在大数据计算MaxCompute中java可以引用表资源信息吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Java环境中,你可以通过MaxCompute提供的Java SDK来引用和操作表资源。
以下是在Java中引用MaxCompute表资源信息的基本步骤:
添加依赖:
在你的Java项目中,需要添加MaxCompute Java SDK的依赖。如果你使用Maven,可以在pom.xml文件中添加如下依赖:
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-java</artifactId>
<version>你的MaxCompute SDK版本</version>
</dependency>
创建项目和授权:
在MaxCompute控制台上创建一个项目(如果还没有的话),并在IAM(Identity and Access Management)中为你的账户授权,以访问MaxCompute服务。
配置访问信息:
在你的Java代码中配置MaxCompute的访问信息,包括Access Key ID、Access Key Secret、项目名(Project Name)和Endpoint。
import com.aliyun.odps.Odps;
import com.aliyun.odps.OdpsException;
import com.aliyun.odps.account.Account;
import com.aliyun.odps.account.AliyunAccount;
public class MaxComputeDemo {
public static void main(String[] args) {
Account account = new AliyunAccount("你的AccessKeyId", "你的AccessKeySecret");
try {
Odps odps = new Odps(account);
odps.setEndpoint("你的MaxCompute服务Endpoint");
odps.setDefaultProject("你的项目名");
// 接下来可以进行表操作
} catch (OdpsException e) {
e.printStackTrace();
}
}
}
引用表资源:
使用SDK提供的方法来引用和操作表资源。
import com.aliyun.odps.Instance;
import com.aliyun.odps.Odps;
import com.aliyun.odps.Table;
public class MaxComputeDemo {
public static void main(String[] args) {
