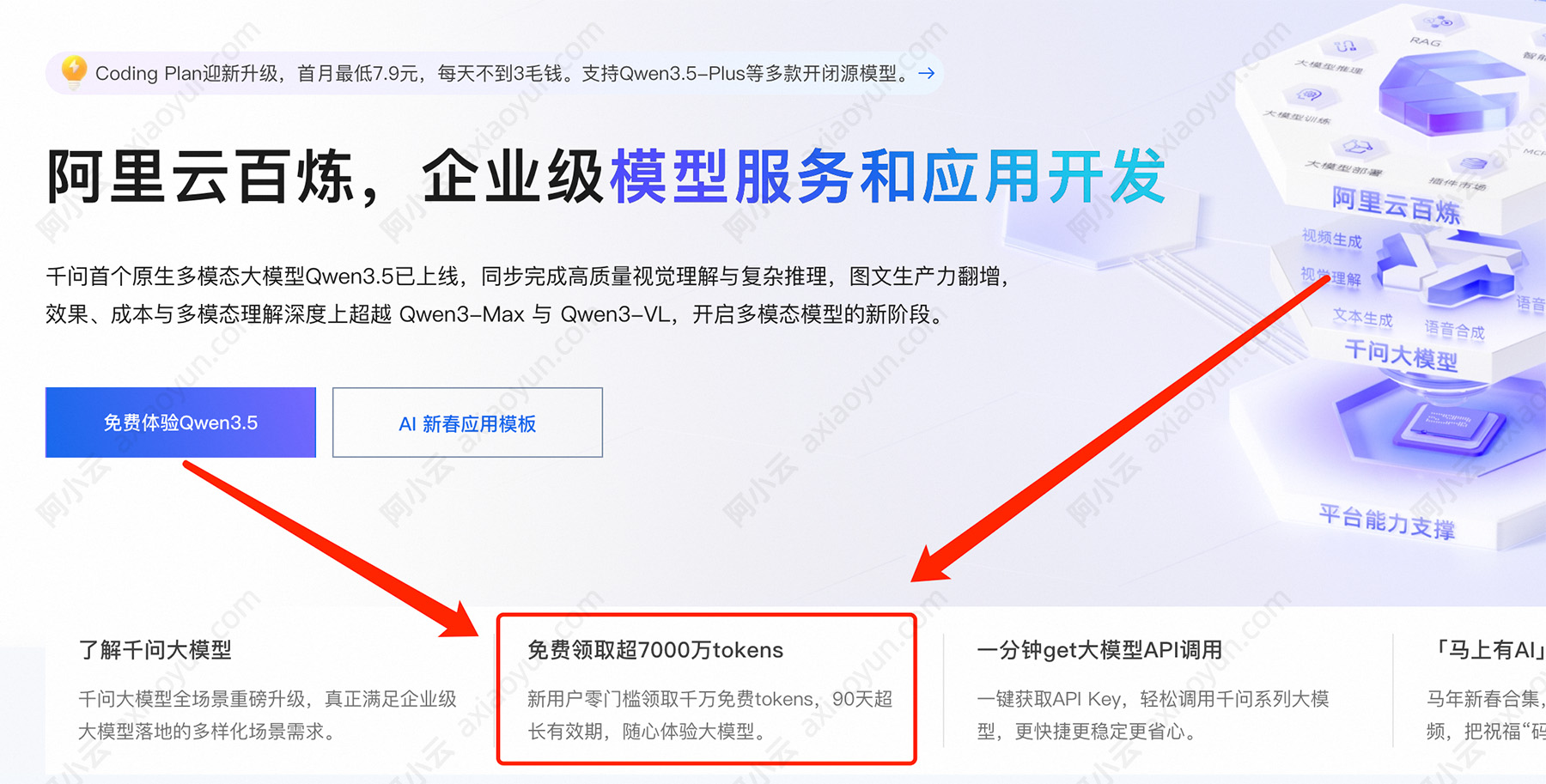
Qwen3.7-Max 的预训练数据规模和覆盖范围是什么?阿里千问Qwen3.7-Max模型官方指南:https://t.aliyun.com/U/xMui6K 如下图:
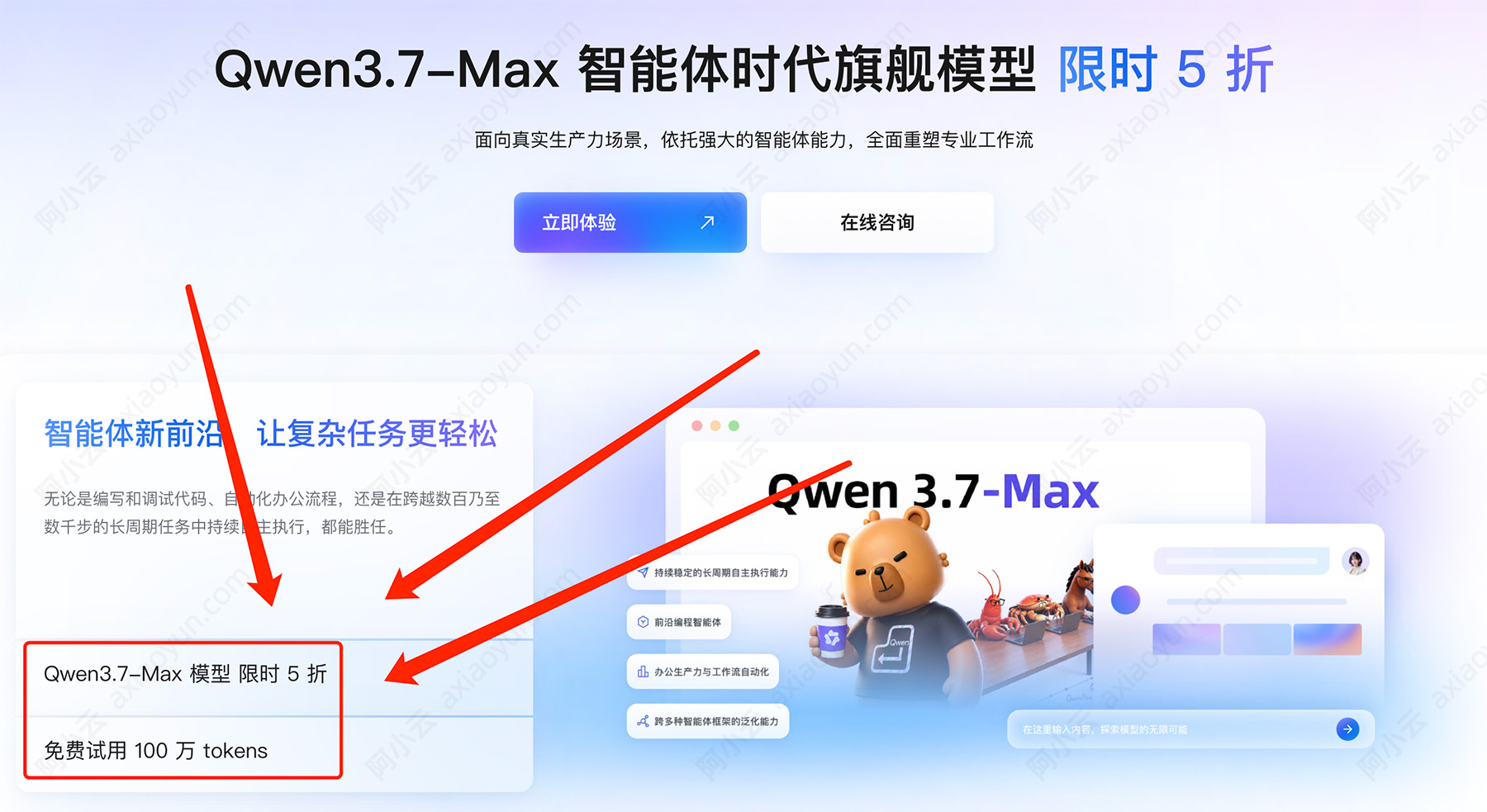
