能力说明:
通过课程学习与实战项目,熟练掌握Python的语法知识与编程技能,具备Python语言的函数、面向对象、异常处理等能力,常用开发框架的实际应用和开发能力,具备使用,掌握Python数据分析三剑客Matplotlib、Numpy、Pandas的概念与应用场景,掌握利用Python语言从数据采集到分析的全流程相关知识。
能力说明:
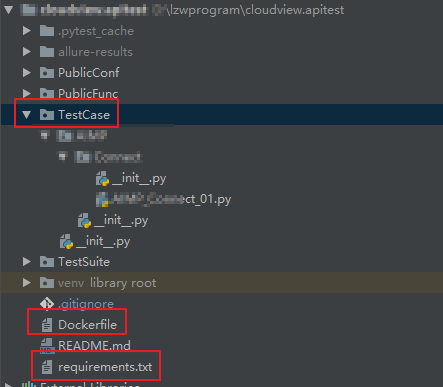
熟练掌握Docker各类高级特性,包括容器数据卷、DockerFile构建等;熟练使用Docker封装MySQL、Redis、Tomcat、Apache等镜像,并可在公有云或私有云部署并保持稳定运行。
能力说明:
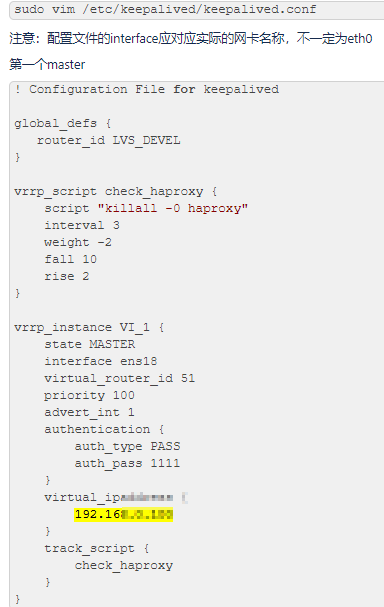
熟练掌握Linux常用命令、文件及用户管理、文本处理、Vim工具使用等,熟练掌握企业IP规划、子网划分、Linux的路由、网卡、以及其他企业级网络配置技术,可进行Web服务器(Nginx),以及数据库(My SQL)的搭建、配置、应用,可根据需求编写Shell脚本,通过常用工具进行linux服务器自动化运维。
 云原生数据库Clouder认证:PolarDB 快速入门
弹性计算Clouder认证:ECS基础运维管理
弹性计算Clouder认证:企业级ECS集群运维管理
弹性计算Clouder认证:高可用应用架构
弹性计算Clouder认证:企业级云上网络构建
云原生数据库Clouder认证:PolarDB 快速入门
弹性计算Clouder认证:ECS基础运维管理
弹性计算Clouder认证:企业级ECS集群运维管理
弹性计算Clouder认证:高可用应用架构
弹性计算Clouder认证:企业级云上网络构建
devops技术爱好者 自有博客:https://www.yinyubo.com 联系作者QQ:357244849
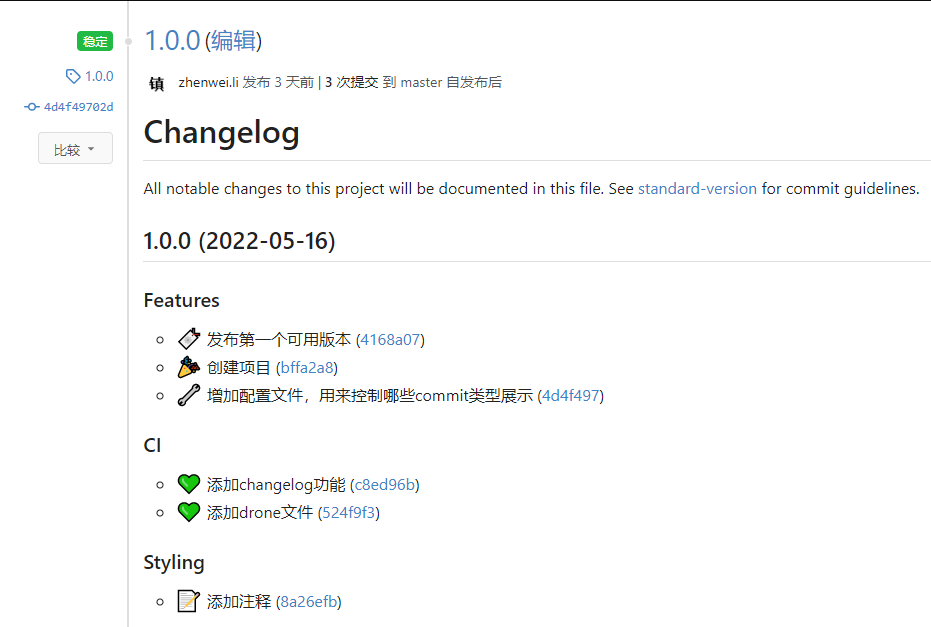
使用https://github.com/conventional-changelog/standard-version和vscode插件”Conventional Commits”工具规范开发人员提交git日志