// ... 省略配置访问信息的代码 ...
try {
// 获取表对象
Table table = odps.tables().get("你的表名");
// 可以进行查询、更新表结构等操作
// 例如,获取表的schema信息
Instance instance = table.createInstance();
System.out.println(instance.getSchema());
} catch (OdpsException e) {
e.printStackTrace();
}
}
}
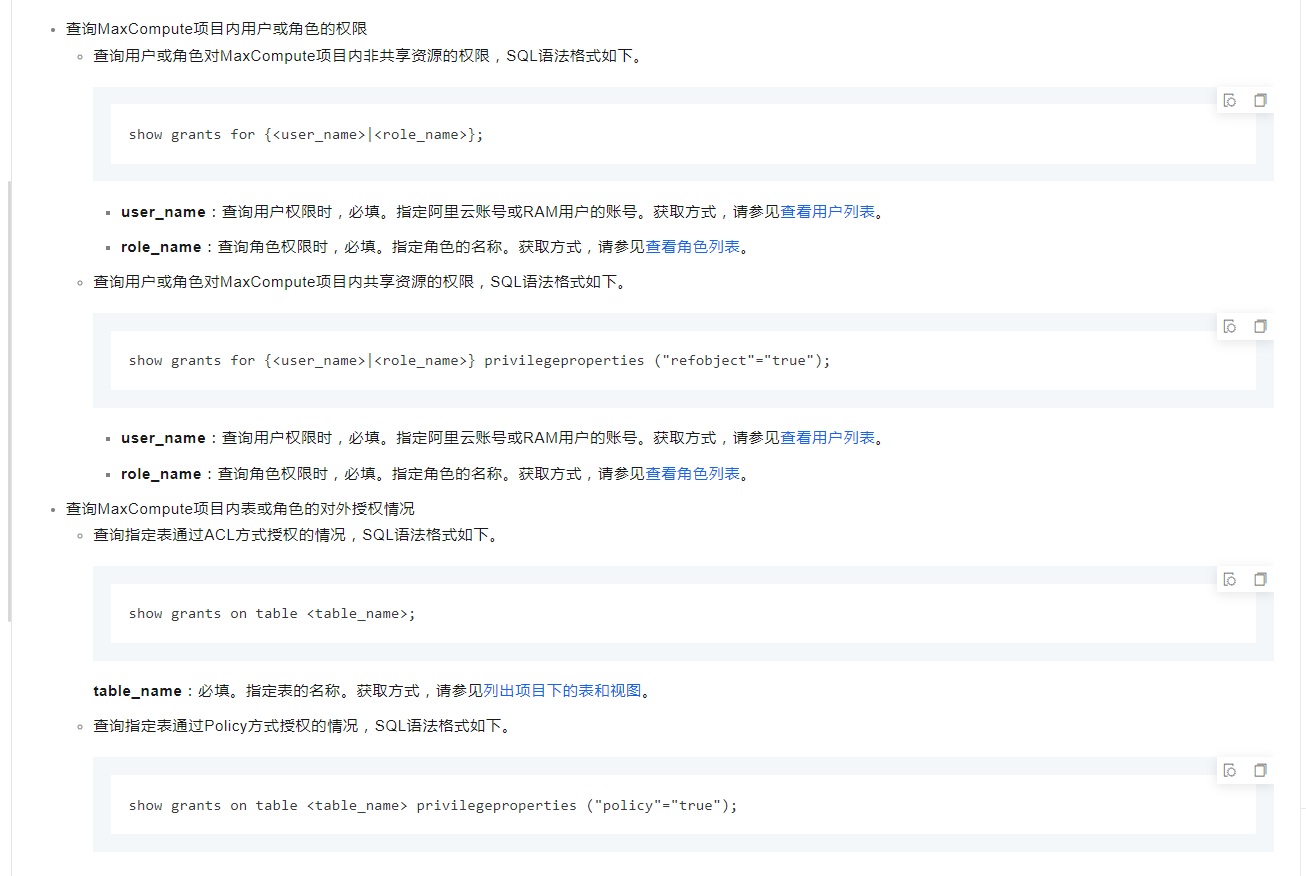
没有直接的用java的方法获取表资源信息
但是可以使用python
参考链接
https://help.aliyun.com/zh/maxcompute/user-guide/python-3-udfs
回答不易请采纳
在大数据计算MaxCompute中,Java可以通过阿里云的SDK来引用表资源信息。具体来说,可以使用阿里云的MaxCompute Java SDK来实现与MaxCompute服务的交互。
以下是一个简单的示例代码,展示了如何使用Java和MaxCompute SDK来引用表资源信息:
java
复制代码
import com.aliyun.odps.*;
import com.aliyun.odps.account.Account;
import com.aliyun.odps.account.AliyunAccount;
import com.aliyun.odps.tunnel.TableTunnel;
public class MaxComputeExample {
public static void main(String[] args) throws OdpsException {
// 设置访问MaxCompute的账号信息
Account account = new AliyunAccount("", "");
Odps odps = new Odps(account);
odps.setEndpoint("http://service.odps.aliyun.com/api");
odps.setDefaultProject("");
// 获取表资源信息
Table table = odps.getTable("<your-table-name>");
System.out.println("Table Name: " + table.getName());
System.out.println("Table Schema: " + table.getSchema());
System.out.println("Table Size: " + table.getSize());
// 其他操作...
