
NLP自学习平台如何在分词的时候自定义停顿词?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
选择一个支持自定义停顿词的NLP工具或平台。许多流行的NLP库,如NLTK、spaCy、HanLP等,都支持自定义停顿词。
创建一个包含你希望排除的词的列表。这个列表可以是一个新的文件,或者修改现有的停顿词文件。
import nltk
from nltk.corpus import stopwords
# 下载默认的英文停顿词集
nltk.download('stopwords')
# 加载默认的停顿词集
stop_words = set(stopwords.words('english'))
# 自定义停顿词
custom_stop_words = set(["additional", "custom", "words"])
# 合并默认和自定义的停顿词
stop_words.update(custom_stop_words)
# 使用停顿词过滤文本
text = "This is a sample sentence, and it has additional words to remove."
filtered_text = " ".join([word for word in text.split() if word.lower() not in stop_words])
print(filtered_text)
将自定义的停顿词列表集成到你的分词流程中。这可能涉及到修改分词器的配置或代码。
在实际数据上测试分词效果,根据需要调整停顿词列表。可能需要多次迭代来找到最佳的停顿词设置。
在NLP(自然语言处理)自学习平台中自定义停顿词(也称为停用词或过滤词),通常涉及以下几个步骤。这里以阿里云的NLP自学习平台为例,说明如何进行操作,尽管具体步骤可能会根据不同的平台有所差异:
登录平台:首先,登录到您的阿里云账号,并进入相应的NLP服务或自学习平台,比如阿里云的“自然语言处理”或“文本分析”服务。
选择或创建项目:在平台内,选择一个已有的项目或创建一个新的项目来存放您的自定义配置。
停用词管理:
上传停用词文件:
应用配置:
测试与调整:
请注意,不同的NLP自学习平台可能有各自独特的界面和操作流程,上述步骤仅供参考。务必参考您所使用的具体平台的官方文档或帮助中心,以获取最准确的操作指南。
在使用自然语言处理(NLP)自学习平台进行分词时,自定义停顿词可以帮助更准确地切分文本,尤其是在中文分词中,停顿词的识别对理解句子的结构非常重要。以下是一般步骤,适用于多数NLP自学习平台:
以下是一些常见的操作步骤:
以下是一个示例操作流程:
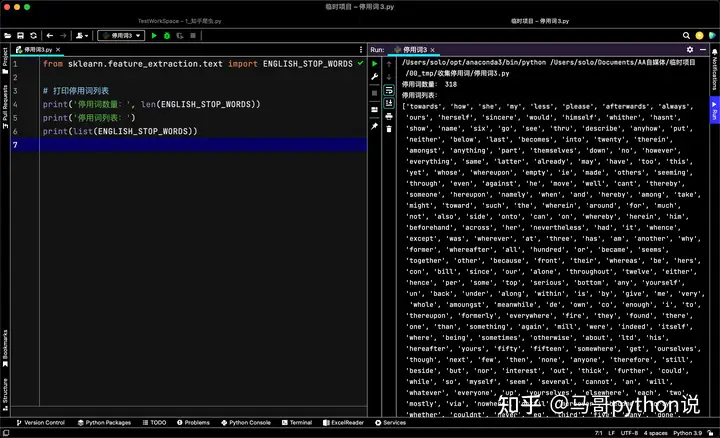
sklearn是一个用于机器学习的Python库,它包含了各种经典和先进的机器学习算法,如分类、回归、聚类、降维、特征选择、模型选择等。
其中,sklearn.feature_extraction是用于特征提取的模块,可以利用它调取停用词库,完整代码如下:
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
# 打印停用词列表
print('停用词数量:', len(ENGLISH_STOP_WORDS))
print('停用词列表:')
print(list(ENGLISH_STOP_WORDS))
——参考链接。
使用工具: 联网搜索
在NLP自学习平台中自定义分词时的停顿词,可以通过以下步骤实现:
准备自定义的停顿词列表:你需要准备一个包含你想要作为停顿词的词汇列表。这些词汇应该是那些在文本分析过程中通常不需要被分割或处理的词,比如常见的标点符号、连词等。
导入必要的库:使用Python进行自然语言处理时,可以利用nltk(Natural Language Toolkit)这样的工具包来辅助处理。例如,通过from nltk.corpus import stopwords可以导入停用词表。
