dataworks中pyodps节点使用pyodps-pack打的第三方包能超过100M吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

DataWorks导入包大小限制100M
仅主账号和工作空间管理员能够进行导入和导出操作,其他角色成员仅支持查看导入、导出任务列表,无操作权限。
进行数据质量规则导出与导入时,有以下注意事项:
导出数据质量规则时,订阅管理(报警相关配置)不支持导出。
导入的数据质量规则关联的表如果在目标空间不存在,则在数据质量规则页面上不会展示出这条导入的规则,如果在导入数据质量规则后完成目标表创建,那同样会在表的规则详情页展示出这条导入的规则。
数据质量导入步骤会依赖周期任务导入步骤成功才会执行,因为同一个导入包里面如果同时有数据质量规则和关联的调度节点信息,您需要先把关联的节点先导入目标空间且成功提交发布了,才能将调度节点和正确的质量规则关联上。
如果只单独导入数据质量,不导入关联的调度节点,那数据质量依然会导入成功,只是没有关联调度节点的信息。后续把关联调度节点信息导入提交发布后,重新导入数据质量规则后,DataWorks会重新更新数据质量规则并关联上调度节点。
如果你的第三方包超过了这个范围,可以尝试以下方法:
拆分大包:如果可能,将大的库拆分成多个小的库,每个小库单独打包。
使用依赖管理工具:像pip这样的工具可以生成依赖树,你可以只打包那些必要的子模块,而不是整个库。
优化库:有些库可能包含大量不必要的数据或二进制文件,尝试查找是否有轻量级的替代品,或者使用--no-binary :all:参数来禁用预编译的二进制文件。
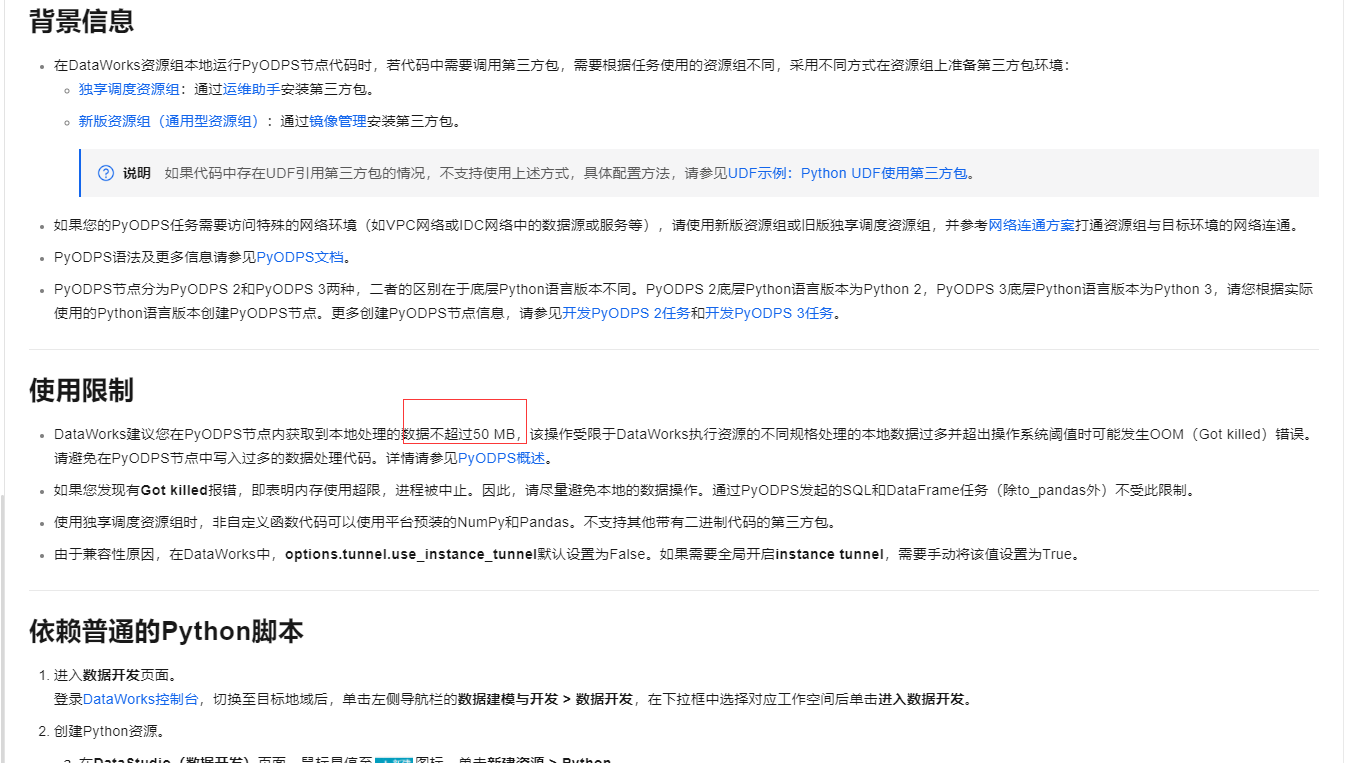
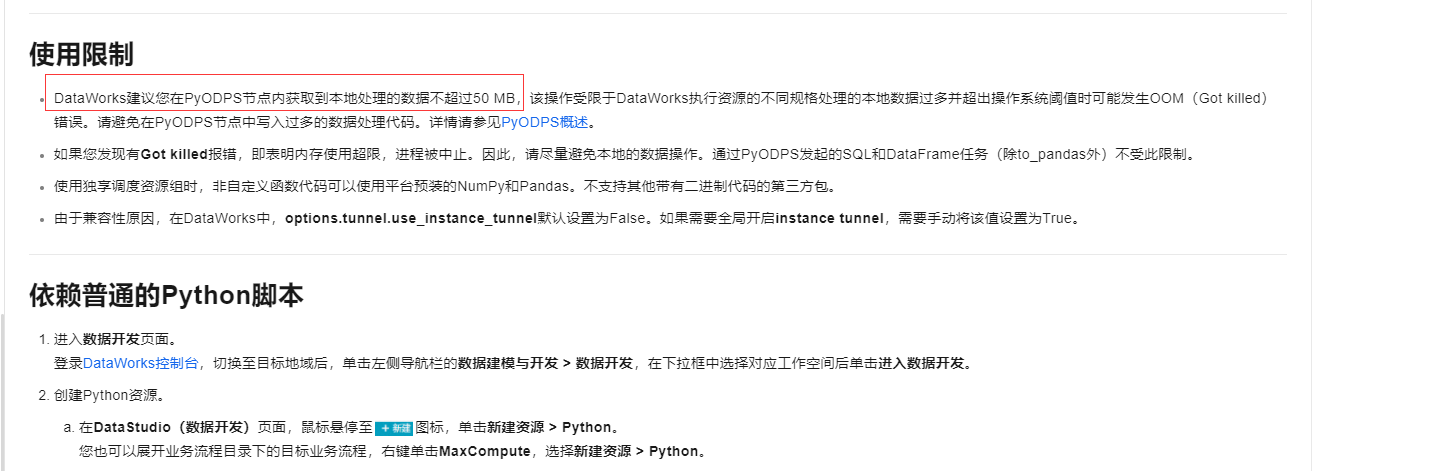
DataWorks建议在PyODPS节点内处理的本地数据量不要超过50 MB