因为有很多人是先通过apt的访问安装了稳定版的nginx。后面突然要增加第三方模块如geoip或者nginx-module-vts等别的模块,这个时候就可以采用本文的方式去动态增加模块。
我们经常会在网上看到K8S和周边工具的教程,例如HELM的使用,droneCI的使用,但是很少有文章写,如何基于K8S进行二次开发,本篇文章将使用python和vue进行K8S的二次开发,实现一个简单的查询k8s的pod和node信息的页面
Minio是就地环境下比较好用的对象存储工具,适合在CI/CD流程中使用。主要是因为GIT里用LFS来放大文件不妥,把部署流程中需要的中间文件放minio上,通过SDK去存取文件非常方便。 Minio的上传文件fput_object有progress参数,但是下载文件fget_object默认没有 progress 参数,所以我们需要自己用get_object对代码稍加改造,把下载流和进度条结合在一起
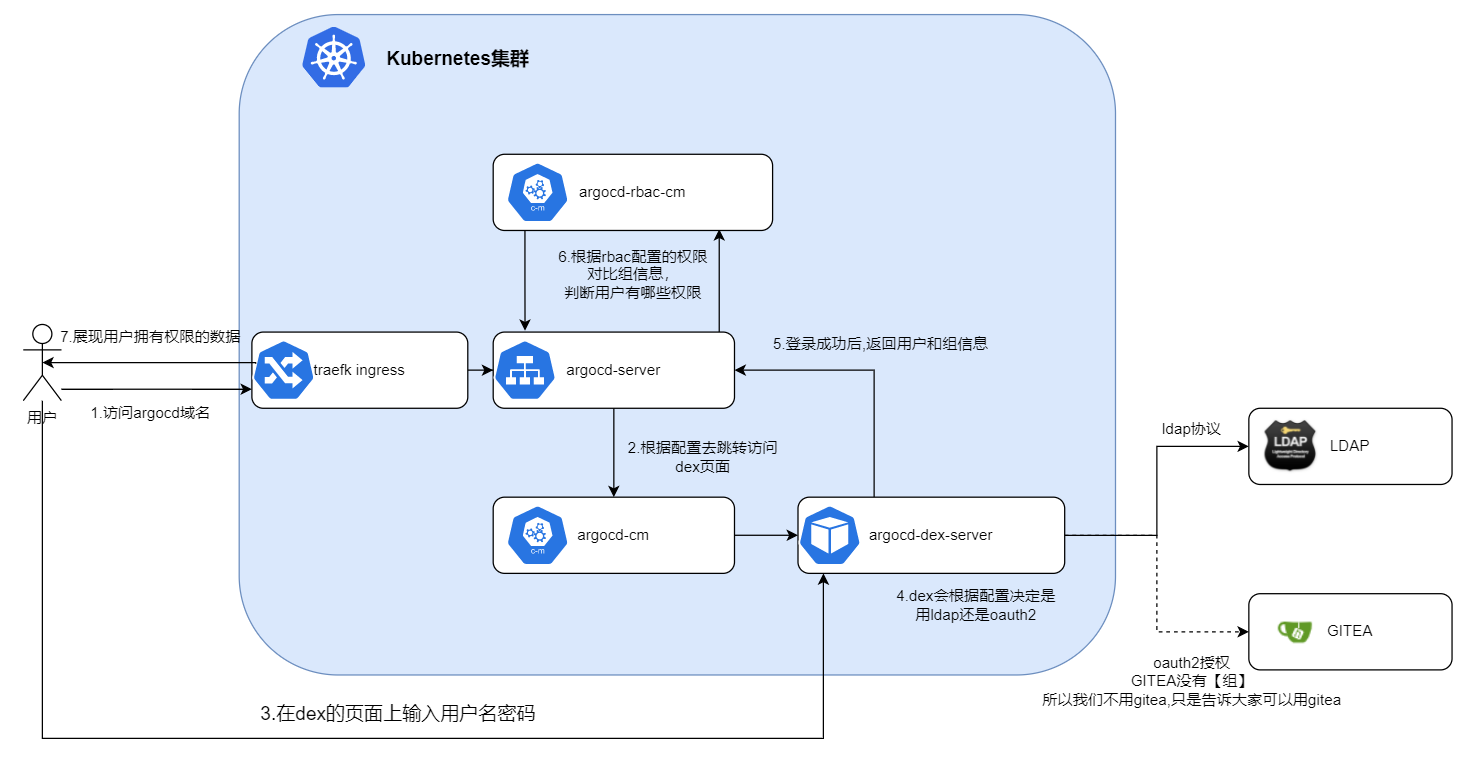
argocd默认是通过修改argocd-cm来添加账户的,添加完账户后,还需要使用argocd客户端命令去给账户设置密码,这肯定是比较麻烦的,为了方便使用,我们可以接入ldap认证或者gitea的oauth2认证。 这里我们主要写ldap认证,因为gitea没有提供组信息给dex,而ldap能返回组信息 ,gitea的接入会在文章的末尾进行简单介绍 关键词:argocd ldap dex
wxpython和pyecharts可以搭配使用,在桌面程序中展示web形式的图表。但是在使用pyinstaller打包成exe文件后,可能会出现一些BUG
做自动化测试的时候,经常会遇到有两个json文件。两个都是复杂嵌套格式。需要比对A.json里是否包含b.json。
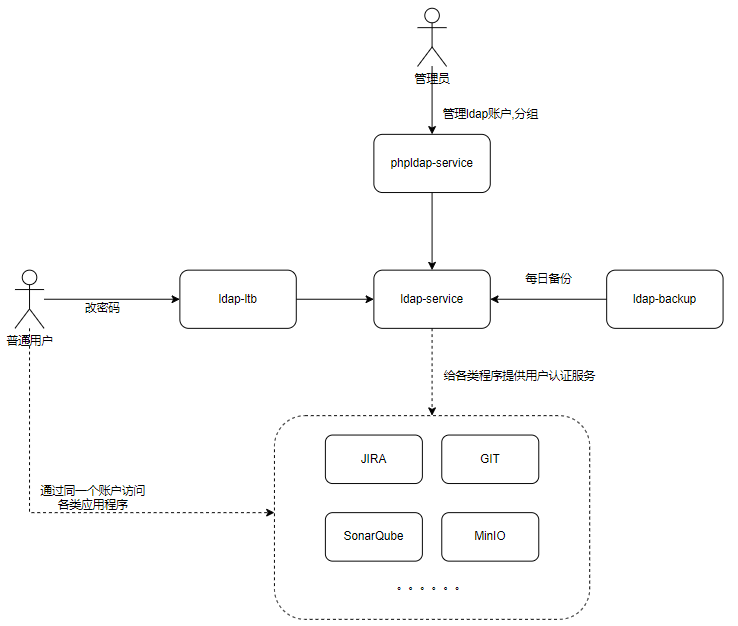
开发人员一般会用到很多开发软件,例如GIT,SonarQueb,minio,rancher等程序,这么多的程序,每个程序都有自己的一套账户系统和权限肯定是不合适的,作为用户来说,我们肯定是希望同一个账户能在多个软件中登录,就像一个微信号可以玩腾讯的所有游戏。作为管理员来说,肯定是希望前端开发,后端开发,测试人员的权限是分开的,在一个地方修改,所有软件的权限都能同步变更。那我们就采用了ldap的方式来快速部署试试吧。
