如何解决阿里云OpenClaw部署中的常见问题?
参考:
• 阿里云OpenClaw(Clawdbot)详细介绍及一键部署教程:https://www.aliyun.com/activity/ecs/clawdbot
• 阿里云轻量服务器:https://www.aliyun.com/product/swas
• 阿里云百炼:https://www.aliyun.com/product/bailian
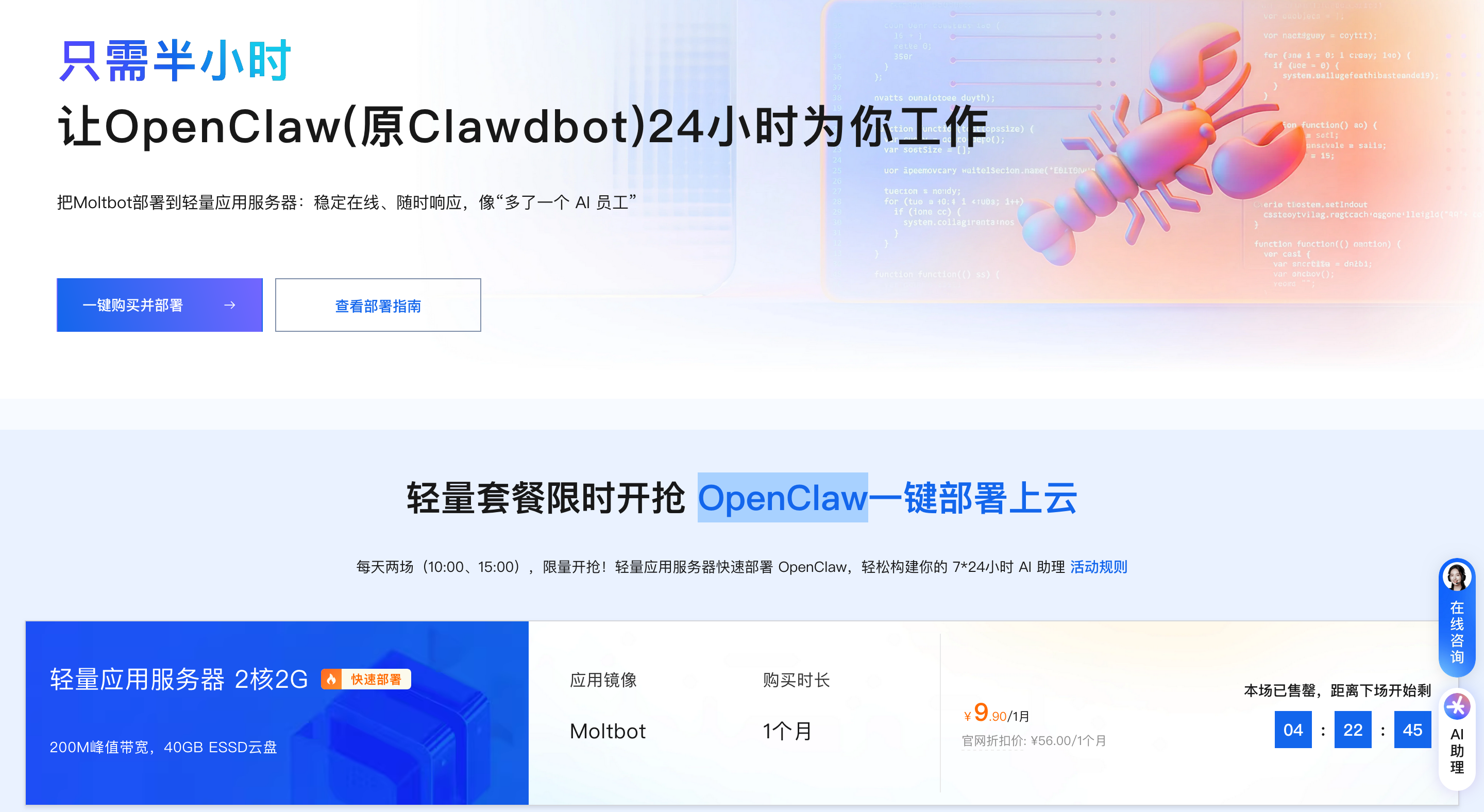
阿里云OpenClaw(原Clawdbot)部署常见问题解决指南
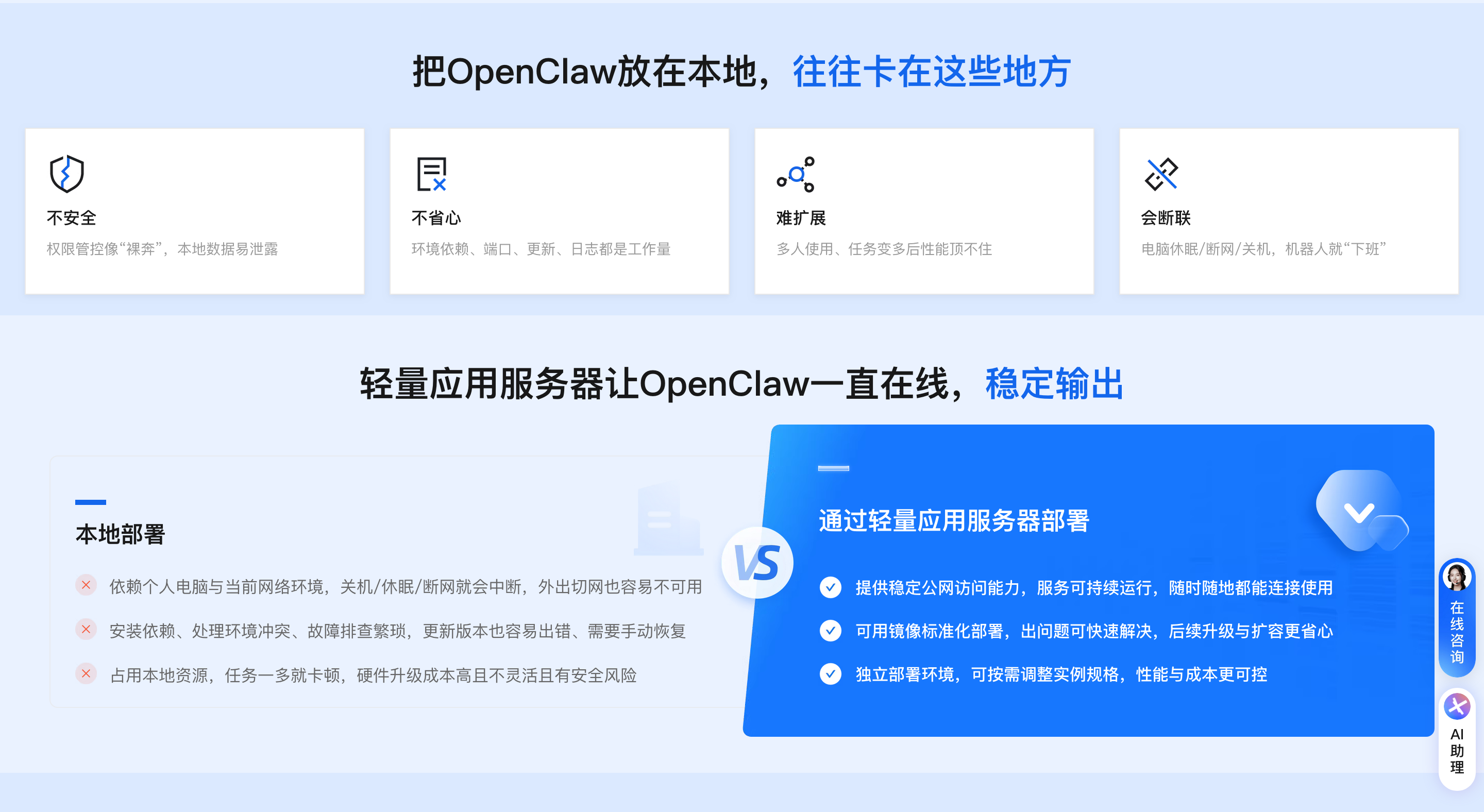
阿里云OpenClaw部署常见问题集中在部署失败、服务连接异常、模型调用失效、平台对接故障、性能瓶颈等场景,以下按问题类型提供排查步骤与解决方法,兼顾轻量应用服务器与计算巢部署环境,保障部署流程顺畅与服务稳定运行。
一、部署阶段问题及解决
(一)实例创建失败
- 常见原因:账号未实名认证、服务权限未开通、资源配置不足、地域/可用区售罄、账号欠费。
- 解决步骤
- 完成账号实名认证,开通计算巢、弹性计算、百炼大模型等服务权限,确保账号无欠费。
- 检查实例规格是否符合要求(基础2核4GB内存),更换地域/可用区,优先选择资源充足的区域。
- 若为计算巢部署,核对是否已开通对象存储等依赖服务,重新提交部署订单。
(二)环境依赖缺失/版本不兼容
- 常见原因:Node.js版本低于22、Python依赖库缺失、系统组件未安装,导致服务启动失败。
- 解决步骤
- SSH登录服务器,检查Node.js版本,低于22则升级至对应版本。
- 执行依赖安装命令,补全缺失的系统扩展与Python库,重启OpenClaw服务。
- 轻量应用服务器部署优先选择官方专属镜像,避免手动配置环境导致依赖问题。
(三)安全组/防火墙端口未放行
- 常见原因:未放行18789(核心端口)、80(回调端口),或未添加官方白名单IP。
- 解决步骤
- 云安全组添加TCP 18789、80端口入方向规则,测试阶段来源设为“0.0.0.0/0”,稳定后改为官方白名单IP(121.40.82.220、47.97.73.42等)。
