训练万亿/10万亿参数的M6模型时,EPL框架如何实现算力需求的降低?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
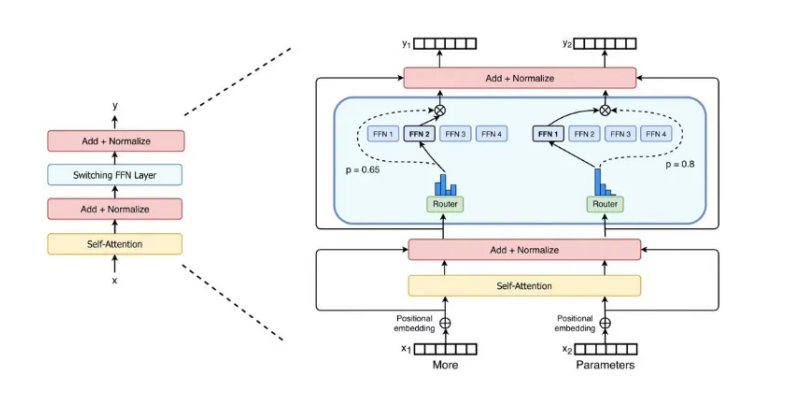
为了降低训练万亿/10万亿参数M6模型的算力需求,EPL框架中实现了MoE(Mixture-of-Experts)结构。MoE通过稀疏激活的特点,使用Gating(Router)为输入选择Top-k的expert进行计算,从而大大减少算力需求。此外,EPL还支持专家并行(EP),将experts拆分到多个devices上,进一步降低单个device的显存和算力需求。