,以避免因资源规格限制可能导致的OOM(内存溢出)错误。
并未直接提及具体的数值限制,但考虑到DataWorks导入任务的整体限制,导入包的大小需符合所使用DataWorks版本的限制,例如基础版限制为100M,标准版为300M,而专业版和企业版则无上限
https://help.aliyun.com/zh/dataworks/user-guide/create-and-view-import-tasks
在DataWorks的PyODPS节点中,使用pyodps-pack命令行工具打包的第三方包在理论上是可以超过100MB的,但实际操作中需要考虑DataWorks的执行资源和限制。
首先,pyodps-pack是PyODPS自V0.11.3版本开始提供的一个命令行工具,用于制作符合PyODPS及DataWorks PyODPS节点标准的三方包。该工具可以将所有依赖项目制作成一个后缀为.tar.gz的压缩包,其中包含所有依照MaxCompute或DataWorks环境编译并打包的项目依赖。这一步骤本身并不对包的大小设置硬性限制。
然而,在DataWorks中使用这些第三方包时,可能会受到以下限制:
执行资源限制:DataWorks的执行资源(包括公共调度资源组和独享调度资源组)有不同的规格和限制。如果PyODPS节点内的数据处理量过大,可能会超出操作系统的阈值,导致OOM(Out of Memory)错误,即内存使用超限,进程被中止。虽然包的大小本身不直接决定内存使用量,但大型包可能包含更多资源,从而增加内存消耗的风险。
上传和存储限制:虽然pyodps-pack打包的第三方包在理论上可以超过100MB,但在将包上传到DataWorks或MaxCompute时,可能会遇到上传限制或存储限制。例如,在DataWorks中直接上传文件时,通常会有大小限制。此时,可以考虑使用阿里云的对象存储服务(OSS)来存储大型文件,并在DataWorks中通过相应组件进行读取和使用。