}
}
在上面的代码中,需要替换、和为你的阿里云账号信息和项目名称。然后,通过odps.getTable()方法可以获取指定表的资源信息,包括表名、表结构、表大小等。
需要注意的是,在使用MaxCompute Java SDK之前,需要确保已经正确配置了相关的依赖库,并且按照阿里云官方文档的要求进行身份验证和授权。此外,还需要根据实际需求编写相应的代码逻辑来处理数据查询、数据处理等任务。
在MaxCompute中,使用Java SDK可以方便地操作MaxCompute中的各种资源,包括表、视图等。通过Java SDK,你可以执行诸如创建表、插入数据、查询数据等操作。下面我将展示一个简单的例子,说明如何使用Java SDK来操作MaxCompute中的表。
首先,你需要引入MaxCompute Java SDK依赖。如果你使用的是Maven项目,可以在pom.xml文件中添加如下依赖:
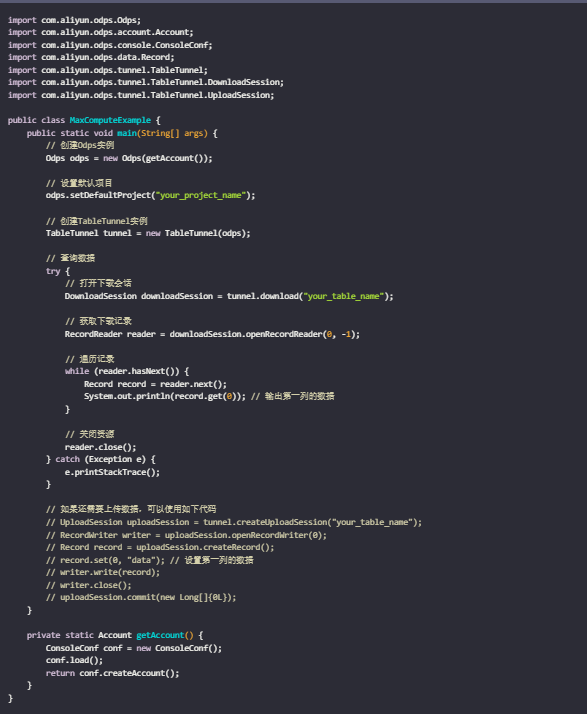
这段代码展示了如何使用TableTunnel来下载表中的数据。注意,你需要替换your_project_name和your_table_name为你实际的项目名和表名。此外,getAccount()方法假设你已经在~/.bdt/odps.config中配置了你的MaxCompute账户信息。
请注意,这个例子仅作为基础示例,实际使用时可能需要根据具体需求进行调整,例如处理异常、优化资源管理等。此外,MaxCompute Java SDK提供了丰富的API来操作MaxCompute资源,你可以查阅官方文档以了解更多细节。
可以,本文为您介绍基于MaxCompute Studio通过Java UDTF读取MaxCompute资源的使用示例。
参考文档https://help.aliyun.com/zh/maxcompute/user-guide/use-a-java-udtf-to-read-resources-from-maxcompute
可以,Java可以用来引用MaxCompute(原名MaxCompute)中的表资源。通过使用阿里云提供的ODPS Java SDK,您可以编写Java程序来访问和处理MaxCompute中的数据。例如,com.aliyun.odps.conf.Configuration,com.aliyun.odps.data.TableInfo,com.aliyun.odps.graph.GraphJob等类可以用来配置和提交处理这些表的图计算作业。参考中的VertexInputFormat类的示例,可以看出Java是如何加载和解析输入表的。
在阿里云的大数据计算服务 MaxCompute 中,Java 可以通过 MaxCompute 的 Java SDK 来引用表资源信息。MaxCompute 提供了丰富的 API 来操作和管理表、分区、资源等。以下是如何使用 Java SDK 引用表资源信息的一些示例。
首先,你需要在你的项目中引入 MaxCompute 的 Java SDK 依赖。如果你使用的是 Maven 项目,可以在 pom.xml 文件中添加以下依赖:
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-core</artifactId>
<version>0.38.6-public</version> <!-- 请使用最新版本 -->
</dependency>
你需要初始化一个 ODPS 客户端实例来连接到 MaxCompute 服务。
import com.aliyun.odps.Odps;
import com.aliyun.odps.account.Account;
import com.aliyun.odps.account.AliyunAccount;
public class MaxComputeExample {
public static void main(String[] args) {
// 替换为你的 Access ID 和 Access Key
String accessId = "<your-access-id>";
String accessKey = "<your-access-key>";
String endpoint = "http://service.odps.aliyun.com/api"; // 或者其他区域的 endpoint
String project = "<your-project-name>";
// 创建账号
Account account = new AliyunAccount(accessId, accessKey);
// 初始化 ODPS 客户端
Odps odps = new Odps(account);
odps.setEndpoint(endpoint);
odps.setDefaultProject(project);
}
}
你可以通过 Odps 实例来引用表资源信息,例如获取表的结构、列信息、分区信息等。
import com.aliyun.odps.TableSchema;
import com.aliyun.odps.OdpsException;
public class MaxComputeExample {
public static void main(String[] args) {
// 初始化 ODPS 客户端
Odps odps = initializeOdpsClient();
try {
// 获取表的 schema
TableSchema tableSchema = odps.tables().get("your_table_name").getSchema();
System.out.println("Table Schema: " + tableSchema.toString());
} catch (OdpsException e) {
e.printStackTrace();
}
}
private static Odps initializeOdpsClient() {
// 替换为你的 Access ID 和 Access Key