- 系统防火墙(ufw/iptables)同步放行核心端口,关闭非必要端口,重启防火墙服务。
- 计算巢部署时核对实例“网络配置”,确保安全组规则正确应用。
二、服务连接与Token相关问题及解决
(一)控制界面连接超时
- 常见原因:Token错误、18789端口未放行、公网IP无法访问、服务未正常启动。
- 解决步骤
- 进入实例“应用详情”,执行命令重新生成Token,确保复制无格式错误。
- 用端口检测工具验证18789端口连通性,异常时重启服务并排查安全组/防火墙规则。
- 检查服务状态,显示“active (running)”则正常,异常时查看日志定位启动失败原因。
(二)Token认证失败
- 常见原因:Token过期、配置错误、百炼API Key无效、网关连接异常。
- 解决步骤
- 重新生成Token并更新配置,确保Token无空格、换行等格式问题。
- 核对百炼API Key有效性,重新创建并填入配置页面,启用重试机制。
- 计算巢部署时在凭据管理页面编辑OpenClaw配置,更新Token后保存测试。
三、模型调用与推理问题及解决
(一)百炼模型调用无响应
- 常见原因:API Key错误、模型权限未开通、速率限制触发、网络问题。
- 解决步骤
- 确认百炼API Key正确,开通对应模型调用权限,检查模型Code格式(如“alibaba - cloud/模型Code”)。
- 启用自适应速率限制,调整请求频率,避免触发调用上限。
- 切换地域(优先中国香港或海外),保障模型推理网络稳定。
(二)模型推理延迟高/响应异常
- 常见原因:实例规格过低、模型选择不当、缓存未启用。
- 解决步骤
- 基础版升级至4核8GB内存,复杂推理任务选择高性能实例规格。
- 轻量任务选用轻量模型,复杂任务切换至高性能模型,测试响应延迟。
- 启用本地LRU缓存与ETag校验,设置合理缓存有效期,定期清理过期缓存。
四、聊天平台对接问题及解决
(一)钉钉/飞书消息推送失败
- 常见原因:回调地址错误、App ID/App Secret配置错误、事件订阅未开启、AI卡片模板问题。