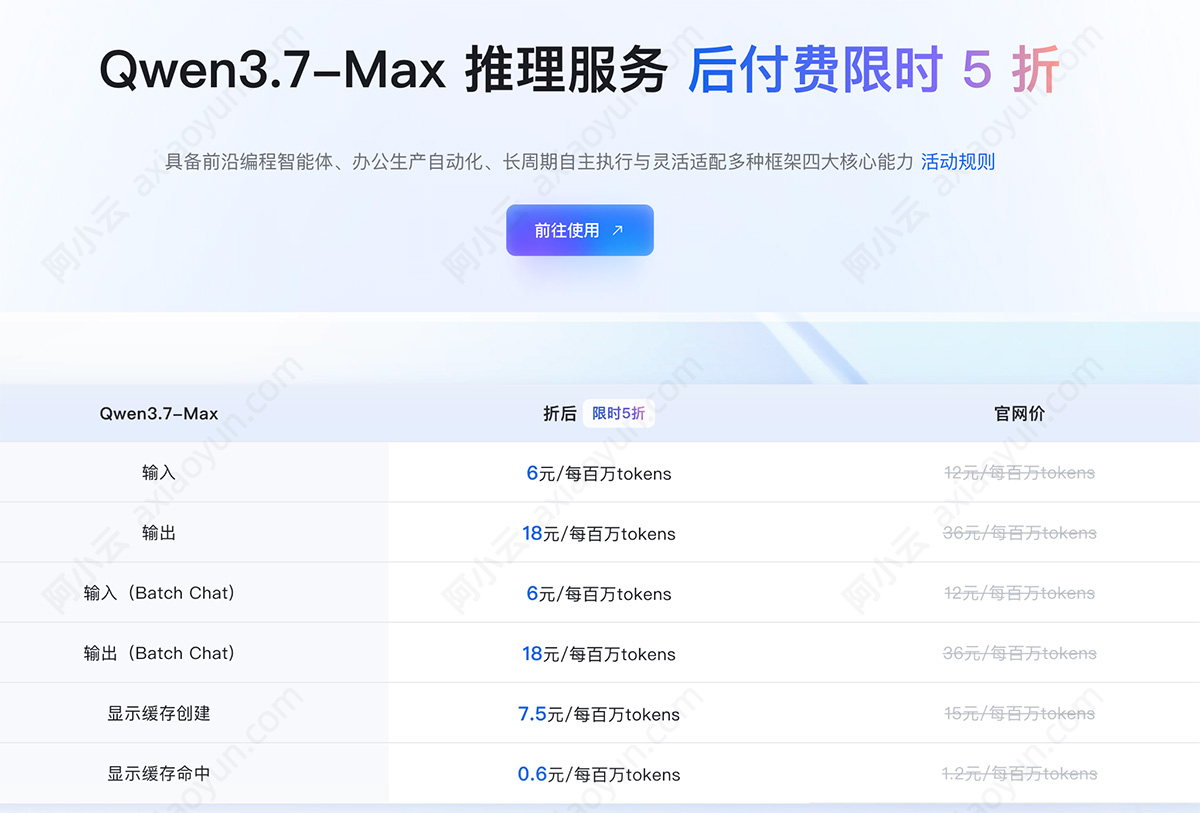
在阿里云百炼ai大模型官方平台查询精准报价信息:https://t.aliyun.com/U/fPVHqY 如下图:
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Qwen3 系列整体 在预训练阶段的数据规模累计达到约 36万亿 tokens,较前代模型提升2倍,并支持 全球119种语言。需要注意的是,该描述针对的是 Qwen3 系列,并未单独说明 Qwen3.7-Max 的具体数据细节。
阿里云百炼ai大模型平台:https://t.aliyun.com/U/fPVHqY