在大数据计算MaxCompute中使用pyODPS读取文件,再写入 ODPS,需要指定列名吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
写入数据到MaxCompute表中时,你需要确保数据的列与表中的列结构相匹配。如果写入的数据文件(如CSV)的第一行包含列名,并且这些列名与MaxCompute表中的列名一致,那么不需要额外指定列名。如果不一致或者文件中没有列名,你可能需要在写入时指定列名。
以下是使用pyODPS读取文件并写入MaxCompute表的基本步骤:
安装pyODPS:
首先,确保你已经安装了pyODPS库。
pip install pyodps
配置访问信息:
配置你的MaxCompute项目和访问密钥。
from odps import ODPS
odps = ODPS('your_access_id', 'your_access_key', 'your_default_project', endpoint='your_endpoint')
读取文件:
假设你有一个CSV文件存储在OSS上,并且你想要读取这个文件。
import pandas as pd
# 读取OSS上的CSV文件
df = pd.read_csv('oss://your-bucket/your-file.csv')
写入ODPS:
将Pandas DataFrame写入MaxCompute表中。如果DataFrame的列名与MaxCompute表的列名一致,你可以直接写入。
from odps.models import Schema, Field, StringType, IntegerType
# 定义表结构(如果表不存在则创建)
schema = Schema([Field('col1', IntegerType()), Field('col2', StringType())])
table_name = 'your_table_name'
if not odps.exist_table(table_name):
odps.create_table(table_name, schema)
# 写入数据
df.write格式('odps://your_default_project.your_table_name', odps=odps)
如果DataFrame的列名与MaxCompute表的列名不一致,你需要在写入时进行映射。
df.to_odps(name='your_table_name', project='your_default_project', odps=odps, if_exists='append', index=False)
在使用pyODPS读取文件并写入ODPS时,通常需要指定列名。因为在读取文件时,pyODPS会根据文件中的数据自动推断列的类型和名称。然而,在将数据写入ODPS时,你需要明确指定列名以确保数据正确地映射到目标表中的列。
以下是一个示例代码片段,展示了如何使用pyODPS读取CSV文件并将数据写入ODPS表:
python
复制代码
from odps import ODPS
access_id = 'your_access_id'
access_key = 'your_access_key'
project = 'your_project'
endpoint = 'your_endpoint'
odps = ODPS(access_id, access_key, project, endpoint)
src_table = odps.get_table('source_table')
tgt_table = odps.get_table('target_table')
with open('data.csv', 'r') as f:
data = f.readlines()
with tgt_table.open_writer() as writer:
for line in data:
# 假设CSV文件的每一行都是逗号分隔的值
values = line.strip().split(',')
