DataWorks中UNLOAD 导数据到oss 那个参数可以带表头?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

在DataWorks中,使用数据集成服务导出(Unload)数据到OSS时,若想在导出的文件中包含表头,可以通过配置OSS Writer插件的相应参数实现。虽然直接提及表头参数的文档信息不充分,但在实际操作中,通常会有类似于“包含表头”或“写入列名”这样的选项,允许用户在导出数据时包含第一行作为列名。为了实现这一需求,您需要进入数据集成任务的配置界面,在目标OSS Writer插件的设置里寻找是否有此类选项,并勾选它以确保导出数据时包含表头
相关链接
数据导出到OSS概述 实现原理 https://help.aliyun.com/zh/tablestore/use-cases/overview-of-exporting-tablestore-data-to-oss
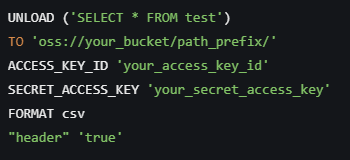
在DataWorks中使用UNLOAD命令导数据到OSS时,若想在导出的文件中包含表头,应配置header参数。根据提供的参考资料,该参数用于指定OSS写出时的表头,例如,配置\[\"id\", \"name\", \"age\"]会让输出的文件包含这些列名作为表头。因此,通过设置header参数,可以实现在导出到OSS的文件中带有表头的功能。
相关链接
https://help.aliyun.com/zh/dataworks/user-guide/oss-data-source
在UNLOAD语句中,您可以这样设置:
UNLOAD
INTO 'oss://your-bucket/your-prefix/'
FROM your_table
ACCESS_KEY 'your-access-key-id'
SECRET_KEY 'your-secret-access-key'
HEADER true;
在DataWorks中,使用UNLOAD命令将数据导出到OSS时,无法直接通过该命令的一个参数来带有表头。DataWorks 是阿里云提供的一个大数据开发、运维、分析平台,它整合了数据集成、开发、调度等工具,适合用来处理批量或实时的数据任务。
以下几种方法可以帮助在导出数据时加入表头:
手动添加表头:在导出数据后,通过编写脚本(如Python、Shell脚本)读取表结构,获取列名作为表头,并添加到导出的数据文件中。这需要一定的编程能力,但可以灵活地控制表头格式。
使用数据集成功能:在DataWorks的数据集成任务中,可以配置一个SQL查询节点来读取数据并包含表头信息,然后将查询结果导出到OSS。这需要在DataWorks Studio中进行配置,并且可能需要手动构造包含表头的查询语句。
使用第三方工具或脚本:除了DataWorks外,还可以考虑使用第三方工具或编写自定义脚本来处理数据导出和表头添加操作。这些工具可能提供更多的数据处理选项。