我们经常会用一些诸如emqx,nats等第三方中间件,这些中间件往往默认时区就是UTC时区,这其实也没关系,但是打印出来的日志,就会与我们的上海时区差8小时,为了解决这个问题,我的简单解决办法,就是把服务器的时区通过可读的方式挂载进去。
istio 安装1.8.2版本 skywalking安装8.1.0版本 K8S集群使用rancher安装1.19版本
ApacheIoTDB提供了三种部署方式:源码部署,二进制程序部署,Docker部署 因为我的电脑是Ubuntu的,不兼容ApacheIoTDB,所以我采用了docker方式进行部署(docker是用debian的java镜像)
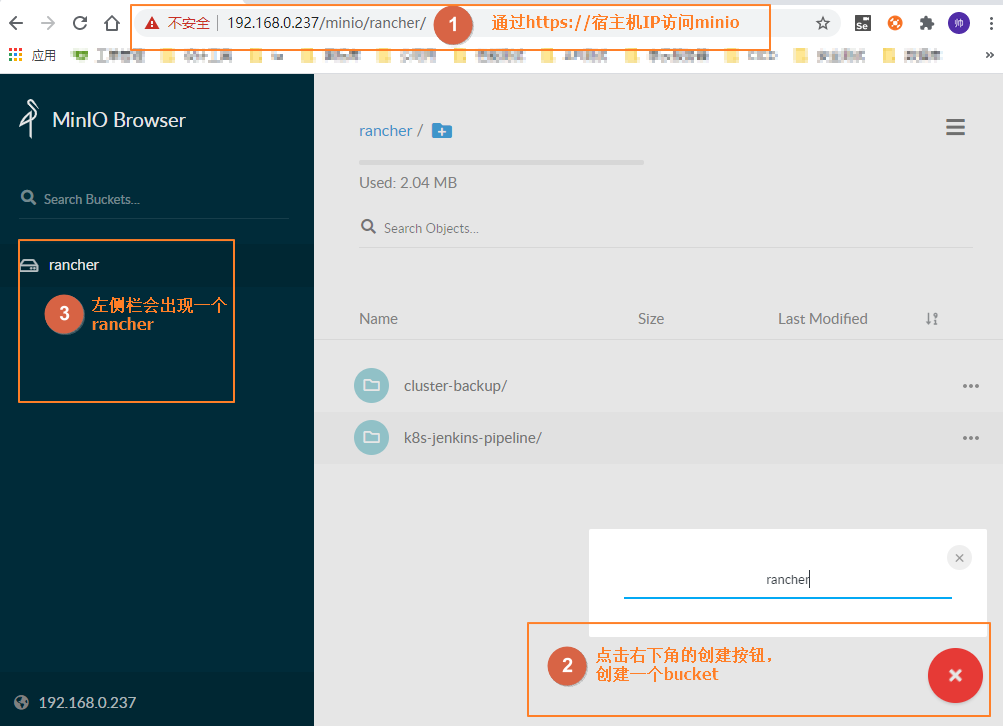
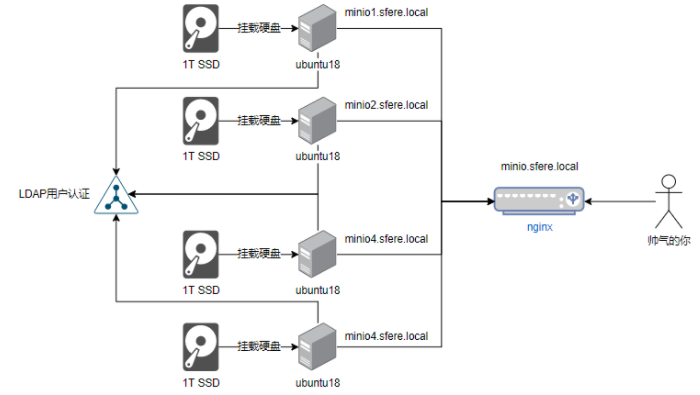
因为单机的minio无法扩充节点,无法使用版本功能,于是我们边开始使用minio的分布式版本,minio的分布式版本可以使用docker、kubernetes、裸机三种方式,这里我们使用裸机安装
因为官网的LDAP文档接入写的过于分散,实在不利于新手部署,所以重新整理了一版,方便用户能一次部署完成
最近想学习一下elasticsearch和fluentd的配合使用, fluentd比logstash节省太多资源了,所以就有了如下文章
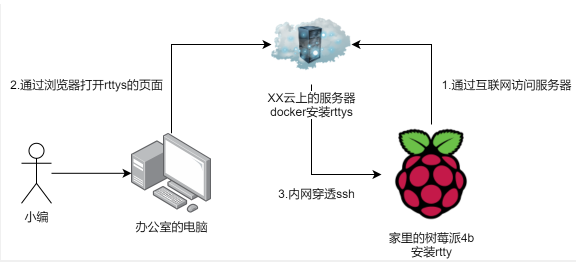
你有一个自己的外网服务器,然后捏你又买了一个树莓派放家里吃灰,有一天,你觉得不能让你的树莓派吃灰,你想上班的时候用你的树莓派在家里编译arm用的镜像程序。于是,便有了本篇文章~~~如何通过内网穿透访问你家里的树莓派。(注:仅用于测试,闹着玩,千万别上生产,上生产需要自己进行改造用户权限以及审计功能,这部分就不贴出来了) 使用的工具:docker,rtty,rttys
持续集成系统包括CI和CD。在这篇文章里,我们只讨论CI的实现。关于K8S,Jenkins,私有仓库的安装这里不进行说明,只讲解如何将这些工具组合在一起。