# 假设列名是['col1', 'col2', 'col3']
record = {'col1': values[0], 'col2': values[1], 'col3': values[2]}
writer.write(record)
在上面的示例中,我们首先创建了一个ODPS客户端对象,然后获取了源表和目标表的对象。接下来,我们打开一个CSV文件并逐行读取数据。对于每一行数据,我们将其拆分为值列表,然后将这些值与指定的列名一起组成一个字典。最后,我们使用write方法将记录写入目标表。
请注意,上述示例中的列名(col1, col2, col3)应该根据你的实际需求进行修改。确保列名与目标表中的列名相匹配,以便正确地映射数据。
是否需要指定列名分以下三种情况:
1、如果已经在MaxCompute中创建了目标表,并且已经明确指定了列名和数据类型,那么在使用pyODPS写入数据时,不需要在代码中再次指定列名。
2、读取的文件没有表头(即没有列名),而目标表已经存在并且具有明确的列名和数据类型,那么在写入数据时,不需要在代码中指定列名。
3、在代码中动态创建表或写入数据时指定列名,那么可以通过pyODPS提供的API来实现。
在大数据计算MaxCompute中使用pyODPS读取文件,再写入ODPS时,是否需要指定列名取决于多种因素。以下是对这一问题的详细分析:
一、文件类型与格式
CSV/TXT文件:
如果文件是CSV或TXT格式,并且包含表头(即列名),那么在读取文件时,pyODPS可以自动识别这些列名,并在写入ODPS时与之对应。
如果文件没有表头,那么在读取文件后,需要在代码中手动设置列名,以便在写入ODPS时能够正确映射。
其他格式文件:
对于其他格式的文件(如JSON、Parquet等),pyODPS的读取方式可能会有所不同,但通常也需要指定列名或列的数据类型等信息。
二、ODPS表结构
已存在表:
如果ODPS中已经存在目标表,并且该表的结构(即列名和数据类型)与要写入的数据相匹配,那么在写入数据时通常不需要再次指定列名。
但是,为了确保数据的正确性和完整性,建议在写入前检查文件中的数据与ODPS表结构是否一致。
新建表:
如果需要在ODPS中新建表来存储数据,那么在创建表时必须指定列名和数据类型等信息。
在这种情况下,写入数据时也需要按照表结构来指定列名(尽管在pyODPS的某些高级用法中,可以通过映射等方式避免显式指定列名)。
三、pyODPS的使用方式
低级API:
在使用pyODPS的低级API时(如使用open_writer等方法),通常需要手动设置列名或列的数据类型等信息。
高级API或框架:
如果使用pyODPS的高级API或与其他框架(如Pandas、NumPy等)结合使用,可能会提供一些便捷的方法来自动映射列名和数据类型。
在这种情况下,是否需要显式指定列名取决于所使用的API或框架的具体实现。
四、结论
综上所述,在大数据计算MaxCompute中使用pyODPS读取文件再写入ODPS时,是否需要指定列名取决于文件类型与格式、ODPS表结构以及pyODPS的使用方式等多种因素。为了确保数据的正确性和完整性,建议在写入数据前仔细检查这些因素,并根据实际情况进行必要的设置和调整。
在具体实践中,可以参考阿里云官方文档或pyODPS的示例代码来了解更多关于如何使用pyODPS进行文件读取和写入ODPS的详细信息。
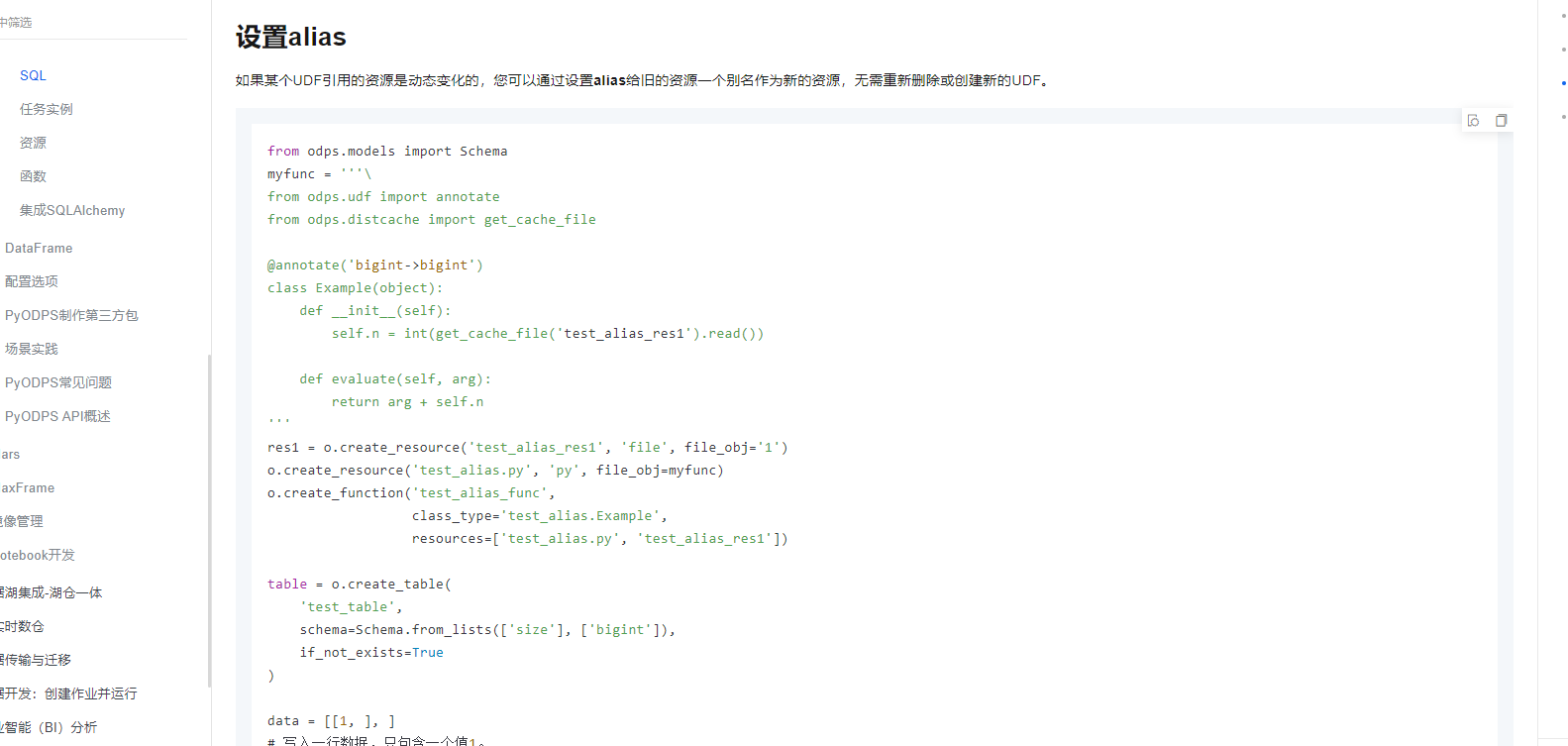
如果某个UDF引用的资源是动态变化的,您可以通过设置alias给旧的资源一个别名作为新的资源,无需重新删除或创建新的UDF。
使用PyODPS从MaxCompute表中读取数据时,是不需要显式地指定列名的。在PyODPS的ODPSRDD.read()方法读取数据时,如果表有列名,PyODPS会自动检测表结构并加载列名。同样当写入ODPS表时,如果你是写入一个带有列名和类型的DataFrame,PyODPS会根据DataFrame的结构创建或 overwrite(如果表不存在)或append到已存在的表中,无需用户手动指定列名。确保Python对象的列名和数据类型与ODPS表定义匹配。
