
qwen-long大模型如何实现多轮对话?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Qwen-Long大模型实现多轮对话的方式主要依赖于系统消息(system message)中对文件ID(fileid)的管理和内容的引用,以及对上下文tokens的高效利用。以下是关键步骤和建议:
fileid。fileid,格式如:'content': 'fileid://{file_1.id},fileid://{file_2.id}'。这样模型就能持续访问这些文件内容,支持上下文连贯的多轮对话。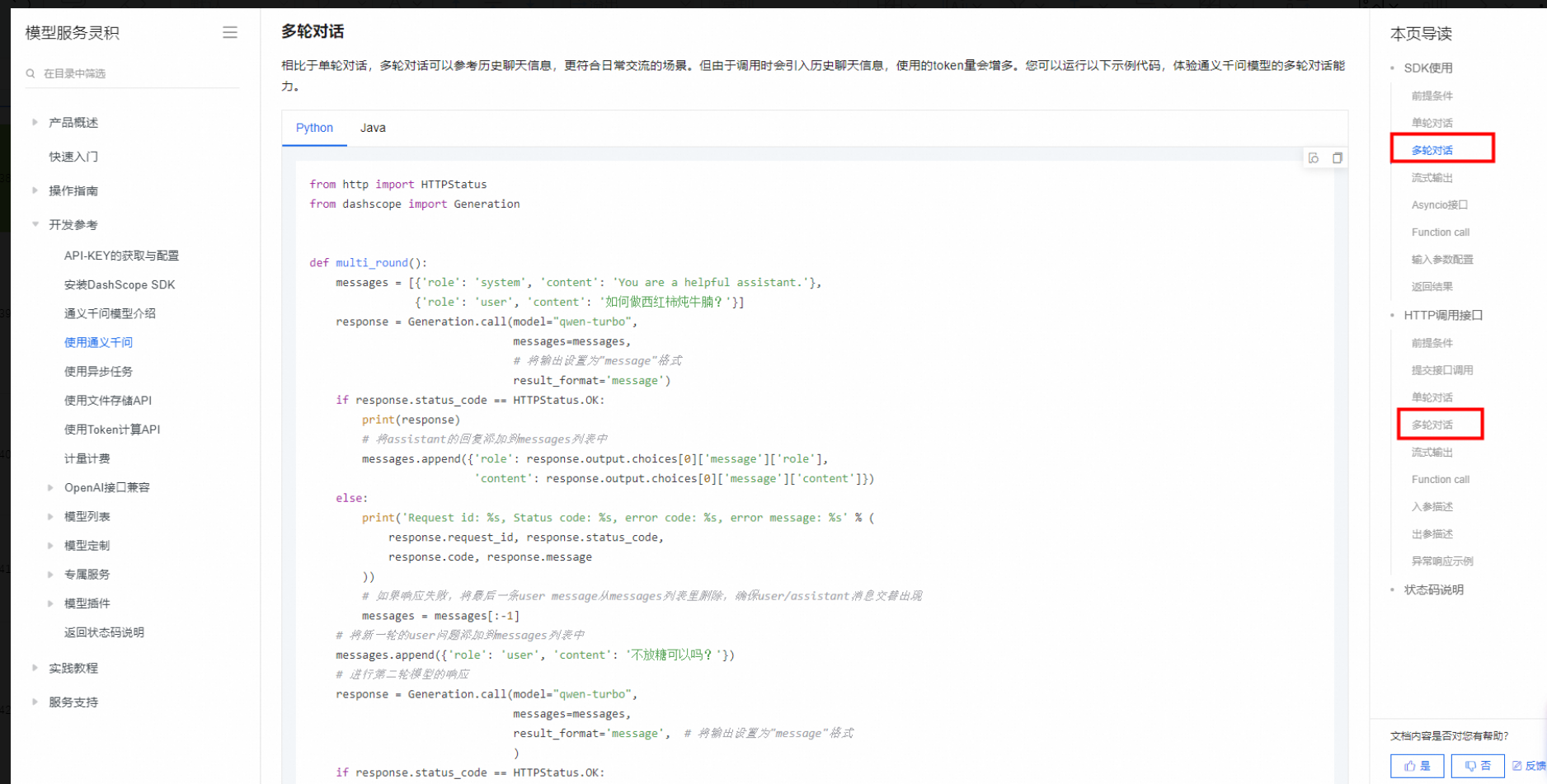
相关链接
API详情 https://help.aliyun.com/zh/dashscope/developer-reference/qwen-long-api

