前言
目标检测中,训练COCO数据(标注好的)时,我们不一定想要全部的80个类别的数据,而是想要一些指定类别的数据作用于特点的任务。比如:行人检测、车辆检测和动物检测等等。本文正是介绍如何使用Python将COCO数据集(标注好的)进行划分。
coco数据集80个类别:
person bicycle car motorbike aeroplane bus train truck boat traffic light fire hydrant stop sign parking meter bench bird cat dog horse sheep cow elephant bear zebra giraffe backpack umbrella handbag tie suitcase frisbee skis snowboard sports ball kite baseball bat baseball glove skateboard surfboard tennis racket bottle wine glass cup fork knife spoon bowl banana apple sandwich orange broccoli carrot hot dog pizza donut cake chair sofa pottedplant bed diningtable toilet tvmonitor laptop mouse remote keyboard cell phone microwave oven toaster sink refrigerator book clock vase scissors teddy bear hair drier toothbrush
数据集:标注好的COCO数据分享
链接:https://pan.baidu.com/s/18P-hi8a4VVZlffFzLPj3xA
提取码:k0l8
--来自百度网盘超级会员V3的分享
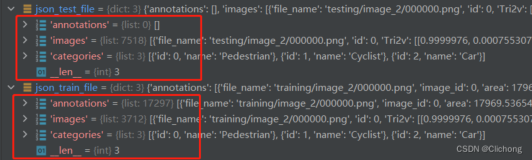
示例:提取汽车类
'''
进行目标检测时,有时只需要训练数据集中的部分图像,以 coco128 为例,只选出其中的车辆类:bicycle car motorcycle bus truck。
coco128 数据集中的标签为 txt 文件,
每一个图像由若干行,每一行对应一个目标的类别序号和 4 个坐标(中心 x,中心 y,宽,高,只需要选出指定类别序号的 txt 文件,
然后保存同名的图像文件即可。coco 数据集同理。
# 从coco128中提取车类的image和label # 1 car # 3 bus # 4 truck
'''
.py
import os from shutil import copyfile import xml.etree.ElementTree as ET def get_objectName(xmlpath): dom=ET.parse(xmlpath) root=dom.getroot() allobj=root.findall("object") xmlNames = [] for i, obj in enumerate(allobj): xmlNames.append(obj.find('name').text) # print('the obj-{} name is:{}'.format(i,obj.find('name').text)) return xmlNames def get_JPGImgName(xmlpath): dom=ET.parse(xmlpath) root=dom.getroot() #print(root.find('filename').text) return root.find('filename').text def split_VOC2007(src_im_path, src_xml_path, dst_im_path, dst_xml_path, split_classes=[]): for xml_name in os.listdir(src_xml_path): sub_xml = os.path.join(src_xml_path, xml_name) for obj_name in get_objectName(xmlpath=sub_xml): #print(obj_name) if obj_name in split_classes: # -- xml -- copyfile(sub_xml, os.path.join(dst_xml_path, xml_name)) # -- jpg -- im_name = get_JPGImgName(sub_xml) sub_im = os.path.join(src_im_path, im_name) copyfile(sub_im, os.path.join(dst_im_path, im_name)) print('{}|{} is copy!'.format(sub_xml, sub_im)) pass if __name__ == '__main__': split_calsses = ['car', 'bus', 'truck'] split_VOC2007(src_im_path=r'VOC2007_JPEGImages',src_xml_path=r'VOC2007_Annotations', dst_im_path=r'VOC2007\JPEGImages', dst_xml_path=r'VOC2007\Annotations', split_classes=split_calsses)
完毕!
是不是超级简单呢?如果觉得 有用的话,欢迎大家点赞+收藏!