在使用 pyODPS 读取文件并将数据写入 MaxCompute 表时,是否需要指定列名取决于你的具体需求和数据格式。以下是一些常见的情况和相应的处理方法:
如果你的文件(例如 CSV 文件)包含表头(即第一行是列名),你可以直接读取文件并将数据写入 MaxCompute 表,而不需要手动指定列名。
from odps import ODPS
from odps.df import DataFrame
# 初始化 ODPS 客户端
odps = ODPS('<your-access-id>', '<your-access-key>', '<your-project-name>', endpoint='<your-endpoint>')
# 读取 CSV 文件
df = DataFrame(odps, 'path/to/your/file.csv', delimiter=',')
# 写入 ODPS 表
df.persist('your_odps_table_name')
如果你的文件没有表头,你需要手动指定列名。你可以通过 DataFrame 的构造函数或 rename 方法来指定列名。
from odps import ODPS
from odps.df import DataFrame
# 初始化 ODPS 客户端
odps = ODPS('<your-access-id>', '<your-access-key>', '<your-project-name>', endpoint='<your-endpoint>')
# 读取 CSV 文件并指定列名
column_names = ['col1', 'col2', 'col3'] # 替换为你的实际列名
df = DataFrame(odps, 'path/to/your/file.csv', delimiter=',', names=column_names)
# 写入 ODPS 表
df.persist('your_odps_table_name')
如果你已经有一个 Pandas DataFrame,并且希望将其写入 MaxCompute 表,你同样需要确保列名与目标表的列名匹配。
import pandas as pd
from odps import ODPS
from odps.df import DataFrame
# 初始化 ODPS 客户端
odps = ODPS('<your-access-id>', '<your-access-key>', '<your-project-name>', endpoint='<your-endpoint>')
# 创建一个示例 Pandas DataFrame
data = {
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c'],
'col3': [True, False, True]
}
pandas_df = pd.DataFrame(data)
# 将 Pandas DataFrame 转换为 ODPS DataFrame
odps_df = DataFrame(pandas_df)
# 写入 ODPS 表
odps_df.persist('your_odps_table_name')
如果你的目标表是分区表,你需要在写入时指定分区信息。
from odps import ODPS
from odps.df import DataFrame
# 初始化 ODPS 客户端
odps = ODPS('<your-access-id>', '<your-access-key>', '<your-project-name>', endpoint='<your-endpoint>')
# 读取 CSV 文件
df = DataFrame(odps, 'path/to/your/file.csv', delimiter=',')
# 写入分区表
partition_spec = 'pt=20231014' # 替换为你的实际分区