新版的sonarQube在扫描java代码的时候,要求sonar-project.properties里sonar.java.binaries字段必须填写。这个sonar.java.binaries是“指向包含与源文件对应的已编译字节码文件的目录”,一般来说,maven框架的话,是target/classes。 但是!问题来了,有的时候,我们的代码静态扫描是在还没有编译之前就开始的。例如我们从Jenkins的pipeline里定义了git 拉取代码,然后直接执行SonarQube analysis。并不进行编译。这样我们的Jenkins里是会报错的。那我们该如何处理呢?
在Jenkins pipeline中,一般都会用到Sonar-scanner来扫描代码,扫描完之后,把结果上传到SonarQube中,SonarQube把结果与质量阀进行对比,然后通过Sonarqube quality gate来判断这次扫描结果是成功还是失败。 不少同学都遇到过Sonarqube quality gate 获得的最后结果不正确,明明SonarQube中的结果是success,而Sonarqube quality gate判断的结果是pending。 这是怎么一回事呢?
1.读取一个已有的word文档。docx格式。 2.在该word文档中,通过一个给定的文字。找到该位置。在该位置的下方添加一个表格。例如在图中“BUG情况表”的下方插入一个表格
使用前提:ubuntu系统上已经安装好了docker环境
1.通过某种方式获得一个文件(文件夹)列表作为一个list(例如wxpython的wx.FileDialog方法,在下面的代码中我们跳过文件夹列表的获取方法)。 2.选择一个压缩文件的输出目录和压缩文件的输出名字(下面代码中选择输出默认路径为程序根目录) 3.把文件list里的文件,先统一放在一个临时文件夹里,然后把该临时文件夹压缩成ZIP文件,最后删掉临时文件夹
下面是Jira-API的详细使用的例子,包含: • Jira的登陆,通过jql批量查询jira-issue, • 获得jira-project下的所有issue,assignee的详细信息, • 添加和更新defect • 下载和上传附件 • 通过Jira登录的cookies搭配requsts库发送自定义的一些http请求
1.通过wxpython,产生一个窗体,窗体上有一段[文字标签],一个[进度条],一个[开始按钮]。 2.点击【开始按钮】,下载网络资源文件http://example.cn/test.zip。进度条和文字标签同时显示百分比 3.下载完成后,解压到指定目录。如果指定目录下有文件,则覆盖掉。