创建自定义停顿词集合:将你的停顿词列表转换成一个Python集合或列表,以便于后续的处理。例如,可以将自定义的停顿词与nltk提供的英文停用词列表合并,创建一个更完整的停顿词集合。
应用到分词工具中:在使用分词工具如jieba、StanfordNLP或其他NLP工具时,根据具体工具的API文档,设置或传入你自定义的停顿词集合。这样,在进行分词操作时,这些工具会将这些自定义的停顿词视为非目标词汇,不会对其进行分割处理。
调整和优化:根据实际的分词效果,可能需要对自定义的停顿词列表进行调整和优化。这包括添加遗漏的停顿词、移除不再需要的停顿词,或是调整停顿词的优先级等。
总的来说,通过上述步骤,你可以在NLP自学习平台中自定义分词时的停顿词,从而更好地控制文本分析和处理的过程。
在自然语言处理(NLP)中,分词是文本预处理的重要步骤之一。自定义停顿词(停用词)可以帮助改善文本分析的质量和效率。下面是一些关于如何在分词时自定义停顿词的方法和步骤:
使用NLTK库
导入停用词表:NLTK库提供了多种语言的停用词表,可以通过nltk.corpus.stopwords模块导入相应的停用词表。例如,要导入英文停用词表,可以使用以下代码:
python
复制代码
from nltk.corpus import stopwords
FILTERWORD = stopwords.words('english')
构造中文停用词表:由于NLTK库只支持英文的停用词库,因此在进行中文分词的时候还需要构造中文的停用词词库。可以通过读取本地文件的方式导入中文停用词表。例如:
python
复制代码
with open('hit_stopwords.txt', 'r') as f:
stopwords_list = f.readlines()
stopwords_list = [i.strip() for i in stopwords_list]
添加自定义符号:除了停用词,还可以添加一些自定义的符号到停用词表中。例如:
python
复制代码
punctuations = [',', '.', ':', ';', '?', '(', ')', '[', ']', '&', '!', '*', '@', '#', '$', '%', "''", '\'', '`', '``', '-', '--', '|', '\/']
FILTERWORD.extend(punctuations)
使用jieba库
设置停用词:jieba是一个常用的中文分词库,可以方便地设置停用词。首先,将停用词存入一个文件,如stopwords.txt,然后通过jieba.analyse.set_stop_words方法设置停用词。例如:
python
复制代码
jieba.analyse.set_stop_words('stopwords.txt')
提取高频词:在使用jieba.analyse提取高频词时,已经设置的停用词会自动过滤掉。
自定义分词器
训练句子标记器:对于某些类型的文本,可能需要训练一个自定义的句子标记器来处理非标准的标点符号或独特的格式。可以使用PunktSentenceTokenizer来训练句子标记器
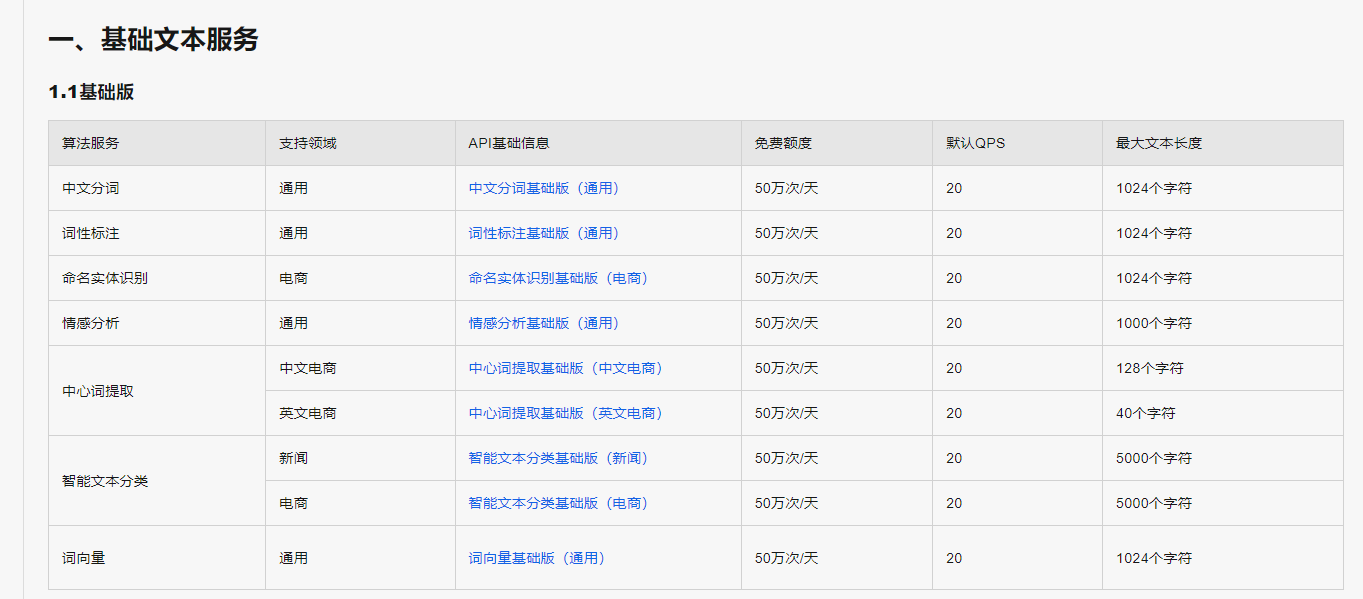
收集停用词:
可以从公开的停用词库中获取,如中文停用词表、哈工大停用词表、百度停用词表等。
也可以根据自己的需求手动添加或删除停用词。
创建停用词表:
将收集到的停用词整理成一个列表或文件,确保每个停用词都单独一行或以某种分隔符分隔。
导入停用词表:
在NLP平台的设置或配置选项中,找到分词相关的设置。
将准备好的停用词表导入到平台中,通常可以通过上传文件或手动输入的方式完成。
启用自定义停用词:
在分词设置中,启用自定义停用词功能。
确保平台在分词时会参考并应用你提供的停用词表。
在NLP自学习平台中,自定义停用词通常是在进行文本预处理时的一个重要步骤。停用词是指在信息检索中通常被过滤掉的词,如“的”、“是”、“和”等常见词汇。要自定义停用词列表,首先需要创建一个包含停用词的文件或列表,然后在分词阶段加载这个列表,并对分词结果进行过滤。具体实现可以是在代码中添加如下逻辑:
