能力说明:
精通JVM运行机制,包括类生命、内存模型、垃圾回收及JVM常见参数;能够熟练使用Runnable接口创建线程和使用ExecutorService并发执行任务、识别潜在的死锁线程问题;能够使用Synchronized关键字和atomic包控制线程的执行顺序,使用并行Fork/Join框架;能过开发使用原始版本函数式接口的代码。
能力说明:
通过课程学习与实战项目,熟练掌握Python的语法知识与编程技能,具备Python语言的函数、面向对象、异常处理等能力,常用开发框架的实际应用和开发能力,具备使用,掌握Python数据分析三剑客Matplotlib、Numpy、Pandas的概念与应用场景,掌握利用Python语言从数据采集到分析的全流程相关知识。
 弹性计算Clouder认证:ECS快速入门
弹性计算Clouder认证:ECS快速入门
软件工程专业
LeetCode每日一道一周小结49
LeetCode每日一道一周小结48
LeetCode每日一道一周小结47
LeetCode每日一道一周小结45
LeetCode每日一道一周小结44
LeetCode每日一道一周小结43
LeetCode每日一道一周小结42
LeetCode每日一道一周小结40
数据库1
LeetCode每日一道一周小结37
LeetCode每日一道一周小结36
LeetCode每日一道一周小结33
LeetCode每日一道一周小结31
LeetCode每日一道一周小结30
LeetCode每日一道一周小结29
LeetCode每日一道一周小结28
LeetCode每日一道一周小结27
LeetCode每日一道一周小结26
LeetCode每日一道一周小结25
在数字化时代背景下,图书馆已经成为知识获取和共享的重要场所。然而,随着馆藏书籍数量的增加,如何高效管理和利用这些资源成为了图书馆管理者和用户面临的挑战。数据分析和可视化技术的引入为解决这一问题提供了新的途径。本文致力于通过数据分析技术和可视化手段,对图书馆书籍数据进行综合挖掘,希望通过图书分类、书籍价格及读者偏好等多维度信息,进而优化图书馆管理策略、指导书籍采购决策并提升读者服务质量。本文在数字化和信息化快速发展的背景下,图书馆如何利用数据分析与可视化方法来挖掘和优化书籍借阅数据。主要内容包括。
LeetCode每日一道一周小结24
LeetCode每日一道一周小结23
k均值聚类模型多元线性回归模型随机森林模型在数据分析项目中,选择合适的模型是至关重要的。本项目中,我们采用了三种不同的模型来分析蓝莓的生长条件和产量,以确保从不同角度全面理解数据。一、K均值聚类模型K均值聚类模型是一种无监督学习方法,用于根据数据的相似性将样本分成不同的组。在这个项目中,我们使用K均值聚类模型来识别具有相似特征的蓝莓品种。通过聚类分析,我们将蓝莓分为4个类别,每个类别代表了不同的生长条件和产量特性。这种分类有助于我们理解在不同环境条件下,哪些因素对蓝莓产量有显著影响。
k均值聚类模型多元线性回归模型随机森林模型在数据分析项目中,选择合适的模型是至关重要的。本项目中,我们采用了三种不同的模型来分析蓝莓的生长条件和产量,以确保从不同角度全面理解数据。一、K均值聚类模型K均值聚类模型是一种无监督学习方法,用于根据数据的相似性将样本分成不同的组。在这个项目中,我们使用K均值聚类模型来识别具有相似特征的蓝莓品种。通过聚类分析,我们将蓝莓分为4个类别,每个类别代表了不同的生长条件和产量特性。这种分类有助于我们理解在不同环境条件下,哪些因素对蓝莓产量有显著影响。
