, series_group, emui_dev, device_name, device_size]
2)目标广告特征(target_ad)
目标广告相关特征包括:[net_type, task_id, adv_id, creat_type_cd, adv_prim_id, inter_type_cd, slot_id, site_id, spread_app_id, Tags, app_second_class, app_score]
3)历史广告交互特征(interact_ad)
历史广告交互特征包括:[ad_click_list_001, ad_click_list_002, ad_click_list_003, ad_close_list_001, ad_close_list_002, ad_close_list_003]
4)其他特征(content_info)
这里把无法放在一起上归类的特征,单独分为其他特征,主要是时间戳与样本id:[pt_d, log_id, u_newsCatInterestsST, u_refreshTimes, u_feedLifeCycle]
对于的特征数据,可以具体参考deepctr的三种数据类型处理(具体看源码)。
- Q6:如何利用目标域的4个部分与源域的信息
在MiNet模型的基础上,团队改进设计了Interest-level Attention模块。首先,将目标域特征切分出来的4组特征以及源域信息看成是5个信息块。这些信息块在后续将构成目标域训练的特征。那么如何决定每个用户的哪个信息块起主要作用,就是Interest-level Attention模块的研究重点。
我们为每个信息块设计了三个可学习参数矩阵:V_params,g_params,b_params,根据下述的计算公式为每个信息块得到一个可学习的权重控制矩阵。
计算公式为:

每个信息块单独与自己的权重控制矩阵相乘,已获得最后的结果,最后再将这些信息块拼接起来,作为目标域信息特征。
- Q7:源域的标签信息如何使用?
分析:
一方面,可以对其直接进行编码,作为目标域信息的补充,让模型自动的发掘其他特征与标签特征之间的关系;(纠结的点是,作为数据补充的源域数据,其标签信息是否需要聚合处理,这里决定直接聚合,单纯的作为一些数据的补充)——后续改进是,可以使用item-level attention,来决定哪一条数据更加重要
另一方面,可以单独对源域另外做一个监督任务,将label,cilLabel,pro作为一个有监督的标签,来更新源域的其他特征数据。更新后的特征embeding用来给目标域进行聚合处理,进行联合训练。
最后的损失函数可以是目标域的损失与源域损失的加权和。
2. 代码思路
代码思路
1)特征处理(变长特征编码处理,其余稀疏特征编码处理)
2)特征划分(目标域数据切分为4个部分,然后融合源域信息)
3)模型搭建(先实现MiNet逻辑正确可训练,后续可以再改进)
4)训练与测试(分别为跨域训练,源域训练构建两个损失函数)
训练与测试的难点:
训练时,根据目标域的id移植对对应的源域数据拼接到目标域中;同样的,对于embedding的权重训练完成后进行测试时,同样对对应的源域数据移植到目标域中进行拼接预测。
而训练时,由于数据量较多,一般会设置batchsize,此时同样的,根据目标域的user_id,将对于的源域数据进行拼接即可。源域的数据是融合的embedding组成,可训练。
但是,目标域的训练集可以配合源域的训练集训练,但是目标域的测试集如何使用源域的数据?也就是训练好的源域训练数据无法作用在目标域的测试集中。
解决方法:为目标域和源域的用户重新编码即可,这样就可以利用训练好的内容。
3. 完整框架
- 流程结构图

- 设计步骤
步骤1:首先对于来至目标域的数据集进行特征处理,具体来说就是对其变长特征进行编码处理,其余稀疏特征编码处理。但是其中的特征由于是变长,所以需要添加掩码操作。实现操作上,对特征进行编码处理后的特征值作为value,构建一个embedding_dict的编码表,那么value通过embedding_dict之后才是作为后续处理的值。此时,还需要构建一个mask_dict的掩码表,对刚刚处理后的数据进行进一步的处理。
步骤2:需要注意,由于数据比较多,刚刚的处理过程是对一个batch的数据来进行处理的。现在在重复一下,就是dataloader中每次sample出一个batch的数据,这个batch数据的value都需要经过编码表embedding_dict与掩码表mask_dict的双重操作得到目标域的处理输出。
步骤3:现在经过了上诉的两个步骤已经得到了目标域处理好的数据,现在需要融合源域的数据。对于目标域数据来说,这里有每个用户的ID。那么可以根据相关的id在对应的源域数据集sample出当前所有可以匹配上的用户,也就是说,在当前一个batch数据中出现的用户在源域数据中将其全部找出构建成一个动态的源域用户信息。
步骤4:对于筛选出的动态源域用户信息,这个数据组成中同样用于变长稀疏特征,所以同样需要为其构建一个编码表embedding_dict与掩码表mask_dict。同时在这个动态的源域用户信息中还存在一些有监督的信息,这里我使用了源域的两个有监督信息:是否点击,是否点赞来为当前这个动态的源域用户信息来构建一个loss,用来更新源域用户的embedding_dict编码表。
步骤5:源域的用户信息不仅仅用来构建一个loss,同时对于相同用户ID的数据信息进行融合,也就是说多条的用户曝光信息融合成1条,这样组合成一个用户一条融合信息,这样就可以拼接回去目标域的输出处理中。每个相同的用户拼接来自与源域处理的相同的ID信息,依次实现跨域的数据融合操作。此时的数据拼接成一个信息维度更大的数据矩阵。
步骤6:此时的数据组成可以切分为对个模块,比如刚刚拼接过来的源域数据模块,还有目标域本身本我划分的几个模块:用户本身特征(user_info),目标广告特征(target_ad),历史广告交互特征(interact_ad),其他特征(content_info)4个部分。那么,现在看来当前的跨域处理数据矩阵其实是由5个模块组成,这里我对其做一个interest-level-attention操作,进行一个注意力的划分,实现模块间权重的重新匹配。
步骤7:作为基于注意力机制的权重重分配处理后,就可以将矩阵输入给后续的深度学习模型MLP中(一般设置为2层),同时这里使用了FM模型来进行辅助处理,同时使用深度学习模型与FM,以期望获得更好的预测效果,这里得到的loss是作为目标域的loss。
步骤8:最后的总损失是目标域的ctr预测loss加上源域数据的loss,来达到两个域联合训练的效果。不断更新源域数据的编码表embedding_dict与目标域数据的编码表embedding_dict既深度学习模型参数及注意力机制中的权重分配可学习参数。
整个算法的流程如上所示,代码地址:https://github.com/Clichong/CTR
参考资料:
《MiNet: Mixed Interest Network for Cross-Domain Click-Through Rate Prediction》