性能考虑:大型包可能会增加节点的启动时间和处理时间,因为需要加载更多的依赖和资源。在性能敏感的应用场景中,应尽量避免使用过大的第三方包。
综上所述,虽然pyodps-pack打包的第三方包在理论上可以超过100MB,但在DataWorks中使用时需要考虑执行资源限制、上传和存储限制以及性能影响。为了确保应用的稳定性和性能,建议根据实际情况选择合适的包大小,并优化代码和资源使用。
在DataWorks中,PyODPS节点使用的第三方包大小是有限制的。根据阿里云官方文档,单个PyODPS节点的代码包大小限制为100MB。因此,如果您使用pyodps-pack打包的第三方包超过100MB,那么将无法上传到DataWorks中。
为了解决这个问题,您可以尝试以下方法:
检查并优化您的第三方包,减少不必要的文件和依赖,以减小包的大小。
如果可能,将一些不常用的库拆分成多个较小的包,然后在DataWorks中分别上传这些包。
考虑使用其他云服务或本地服务器来运行您的任务,以避免DataWorks的限制。
请注意,这些解决方案可能需要根据您的具体情况进行调整。
在DataWorks中使用PyODPS节点时,如果你需要使用第三方Python包并通过pyodps-pack打包,那么关于包的大小有一些限制需要注意。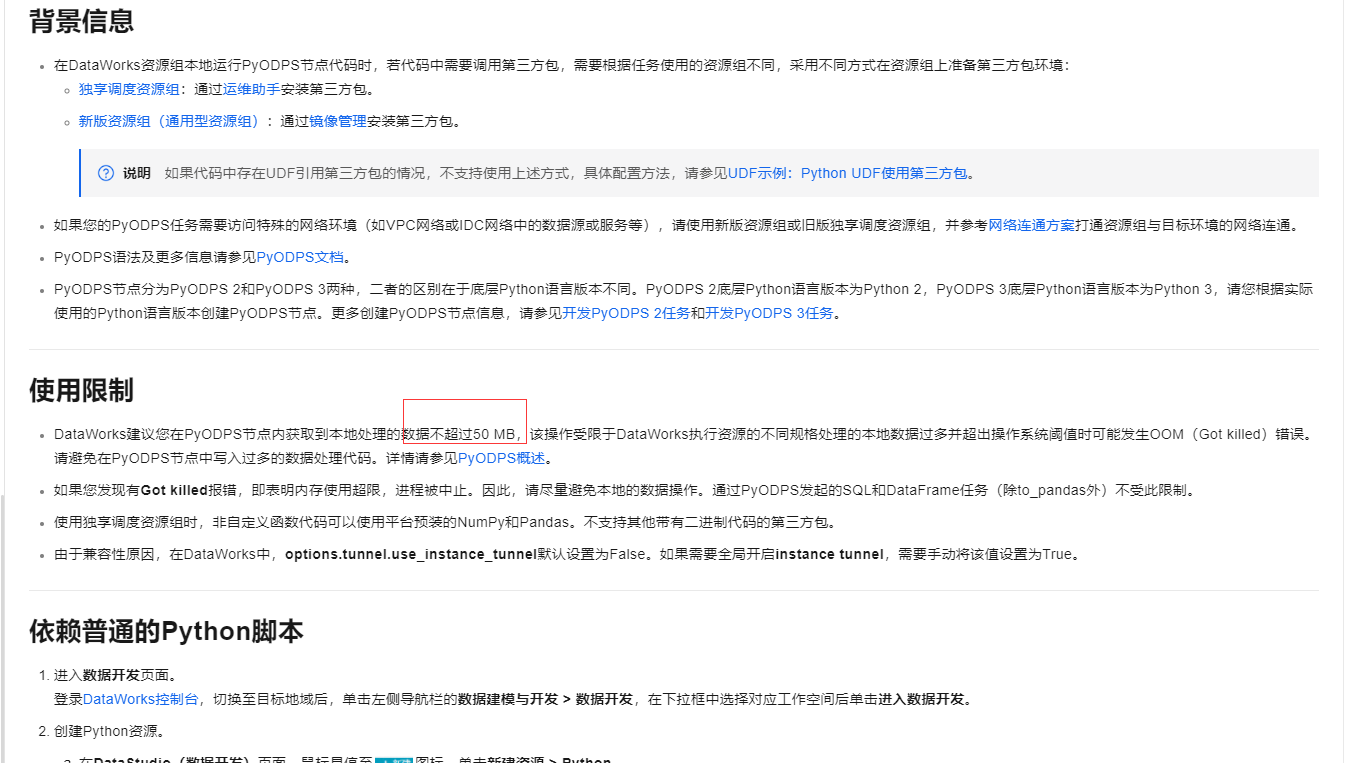
DataWorks对于通过pyodps-pack打包的第三方包大小有一定的限制。官方文档中提到的限制是100MB,这是因为打包后的资源会被上传到MaxCompute,而MaxCompute对于单个文件的大小有一定的限制。具体来说,MaxCompute对于单个文件的大小限制通常是100MB。
如果第三方包超过了100MB,你可以考虑以下几种解决方案:
优化依赖:
拆分包:
使用虚拟环境:
pip命令只安装必要的包,避免安装不必要的依赖。自定义Docker镜像:
使用MaxCompute UDF:
请求增加限制:
如果你需要将一个较大的第三方包用于PyODPS节点,这里有一个简化的示例来展示如何使用pyodps-pack打包并优化包大小:
创建虚拟环境:
python3 -m venv myenv
source myenv/bin/activate
安装必要的包:
pip install numpy pandas --no-deps
创建requirements.txt文件:
pip freeze > requirements.txt
使用pyodps-pack打包:
pyodps-pack requirements.txt
检查打包后的文件大小:
ls -lh
在DataWorks中使用打包后的文件:
请确保在打包之前仔细检查你的依赖项,以确保最终的包尽可能小。如果需要进一步的帮助或有关于特定配置的问题,请随时告诉我。
在DataWorks中,使用pyodps-pack打包的第三方包总大小不能超过100 MB。这是DataWorks对下载的第三方包大小的限制。如果您的包超过这个限制,您需要重新考虑包内容,或者分拆包以满足这一要求。
不能。
DataWorks建议您在PyODPS节点内获取到本地处理的数据不超过50 MB,该操作受限于DataWorks执行资源的不同规格处理的本地数据过多并超出操作系统阈值时可能发生OOM(Got killed)错误。请避免在PyODPS节点中写入过多的数据处理代码。
DataWorks建议您在PyODPS节点内获取到本地处理的数据不超过50 MB,该操作受限于DataWorks执行资源的不同规格处理的本地数据过多并超出操作系统阈值时可能发生OOM(Got killed)错误。请避免在PyODPS节点中写入过多的数据处理代码。详情请参见PyODPS概述。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。