读取自定义的停用词列表。
在分词后检查每个词语是否在停用词列表中。
如果词语属于停用词,则从分词结果中移除该词。
使用Python和jieba分词库为例,可以这样实现: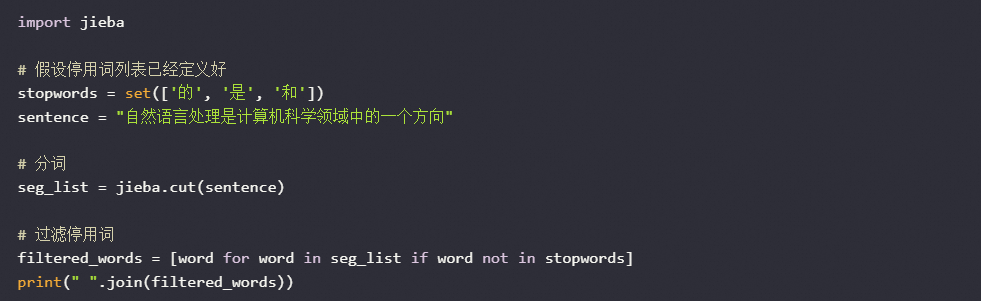
这种方法可以帮助模型减少噪声,提高后续任务如情感分析、主题建模等的效果。
在自然语言处理(NLP)中,分词是将文本切分成有意义的词汇单位的过程。停用词(或停顿词)是指那些在文本中频繁出现但对理解文本内容帮助不大的词,例如“的”、“了”、“和”等。自定义停用词可以帮助提高分词的质量和后续处理的效果。
如果你使用的是一个自学习平台来进行分词,并且希望自定义停用词,以下是一些常见的方法和步骤:
首先,确定你使用的 NLP 库或工具。常见的中文分词工具有:

创建一个包含你希望去除的停用词的文件。通常,这个文件是一个纯文本文件,每行一个停用词。例如:
的
了
和
是
在
根据你使用的 NLP 工具,加载停用词列表的方法会有所不同。以下是几个常见工具的示例:
import jieba
# 读取停用词列表
with open('stopwords.txt', 'r', encoding='utf-8') as f:
stopwords = set(f.read().splitlines())
# 分词并去除停用词
def segment_text(text):
words = jieba.lcut(text)
return [word for word in words if word not in stopwords]
text = "这是一个测试句子,用于演示如何使用自定义停用词进行分词。"
result = segment_text(text)
print(result)
from pyhanlp import *
import os
# 读取停用词列表
with open('stopwords.txt', 'r', encoding='utf-8') as f:
stopwords = set(f.read().splitlines())
# 分词并去除停用词
def segment_text(text):
words = list(HanLP.segment(text))
return [word.word for word in words if word.word not in stopwords]
text = "这是一个测试句子,用于演示如何使用自定义停用词进行分词。"
result = segment_text(text)
print(result)
import thulac
# 读取停用词列表
with open('stopwords.txt', 'r', encoding='utf-8') as f:
stopwords = set(f.read().splitlines())
# 初始化 THULAC 分词器
thu = thulac.thulac()
# 分词并去除停用词
def segment_text(text):
words = thu.cut(text, text=True).split()
return [word for word in words if word not in stopwords]
text = "这是一个测试句子,用于演示如何使用自定义停用词进行分词。"
result = segment_text(text)
print(result)
如果你使用的是一个特定的自学习平台(如阿里云、百度 AI 平台等),这些平台通常提供了 API 或者界面来配置分词参数。你需要查阅该平台的文档,找到关于自定义停用词的设置选项。
例如,在阿里云的 NLP 自学习平台上,你可能需要上传停用词文件并通过 API 或控制台进行配置。具体步骤可以参考平台的官方文档。
在配置好自定义停用词后,进行一些测试以确保分词结果符合预期。检查分词后的文本是否正确去除了停用词,并且保留了重要的词汇。
通过以上步骤,你可以成功地在 NLP 自学习平台上自定义停用词,从而提高分词的质量和后续处理的效果。


