以下文章由小编云枢国际撰写。
PolarDB的快速恢复体系是一个多层次的防御系统,下面我们来详细解读这套恢复体系中的关键技术和流程。
- SQL级精确恢复:SQL闪回
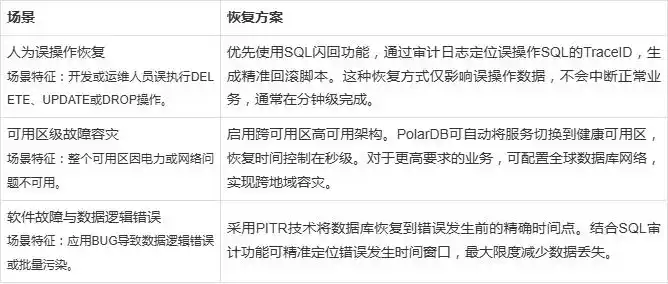
对于常见的误操作场景,PolarDB提供了SQL闪回功能,可实现精准到单条SQL的恢复。每条在PolarDB中执行的SQL都会分配唯一的TraceID,当发生误删除或误更新时,系统通过TraceID在全局Binlog中精确定位受影响的数据,并自动生成回滚SQL。这种机制避免了传统全库恢复的冗长过程,仅针对误操作涉及的数据进行恢复,大幅缩短了恢复时间。 - 存储层快速容错:多副本与自动修复
PolarDB采用基于Paxos协议的多副本架构,数据默认在多个可用区同步保留6个副本。当单个存储节点发生故障时,系统会自动从健康副本中重建数据,无需人工干预。这种设计确保了硬件故障下的数据持久性高达99.999999999%,且修复过程对应用完全透明。 - 实例级高可用:秒级故障切换
对于计算节点故障,PolarDB的高可用架构可在30秒内完成自动故障转移。通过持续的健康检测,当主节点不可用时,系统会自动将备用节点提升为主节点,确保服务连续性。这一过程基于PolarDB的分布式共识算法,保证了切换前后数据的强一致性。 - 任意时间点恢复:PITR技术
PolarDB的Point-in-Time Recovery技术结合了全量备份和Redo日志,允许将数据库恢复到过去任意秒级时间点。该功能依赖于分布式存储的快照能力,可快速创建整个数据库的一致性副本,然后应用Redo日志前滚到指定时间点,非常适合逻辑错误或数据损坏的恢复场景。
下表是典型应用场景与恢复策略