最近有这样一个需求,需要记录一下用户行为,和记下一些错误日志,放入指定文件夹里不同的文件下,方便后续debug。我决定采用python logging模块。并且使用配置文件,并做一个全局的globalLog.py来使用logging。 (关键词:logging,TimedRotatingFileHandler)
2018年做了一次influxDB测试,这里记录一下
下面几张图请按顺序观看,是作者用OWASP ZAP对某一个网站进行登录的SQL注入测试,网址和登录密码,作者已经打码了,如有侵权或引起其他不适,请联系作者
hi 各位看官,本文是截止2018年7月4日,基于python2.7开发wxpython时的打包正确用法。(2018年11月16日,发现pyinstall 3.4版本解决了这个问题了)
wxpython之tree_ctrl图标与点击事件
因为我们的electron程序已经开发完成,期望要能开发人员每次上传代码,打了tag就自动build一份deb文件,自动上传到minio,方便运维人员去拿deb文件部署到ubuntu环境上。我们已有的技术栈包含droneCI,minio,python,于是边有了该方案。本文省略了vault,ldap,minio,harbor的安装与配置,这些程序的安装配置就不一一贴出来了
前端技术日新月异,很多老哥都抱怨“学不动了”,那么“云原生”到底学不学?我的回答是,“学!”。
最近在看TDengine数据库,思考如何和我们的边缘集群结合在一起使用,本文结构是: 服务端:ubuntu18系统,通过deb文件安装TDengine数据库,主机IP 192.168.0.13,使用默认用户名密码 客户端:容器运行,python客户端,可以运行在另外一台机器或者K8S集群里 图形化工具:使用Dbeaver添加jdbc驱动,在图形化工具里使用TDengine
最近遇到一个奇葩的事,行政那边说,让估算一下明年的这些杂七杂八费,然后给了我一个excel,里面有200多个这样的费用。我没做过行政,也搞不清这个到底咋来,为什么要弄这玩意。一番交流,原来是上头要的,不一定看,但是东西得有,让我弄个数字和去年差不多的就行。于是变有了下面的故事
python-docx是一个python的读写word的库,可以用来读写word文档,向word文档里插入表格,但是与pyinstaller不是原生兼容,需要小改一下