查询时包含表头:在执行查询时,可以在查询语句中包含表头信息,然后再使用UNLOAD命令将结果导出到OSS。此方法同样需要在查询语句中手动指定表头。
综上所述,虽然DataWorks中的UNLOAD命令本身不提供直接添加表头的参数,但可以通过其他方法实现类似的需求。具体选择哪种方法取决于实际情况与技术偏好。无论采用哪种方案,都需要确保在处理过程中数据的完整性和准确性。
在DataWorks中,使用UNLOAD命令将数据导出到OSS(对象存储服务)时,通常UNLOAD命令本身并不直接支持在导出文件中添加表头(列名)作为文件的第一行。UNLOAD命令主要用于将MaxCompute(原名ODPS)表中的数据导出到外部存储位置,如OSS,但它主要关注数据的导出格式和位置,而不直接处理表头信息的添加。
然而,如果你需要在导出的文件中包含表头,有几种方法可以实现:
手动添加表头:在导出数据后,你可以使用DataWorks的脚本功能或外部工具(如Python脚本、Shell脚本等)来读取表结构,获取列名,并将这些列名作为表头添加到导出的数据文件中。这种方法需要一定的编程或脚本编写能力。
使用DataWorks的数据集成功能:DataWorks提供了数据集成功能,允许用户通过配置数据源、目标源和转换规则来实现数据的自动化处理。虽然标准的UNLOAD操作不支持直接添加表头,但你可以通过数据集成任务中的自定义转换步骤来实现这一需求。例如,你可以使用DataWorks的DataWorks Studio(DWS)中的SQL节点来查询数据,并在查询结果中包含表头信息(作为查询结果的一部分),然后将结果导出到OSS。但请注意,这种方法可能需要你手动构造包含表头的查询语句。
使用第三方工具或脚本:除了DataWorks自身的功能外,你还可以考虑使用第三方工具或脚本来处理数据的导出和表头的添加。这些工具可能提供了更灵活的数据处理选项,包括在导出过程中自动添加表头。
查询时包含表头:虽然这不是UNLOAD命令的直接功能,但你可以在查询时构造一个包含表头作为第一行数据的查询语句。然后,你可以使用UNLOAD命令将这个查询结果导出到OSS。然而,这种方法需要你在查询语句中手动指定表头,并且表头数据需要与实际的表结构保持一致。
综上所述,DataWorks中的UNLOAD命令本身并不支持直接添加表头到导出的文件中。但你可以通过其他方法(如手动添加、使用数据集成功能、使用第三方工具或脚本、查询时包含表头等)来实现这一需求。请注意,选择哪种方法取决于你的具体需求、资源和技术能力。
DataWorks中,使用UNLOAD命令将数据导出到OSS时,如果需要包含表头,可以在UNLOAD语句中使用CSV格式并指定HEADER选项。例如:
CSV HEADER 参数表示导出的数据以CSV格式存储,并且第一行包含列名作为表头。请确保替换 your_table 为你的表名,your_oss_bucket_path 为OSS的路径,your_credential_string 为你的凭证字符串。
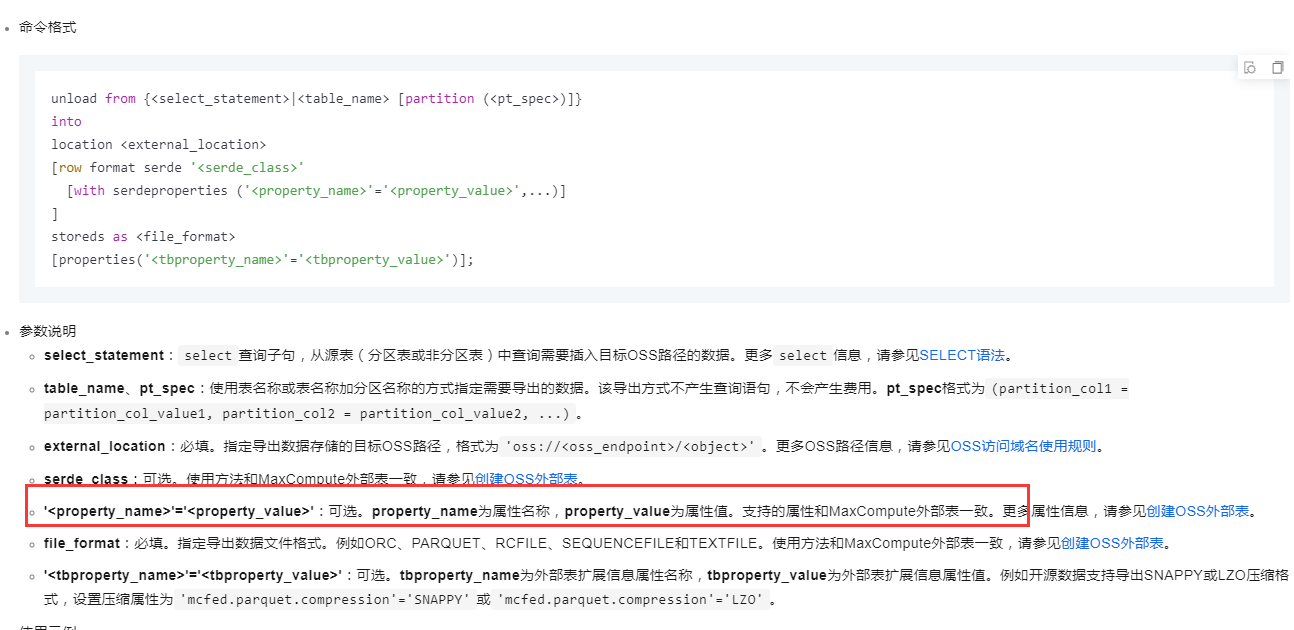
在阿里云 DataWorks 中使用 UNLOAD 语句导出数据到 OSS(Object Storage Service)时,可以通过设置特定的参数来控制是否包含表头。UNLOAD 语句在 MaxCompute 中用于将查询结果导出到 OSS 上的文件中。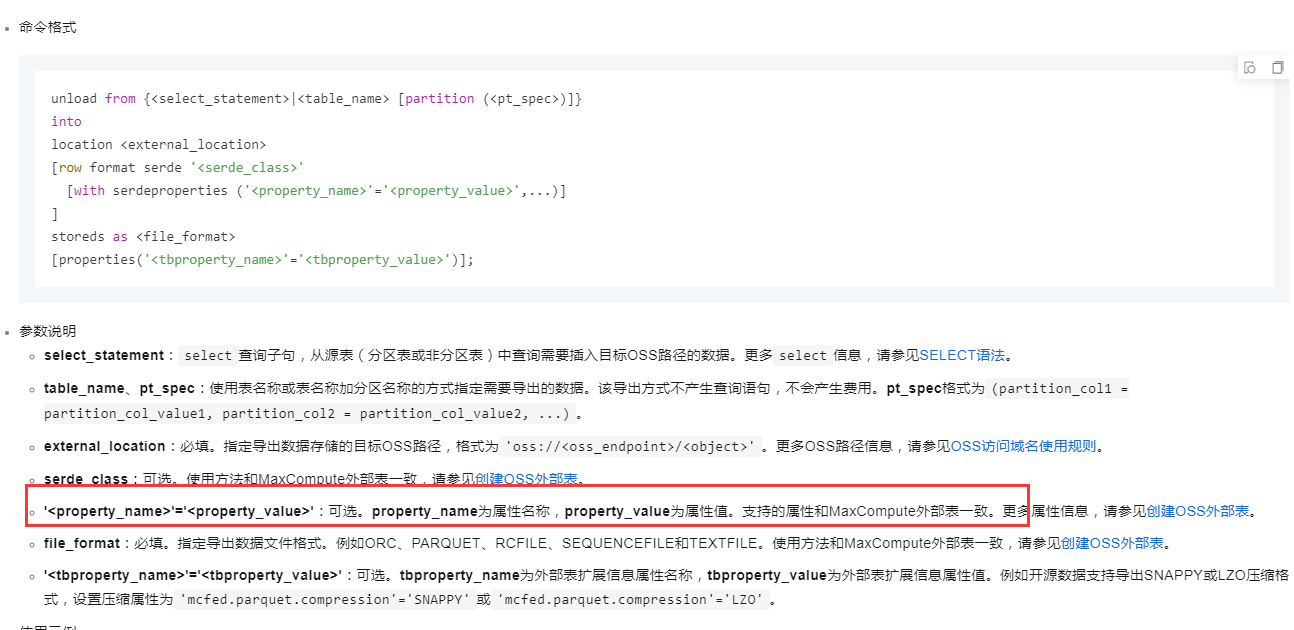
UNLOAD 语句的基本语法如下:
UNLOAD
(
SELECT * FROM table_name
)
TO 'oss://bucket-name/path'
WITH (
format = 'csv',
delimiter = '\t',
file_type = 'text',
compress = 'gzip',
column_separator = ',',
row_metas = 'none',
field_terminator = ',',
line_delimiter = '\n',
escape = '\\',
quote = '"',
overwrite = 'true',
header = 'true' -- 这里设置是否包含表头
);
header:此参数用于控制导出文件是否包含表头。如果设置为 'true',则导出的文件将包含表头;如果设置为 'false',则不会包含表头。默认情况下,header 参数的值为 'false'。假设您有一个名为 sales 的表,并且想要将表中的数据导出到 OSS 上的一个文件中,同时包含表头。可以使用以下 SQL 语句:
UNLOAD
(
SELECT * FROM sales
)
TO 'oss://your-bucket-name/path/to/your/file.csv'
WITH (
format = 'csv',
delimiter = ',',
header = 'true' -- 包含表头
);
在这个例子中,header = 'true' 表示导出的 CSV 文件将包含表头。
表头格式:默认情况下,表头将使用与数据相同的分隔符和转义字符。如果需要自定义表头的格式,您可能需要先将表头写入一个单独的文件,然后再将数据导出到同一个文件中,或者在导出后手动添加表头。
兼容性:请确保您使用的 MaxCompute 版本支持 header 参数。如果版本较旧,可能需要升级到最新版本。
权限:确保 MaxCompute 有足够的权限访问 OSS 上的目标路径。
通过在 UNLOAD 语句中设置 header = 'true',您可以轻松地将表头包含在导出的 CSV 文件中。如果在实际操作过程中遇到任何问题或需要进一步的帮助,请随时告诉我。
