
云数据仓库ADB查询解决方案有哪些?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
查询执行模式调整:ADB for MySQL允许用户设置不同的查询执行模式,包括默认的interactive模式(使用XIHE MPP引擎)和batch模式(使用XIHE BSP引擎)。在数仓版(3.0)的弹性集群中,可以通过特定的提示(例如/+query_type=batch/)来改变执行模式。详细说明请参考查询执行模式 和 资源组。
性能调优与诊断:ADB提供性能诊断工具,帮助解决数据查询性能慢的问题。这包括数据建模、慢查询诊断、SQL模板分析等。具体指导请参考性能调优、SQL诊断和数据建模。
SQL诊断功能:ADB MySQL版提供了详细的SQL诊断功能,便于用户检索并分析慢查询,通过图形化界面展示查询结果。更多功能介绍请参考SQL诊断功能介绍。
查询超时时间修改:可以通过配置参数QUERY_TIMEOUT来调整查询超时限制。具体配置方法请参考ADB MySQL常见配置参数。
LIKE查询优化:针对LIKE查询效率低的问题,由于当前ADB MySQL的LIKE查询无法有效利用索引,建议对于此类查询需求考虑使用全文索引以提高查询效率。
这些解决方案旨在帮助用户提升ADB查询性能和效率,解决常见的查询问题。
此回答整理自钉群“云数据仓库ADB-开发者群”
基于混合负载的查询优化
企业数字化分析的多元化,涵盖了实时的BI决策,实时报表,数据ETL,数据清洗以及AI分析。
传统数仓方案,通过组合多套数据库与大数据产品,利用各自不同的优势来解决不同的分析场景,带来的问题就是整个数据冗余,同时管理多个异构系统的代价。
完备数据仓库,首要解决的问题包括:
如何更好的支持数据库场景下的交互式分析以及大数据场景下的复杂批计算场景;
如何一站式的解决混合负载下的服务能力。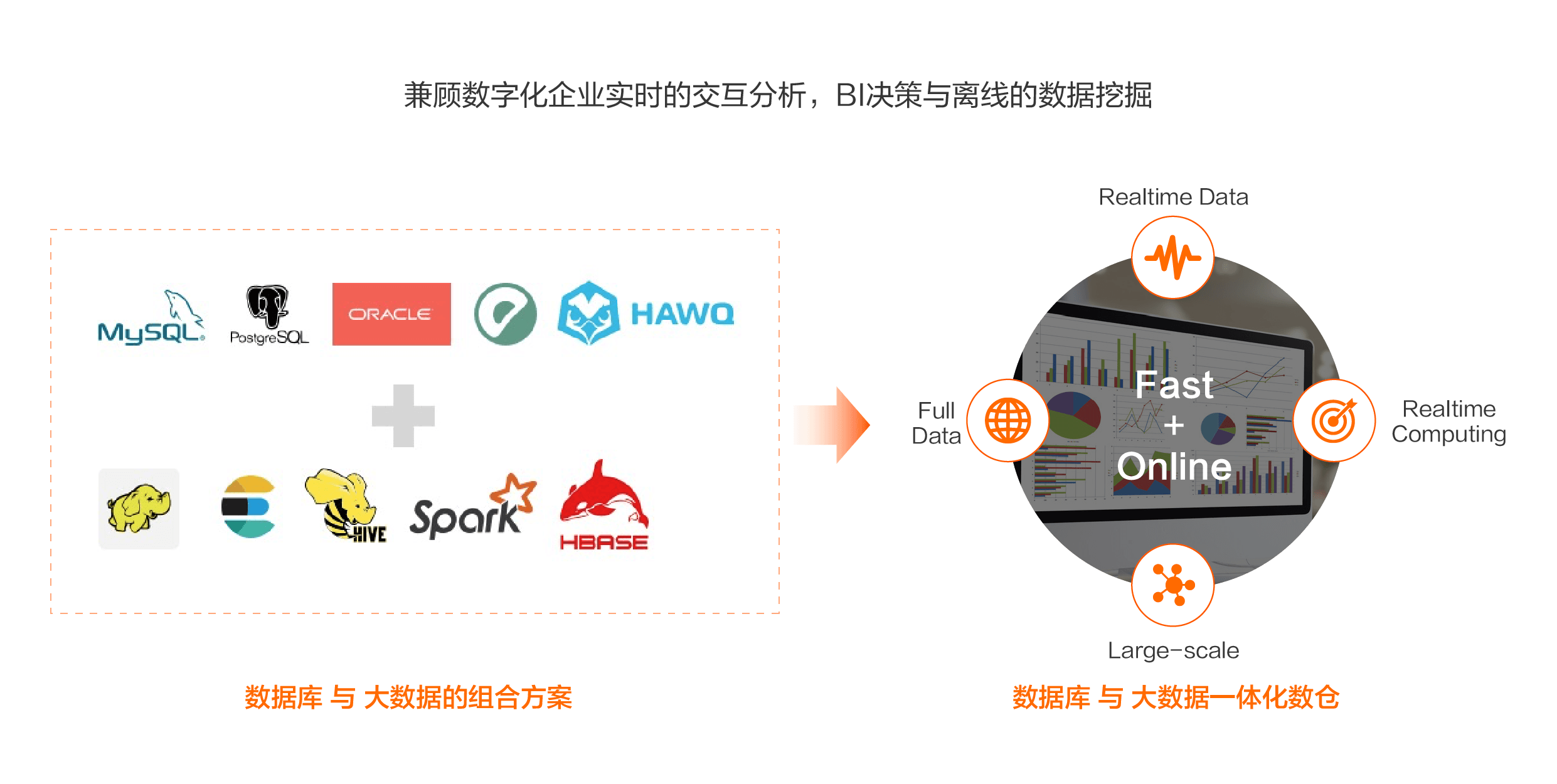
阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。