读取excel里的表格里的内容,然后打开本机的outlook。把excel里的内容添加到正文里,注意。这里是要添加到正文!正文!正文!而不是添加到附件里
假定有如主图相同的http请求。我们一般的做法是,用postman去抓取http请求,然后修改request的body或者header里的数据,点击send按钮,检查返回的response的body是否正确。 对于输入。一般来说,我们会纯手工,或者半自动的,设计测试用例。例如使用边界值分析,等价类划分等方法,用在我们的输入参数中。比如我参数中的configname最多200个参数,我测试输入201个参数。 对于输出。一般来说,我们大部分时候是肉眼检查,或者写代码,通过jsonpath取参数,然后判断是否存在来检查。 这里我打算用一个新的方法来降低测试的手工特性,让他更自动化一点
小程序后台用的sqllite数据库,刚开始用的时候,没有考虑多线程,而且当时因为数据量少,没有出现过多线程查询报错,现在数据量大了。多线程查询经常报错 ProgrammingError: Recursive use of cursors not allowed. 就是这个头疼的错。在网上查了大量的资料,要么就是加lock=threading.lock(),要么就是加sleep.终究还是解决不了问题。 刚好最近在网上看了一个小哥哥用Queue来解决这个问题。我改进了一下。目前能够使用该方法进行增删改查。查询出来的结果以字典的形式返回。
最近公司上了pulsar服务,然后我们需要学习pulsar相关的内容。最好的办法就是自己学习pulsar环境的搭建,然后搭建一个pulsar-server.并且自己建立pulsar-client的消费者和生产者,互相调用,测试连通
前段时间有这样一个需求,要读取用户的剪贴板的内容,然后把剪贴板的信息复制到另一个地方。例如: 1.当用户复制的是图片时,把图片复制到一个指定位置。 2.当用户复制的是txt中的一段文字时,获得复制的文字内容。 3.当用户复制的是一个文件时,获得复制的文件名和路径,然后复制到一个指定位置。
最近想做一个简单的pytest 测试,用allure出报告,结果发现网上的方法都是在windows上装jenkins,然后用jenkins跑一个本地的运行环境。这种做法明显很不2021年。于是我决定做一个在jenkins上使用docker运行pytest,然后再出allure报告的文章。