df.persist('your_odps_partitioned_table_name', partition=partition_spec)
通过以上方法,你可以根据具体情况灵活地将文件数据写入 MaxCompute 表中。确保列名和数据类型的匹配是关键步骤,以避免写入失败。
在使用 MaxCompute(阿里云的大数据计算平台)时,通过 pyODPS(Python SDK for ODPS)读取文件再写入 MaxCompute 表,通常需要指定列名,特别是在写入操作中,因为 MaxCompute 表是结构化的,需要定义好表的模式(schema),即列名及其对应的数据类型。
首先需要确保安装了 pyODPS 库。你可以使用 pip 进行安装:
pip install pyodps
假设我们要从一个 CSV 文件中读取数据并将其写入 MaxCompute 表。我们可以使用 pandas 读取 CSV 文件,并使用 pyODPS 将其写入 MaxCompute。
import pandas as pd
from odps import ODPS
# 创建 ODPS 实例
odps = ODPS('<access_id>', '<secret_access_key>', '<project_name>', '<endpoint>')
# 读取 CSV 文件
df = pd.read_csv('data.csv')
# 查看数据
print(df.head())
为了将数据写入 MaxCompute 表,首先需要定义表的结构(即列名和类型)。在 MaxCompute 中,表的 schema 必须提前定义好。假设 CSV 文件中有两列 id 和 name,则可以创建一个相应的 MaxCompute 表:
# 定义表结构
schema = odps.Schema.from_lists(['id', 'name'], ['bigint', 'string'])
# 创建表,如果表已经存在,则可以跳过此步骤
if not odps.exist_table('my_table'):
odps.create_table('my_table', schema)
接下来,可以将读取到的数据写入 MaxCompute 表。写入时需要确保 pandas DataFrame 的列名和 MaxCompute 表的列名一致。
# 将 DataFrame 写入 MaxCompute 表
with odps.write_table('my_table', partition=None, overwrite=True) as writer:
for record in df.itertuples(index=False):
writer.write(list(record))
写入完成后,可以使用 SQL 语句在 MaxCompute 中查询表内容,验证数据是否正确写入。
# 运行 SQL 查询
with odps.execute_sql('SELECT * FROM my_table').open_reader() as reader:
for record in reader:
print(record)
创建 MaxCompute 表的模式:

写入数据:
pyODPS 通过 write_table 方法将数据按行插入到表中,确保列名和类型一致。
查询验证:
在通过 pyODPS 读取文件再写入 MaxCompute 表时,需要指定列名和数据类型。列名必须与表的 schema 保持一致,以确保数据能够正确写入到表中。
如果你读取的文件中包含表头,那么通常不需要手动设置列名,因为pyODPS会根据文件中的表头自动推断列名。但如果文件中没有表头,或者你希望使用特定的列名,那么你需要在代码中手动设置列名
参考文档https://blog.csdn.net/sinat_26917383/article/details/112178220
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。