使用模型度量堆栈进行模型监视,对于将已部署的ML模型的反馈回路放回模型构建阶段至关重要,这样ML模型可以在不同的场景下不断改进自己。
背景
ML模型正在推动企业做出一些最重要的决策。因此,这些模型一旦部署到生产环境中,就必须在最新数据的上下文中保持相关性。如果存在数据歪斜,模型可能会脱离上下文,即数据分布可能在生产中与训练期间使用的数据不同。也可能是生产数据中的某个特征变得不可用,或者模型可能不再相关,因为实际环境可能已经改变(例如,Covid19),或者更简单地说,用户行为可能已经改变。因此,监控模型行为的变化以及推理中使用的最新数据的特征至关重要。这确保模型与模型训练阶段承诺的预期性能保持相关性和真实性。
这种模型监测框架的实例如下图2所示。目标是跟踪各种指标的模型,我们将在下一节中详细介绍这些指标。但首先,让我们了解模型监控框架的动机。
动机
反馈循环在生活和商业的各个方面都发挥着重要作用。反馈循环很容易理解:你生产了一些东西,测量了关于生产的信息,并利用这些信息来提高生产。这是一个不断监测和改进的循环。任何具有可测量信息和改进空间的东西都可以包含反馈循环,ML模型当然可以从中受益。
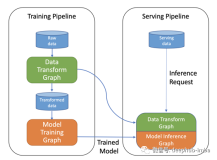
典型的 ML 工作流包括数据接入、预处理、模型构建和评估以及最终部署等步骤。然而,这缺乏一个关键部分,即反馈。因此,任何“模型监控”框架的主要动机都是在部署后回到模型构建阶段(如图1所示)。创建这个非常重要的反馈循环,这有助于 ML 模型决定更新模型或继续使用现有模型来不断改进自身。为了实现这一决策,框架应在下面描述的两种可能的场景下跟踪和报告各种模型指标(详见下文“指标”部分)。
- 场景一:训练数据可用,框架在部署后根据训练数据和生产(推理)数据计算所述模型指标,并进行比较以做出决策。
- 场景二:训练数据不可用,框架仅根据部署后可用的数据计算所述模型指标。
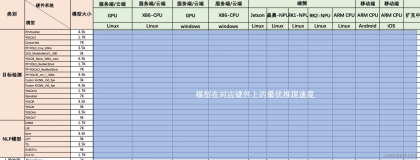
下表列出了模型监控框架在两种场景下生成所述指标所需的输入。
根据上面两个场景中哪一个适用,计算下一节中突出显示的指标,以决定生产环境中的模型是否需要更新或一些其他干预措施。
指标
下面的图3给出了建议的模型监控指标堆栈。它基于指标对数据和ML模型的依赖性定义了三种广泛的指标类型。
理想情况下,监控框架应包括所有三个类别中的一个或两个指标,但如果存在权衡,则可以从基础开始建立,即从运营指标开始,然后随着模型的成熟度建立。此外,应更加实时地或至少每天监测运营指标,其中稳定性和性能可以每周或更大的时间范围,具体取决于域和业务场景。
图3. Model Monitoring Metrics Stack
稳定性指标
这些指标有助于我们捕获两种类型的数据分布变化:
- a)先验概率偏移-捕获预测输出或因变量在训练数据和生产数据(场景一)或生产数据的各个时间框架(场景二)之间的分布偏移。这些指标的例子包括群体稳定性指数(PSI)、偏离指数(概念偏移)、误差统计。
监控 AI 系统的预测输出以检测先验概率偏移
- b)协变量偏移-捕捉训练数据和生产数据(场景一)或生产数据的不同时间框架(场景二)之间每个独立变量的分布移位(如适用)。这些指标的示例包括特征稳定性指数(CSI)和新颖性指数(Novelty Index)。
监控 AI 系统的输入数据以检测协变量偏移
性能表现指标
这些指标有助于我们检测数据中的概念偏移,即确定独立变量和因变量之间的关系是否发生了变化(例如,在COVID之后,用户在节日期间的购买方式可能发生了变化)。他们通过检查现有部署模型在接受训练时(场景一)或在部署后的前一个时间范围内(场景二)的性能好坏来实现。因此,可以决定是否重新处理部署的模型。这些指标的示例包括:
- a) 任务指标,如RMSE、R-Square等,用于回归任务;准确率,AUC-ROC等,用于分类任务。
- b) 基尼系数和KS-统计:预测概率/类别分离程度的统计度量(仅适用于分类模型)
监控 AI 系统中使用的 ML 模型以检测概念漂移
运营指标
这些指标有助于我们从使用角度确定部署模型的性能。它们与模型类型、数据无关,不需要任何输入。这些指标的示例包括:
- 调用ML API接口的吞吐量(请求数)
- 调用ML API接口时的延迟(平均响应时间)
- 执行预测时的IO/内存/CPU使用情况(平均消耗)
- 系统正常运行时间
- 磁盘利用率(平均消耗)
结论
MLOps领域内的模型监控已成为成熟ML系统的必要条件。实现这样的框架以确保ML系统的一致性和健壮性是至关重要的,因为没有它,ML系统可能会失去终端用户的“信任”,这可能是致命的。因此,在任何ML场景实现的总体解决方案体系结构中包含并规划模型监控是至关重要的。
在本系列的下一篇博客中,我们将更详细地介绍两个最重要的模型监控指标,即稳定性和性能指标,我们将了解如何使用它们来构建我们的模型监控框架。