python做自动化测试的时候,经常要检查复杂嵌套json,文章内容为解决方案
SonarQube的ldap配置
Jenkins我们已经集成了sonarqube,并且通过sonarqube的gate能获取到结果,并且告知Jenkins是成功还是失败。但是这样还不够,我们需要限制队友向主分支提交代码。我们锁住了master分支,队友只能通过在gitea中向master分支提交pull-request并且通过了sonarqube的代码质量检查,我们才允许合并进主分支。我们急需要一个评论功能,告知我们,这次的合并请求是否允许合并
1.我们的代码编译需要用到gradle6.2版本,jdk13版本,docker in docker策略 2.因为是在CI环境中使用,所以gradle容器会因为流水线的触发,不停的启动和删除。下载jar包会非常消耗时间,我们需要持久化这些gradle缓存。 3.挂载这些gradle缓存文件到机器上,可以用ceph集群和NFS,这里我偷懒,先用NFS做,后期资源充足再换成ceph。 4.因为我们有并行流水线的可能,所以gradle容器可能一次不止一个,而gradle的caches一次只能被一个进程占用,为了避免多容器占用同一个gradle的caches,我们需要有策略。
我们有时候会有删除节点,再重新加入master节点的需求,比如master机器改名。这里注意重新加入时,经常会出现etcd报错,这个时候就需要去还没有停止的master节点里的etcd的pod里去,删除该老master节点对应的etcd信息。
因为要想做这个流量比对,那得有前端代码,后端代码,nginx,测试同学想要熟悉diffy的功能,需要有修改前后端代码的能力,我们的AIMP项目部署起来相对复杂,所以我编写了一个小项目,用于同学们测试。
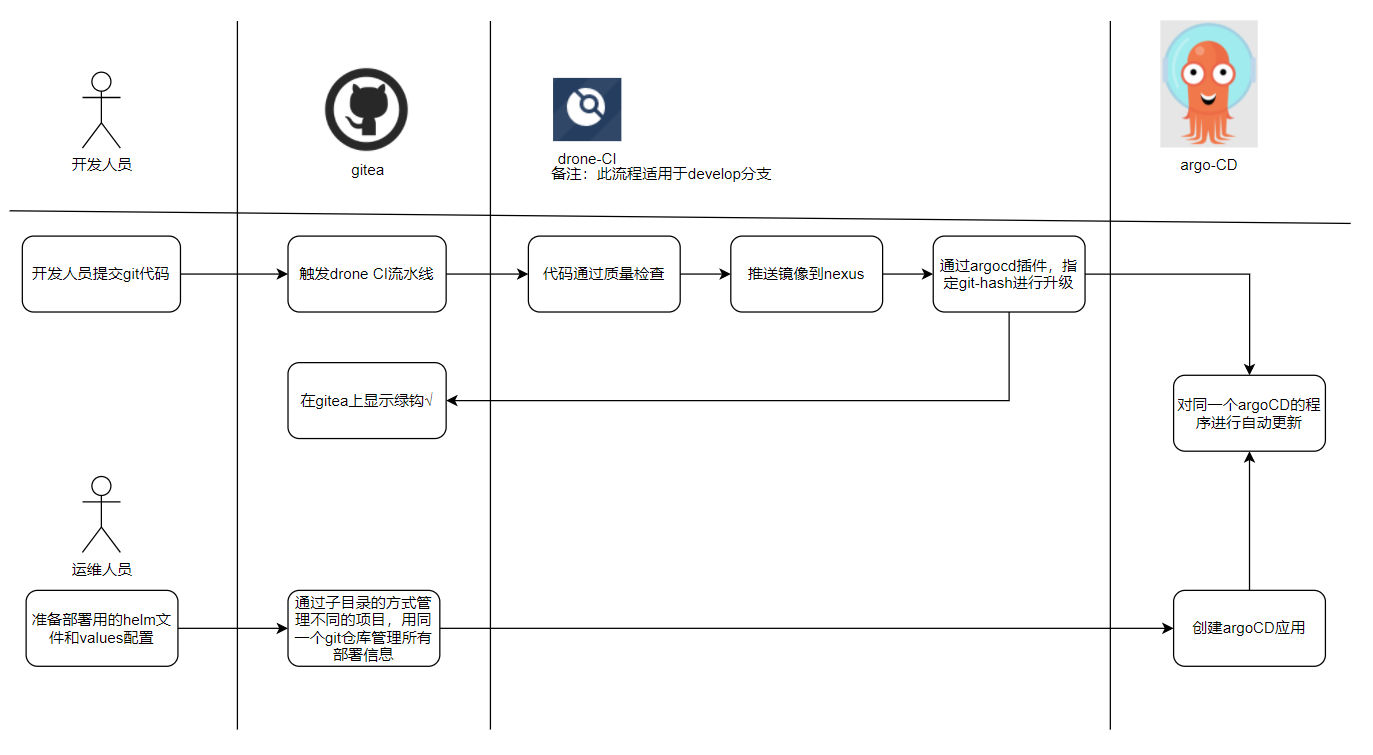
有不少朋友跟我说,helm更新statefullset或者deployment时,使用latest镜像,无法更新,其实这个问题很好解决的,可以使用git-hash来解决,也可以使用我们本篇文章里的办法,添加环境变量来解决
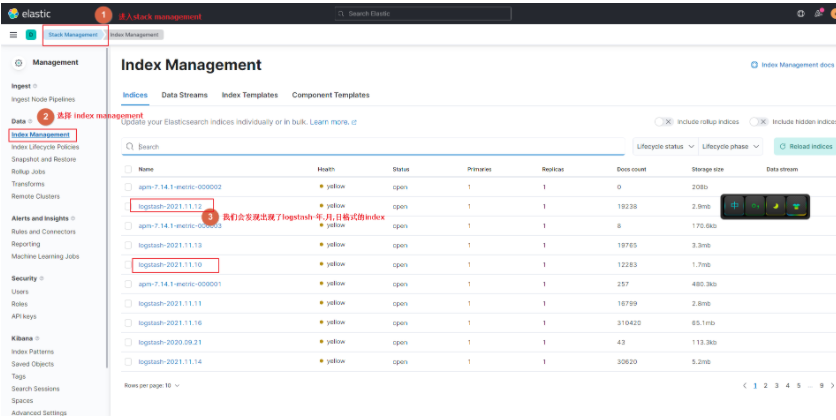