在DataWorks中,当你使用ODPS SQL的UNLOAD命令将数据导出到OSS时,UNLOAD命令本身并不直接支持导出表头。但是,你可以通过以下方式来实现带表头的导出:
手动添加表头: 在执行UNLOAD命令后,你可以手动在OSS文件的开头添加表头。这通常需要一个额外的步骤,例如使用Python、Java或其他编程语言编写脚本来完成。
使用DataWorks的ETL功能: 在DataWorks的数据开发界面,你可以创建一个新的数据处理任务(如Data Processing或Data Integration任务),在任务中先执行一个SQL查询,将表头作为第一行数据输出,然后再执行UNLOAD命令导出数据。这样,表头和数据会被一起写入到同一个OSS文件中。
例如,你可以创建一个Data Processing任务,SQL脚本如下:
-- 输出表头
SELECT 'column1' AS col1, 'column2' AS col2, ... FROM DUAL;
-- 输出实际数据
UNLOAD ('SELECT column1, column2, ... FROM your_table')
TO 'your_oss_path'
WITH CREDENTIALS 'your_credential_string';
在这个例子中,DUAL是一个虚拟表,用于返回单行数据。UNLOAD命令将紧跟在前面的SQL查询结果一起导出。
使用自定义脚本: 如果你的数据源支持在UNLOAD时自定义输出格式,你也可以编写一个自定义的ODPS UDF(User Defined Function)或脚本,来实现将表头和数据一起导出的功能。
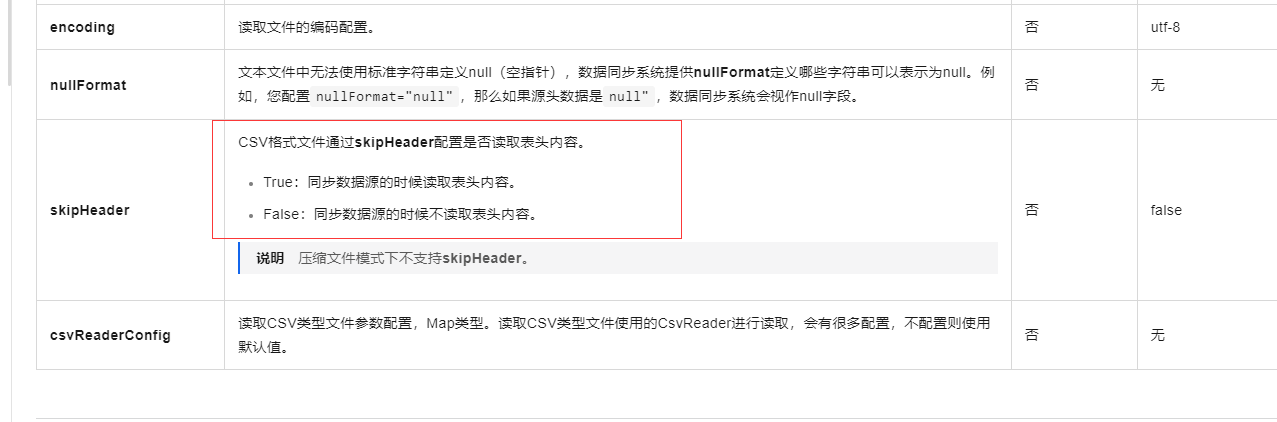
在DataWorks中使用UNLOAD命令将数据导出到OSS时,如果需要在导出的文件中包含表头(即列名),可以使用skipHeader参数并将其设置为true。这样,在导出的数据文件中将会跳过表头,即不包含列名。默认情况下,skipHeader参数的值为false,表示会导出表头信息 。
另外,在使用UNLOAD命令时,还可以通过with serdeproperties子句中的property_name来指定一些额外的属性,例如设置字段分隔符、压缩格式等。但具体是否支持直接导出包含表头的文件,需要参考MaxCompute的UNLOAD命令的具体语法和支持的参数
CSV格式文件通过skipHeader配置是否读取表头内容。
True:同步数据源的时候读取表头内容。
False:同步数据源的时候不读取表头内容。
参考文档https://help.aliyun.com/zh/dataworks/user-guide/amazon-s3-data-source?spm=a2c4g.11186623.0.i184
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。