社区参与对于大模型的发展和改进至关重要,而开源大模型和闭源大模型在这方面有着显著的差异。开源大模型通常能够吸引更广泛的社区参与和贡献,因为其代码和算法是公开可见的,任何人都可以参与到模型的开发和改进中来。相反,闭源大模型的工作原理通常是封闭的,用户无法直接审查其内部代码和算法。因此,开源大模型在社区参与方面具有明显的优势,能够吸引更多的人才和资源参与到模型的开发和改进中来,从而推动整个行业的发展。相比之下,闭源大模型的社区参与通常较少,因为其代码和算法是封闭的,外部人员无法直接参与到模型的开发和改进中来。
为说明数据可视化在图书馆的应用实践,以CNKI期刊数据库收录的期刊论文为研究对象,运用Excel 2016数据统计软件和VOSviewer1.6 . 19等可视化分析软件。将数据可视化在图书馆应用的研究成果分为4个阶段对研究热点和趋势进行可视化分析。图书馆行业数据可视化应用的研究重点逐渐从数据分析转向数据服务。随着社交媒体的广泛使用,图书馆比以往更加重视用户数据素养的培养、知识服务的数字化、信息一目了然的可视化、数字人文的研究等。
LeetCode每日一道一周小结22
LeetCode每日一道一周小结21
LeetCode每日一道一周小结20
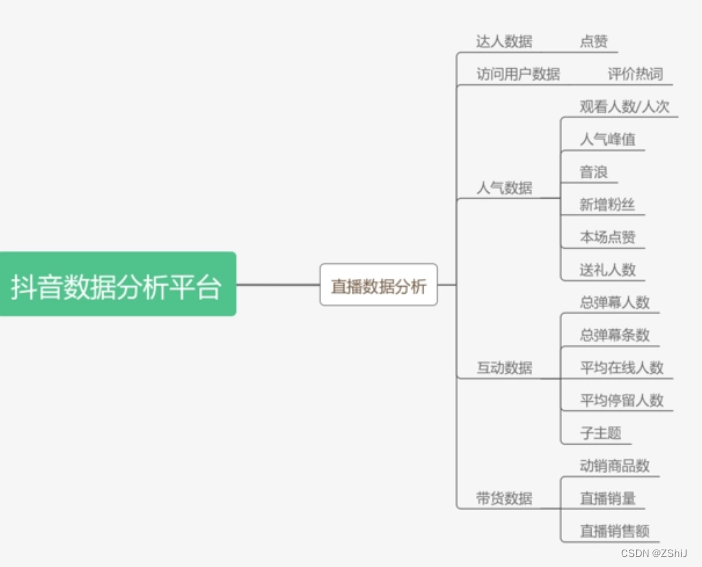
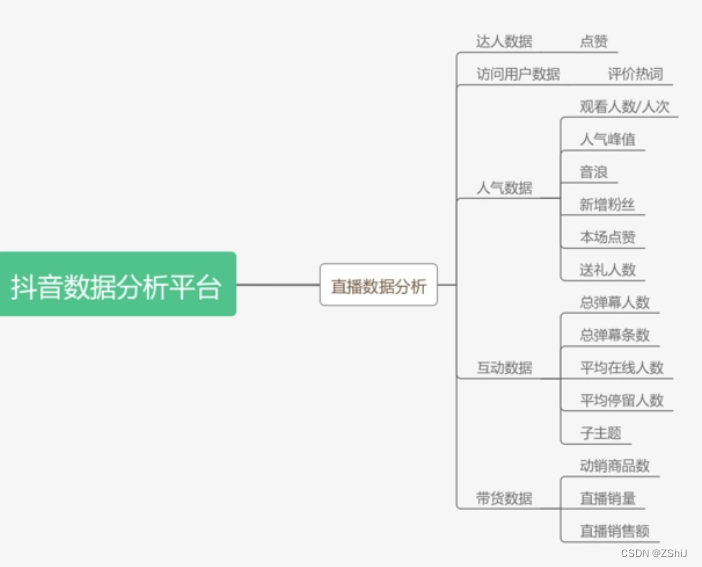
基于Flask的岗位就业可视化系统(一)
泰坦尼克号乘客生存情况预测分析1
实习僧网站的实习岗位信息分析(下)
机器学习 —— 数据分析与图表绘制
机器学习 —— 分类预测与集成学习(下)
图书馆信息管理系统(总)(中)
【题解】—— LeetCode一周小结13
图书馆信息管理系统(项目需求和计划、项目设计)(下)
【题解】—— LeetCode一周小结11
程序设计基础课程设计 —— 疫苗预约管理系统
深度学习中的大模型「幻觉」问题:解析、原因及未来展望
【题解】—— LeetCode一周小结5
Java与前端:揭开技术浪潮背后的真相
计算机网络 第八章 局域网(习题)
【Python】—— pandas 数据分析
【Python】—— matplotlib数据可视化
【Python】—— Pandas 初体验(二)
python自动化测试实战 —— 单元测试框架
开源vs闭源,大模型的未来在哪一边?
【如何学习python自动化测试】—— 浏览器驱动的安装 以及 如何更新driver
【操作系统原理】—— Linux内存管理
 发表了文章
2024-12-08
发表了文章
2024-12-08
发表了文章
2024-12-08
发表了文章
2024-12-08
发表了文章
2024-11-11
发表了文章
2024-11-05
发表了文章
2024-10-27
发表了文章
2024-10-20
发表了文章
2024-10-17
发表了文章
2024-10-06
发表了文章
2024-09-29
发表了文章
2024-09-22
发表了文章
2024-09-22
发表了文章
2024-09-22
发表了文章
2024-09-15
发表了文章
2024-09-10
发表了文章
2024-09-02
发表了文章
2024-08-26
发表了文章
2024-08-18
发表了文章
2024-08-18
发表了文章
2024-12-08
发表了文章
2024-12-08
发表了文章
2024-12-08
发表了文章
2024-12-08
发表了文章
2024-11-11
发表了文章
2024-11-05
发表了文章
2024-10-27
发表了文章
2024-10-20
发表了文章
2024-10-17
发表了文章
2024-10-06
发表了文章
2024-09-29
发表了文章
2024-09-22
发表了文章
2024-09-22
发表了文章
2024-09-22
发表了文章
2024-09-15
发表了文章
2024-09-10
发表了文章
2024-09-02
发表了文章
2024-08-26
发表了文章
2024-08-18
发表了文章
2024-08-18