String accessId = "<your-access-id>";
String accessKey = "<your-access-key>";
String endpoint = "http://service.odps.aliyun.com/api"; // 或者其他区域的 endpoint
String project = "<your-project-name>";
// 创建账号
Account account = new AliyunAccount(accessId, accessKey);
// 初始化 ODPS 客户端
Odps odps = new Odps(account);
odps.setEndpoint(endpoint);
odps.setDefaultProject(project);
return odps;
}
}
import com.aliyun.odps.Column;
import com.aliyun.odps.OdpsException;
public class MaxComputeExample {
public static void main(String[] args) {
// 初始化 ODPS 客户端
Odps odps = initializeOdpsClient();
try {
// 获取表的 schema
TableSchema tableSchema = odps.tables().get("your_table_name").getSchema();
// 打印列信息
for (Column column : tableSchema.getColumns()) {
System.out.println("Column Name: " + column.getName() + ", Type: " + column.getTypeInfo().getTypeName());
}
} catch (OdpsException e) {
e.printStackTrace();
}
}
private static Odps initializeOdpsClient() {
// 替换为你的 Access ID 和 Access Key
String accessId = "<your-access-id>";
String accessKey = "<your-access-key>";
String endpoint = "http://service.odps.aliyun.com/api"; // 或者其他区域的 endpoint
String project = "<your-project-name>";
// 创建账号
Account account = new AliyunAccount(accessId, accessKey);
// 初始化 ODPS 客户端
Odps odps = new Odps(account);
odps.setEndpoint(endpoint);
odps.setDefaultProject(project);
return odps;
}
}
import com.aliyun.odps.PartitionSpec;
import com.aliyun.odps.OdpsException;
public class MaxComputeExample {
public static void main(String[] args) {
// 初始化 ODPS 客户端
Odps odps = initializeOdpsClient();
try {
// 获取表的所有分区
List<PartitionSpec> partitions = odps.tables().get("your_partitioned_table_name").getPartitions();
// 打印分区信息
for (PartitionSpec partition : partitions) {
System.out.println("Partition: " + partition.toString());
}
} catch (OdpsException e) {
e.printStackTrace();
}
}
private static Odps initializeOdpsClient() {
// 替换为你的 Access ID 和 Access Key
String accessId = "<your-access-id>";
String accessKey = "<your-access-key>";
String endpoint = "http://service.odps.aliyun.com/api"; // 或者其他区域的 endpoint
String project = "<your-project-name>";
// 创建账号
Account account = new AliyunAccount(accessId, accessKey);
// 初始化 ODPS 客户端
Odps odps = new Odps(account);
odps.setEndpoint(endpoint);
odps.setDefaultProject(project);
return odps;
}
}
通过上述代码示例,你可以使用 Java SDK 来引用 MaxCompute 表的资源信息,包括表的 schema、列信息和分区信息。这些信息对于理解表的结构和内容非常有用,特别是在进行数据处理和分析时。确保你已经正确配置了访问凭证和 endpoint,并且替换为你实际的表名和项目名。
本文为您介绍基于MaxCompute Studio通过Java UDTF读取MaxCompute资源的使用示例。
参考文档https://help.aliyun.com/zh/maxcompute/user-guide/use-a-java-udtf-to-read-resources-from-maxcompute
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。