网上有很多的【假】logstash动态生成index的文章,看了很多,根本不符合我的需求,所以我决定来一篇干货,真正的解决问题。人狠话不多,代码直接上。我是使用官方提供的helm包进行ELK安装的
记录我是如何把rsyslog做成docker镜像,获取nginx的accesslog并且转发到python的
通过sidecar方法进行接入,与提供日志的容器部署在同一个pod里,主要是配置statefulset里的containers和configmap里的filebeat.yaml 1.把nginx的日志文件挂载在access_log这个volume里,同时在filebeat这个pod里也挂载access_log这个volume 2.filebeat通过subpath的方法挂载单独一个filebeat.yml到/usr/share/filebeat/filebeat.yml。注意,如果不用subpath挂载单个文件的话,是会覆盖掉/usr/share/filebeat/目录的 3.configm
开发语言:golang 目的:并发10000个mqtt连接,循环发送publish信息,当时间戳小于某个值的时候,中止循环,退出连接 publish内容是json格式的,未设置时,有默认值,可以通过golang代码修改json内容 登录信息存取在csv文件中,csv文件有多少列,就并发多少个设备连接
 发表了文章
2022-05-25
发表了文章
2022-03-14
发表了文章
2022-01-24
发表了文章
2022-01-07
发表了文章
2021-12-17
发表了文章
2021-12-15
发表了文章
2021-12-15
发表了文章
2021-12-14
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2022-05-25
发表了文章
2022-03-14
发表了文章
2022-01-24
发表了文章
2022-01-07
发表了文章
2021-12-17
发表了文章
2021-12-15
发表了文章
2021-12-15
发表了文章
2021-12-14
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10
发表了文章
2021-12-10