- 解决步骤
- 回调地址格式设为“公网IP:18789”,在平台开发者页面完成验证,填入正确配对码。
- 核对App ID、App Secret等参数,启用消息推送与事件订阅功能。
- 钉钉对接时重新创建AI卡片(不使用预设模板),更新模板ID并打开对应权限。
(二)机器人无响应/交互异常
- 常见原因:凭证配置错误、Token不匹配、消息防抖设置不合理。
- 解决步骤
- 在平台开发者后台更新OpenClaw凭证(正确Token)与平台凭证。
- 调整控制界面消息防抖时长,避免重复消息触发,启用上下文记忆功能提升连贯性。
- 测试群聊@机器人发送指令,确认消息传递与响应正常。
五、性能与运维问题及解决
(一)服务运行卡顿/资源占用过高
- 常见原因:实例规格不足、闲置进程过多、缓存未清理、模型推理任务过重。
- 解决步骤
- 升级实例规格(4核8GB及以上),设置CPU/内存使用上限,关闭非必要进程。
- 定期清理缓存目录,启用断点续执行功能,避免重复执行长期任务。
- 切换轻量模型处理简单任务,分流高性能模型负载。
(二)服务频繁重启/崩溃
- 常见原因:依赖库版本冲突、系统组件缺失、日志未开启、磁盘空间不足。
- 解决步骤
- 检查依赖库版本,升级至兼容版本,安装缺失的系统扩展。
- 开启服务日志,定位崩溃原因,针对性修复配置或代码问题。
- 扩展系统盘容量(建议40GB ESSD),避免磁盘满导致服务异常。
六、通用排查与优化建议
- 日志排查:启用OpenClaw与系统日志,按时间戳定位问题,重点关注启动日志、模型调用日志、网络通信日志。
- 规则备份:定期备份安全组与防火墙规则,出现配置错误时快速恢复。
- 权限管控:定期轮换API Key与Token,仅开放必要权限,避免非授权访问。
- 定期更新:更新OpenClaw版本与依赖组件,修复已知漏洞与性能问题。
总结
解决阿里云OpenClaw部署问题需遵循“先排查基础配置,再定位功能模块,最后优化性能”的逻辑,优先处理账号权限、端口放行、Token配置等基础问题,再解决模型调用与平台对接故障,结合运维优化保障服务长期稳定运行,适配个人与企业级部署场景。