DataWorks刚点开那个运行历史 发现报这个错误,不知道是哪里有问题?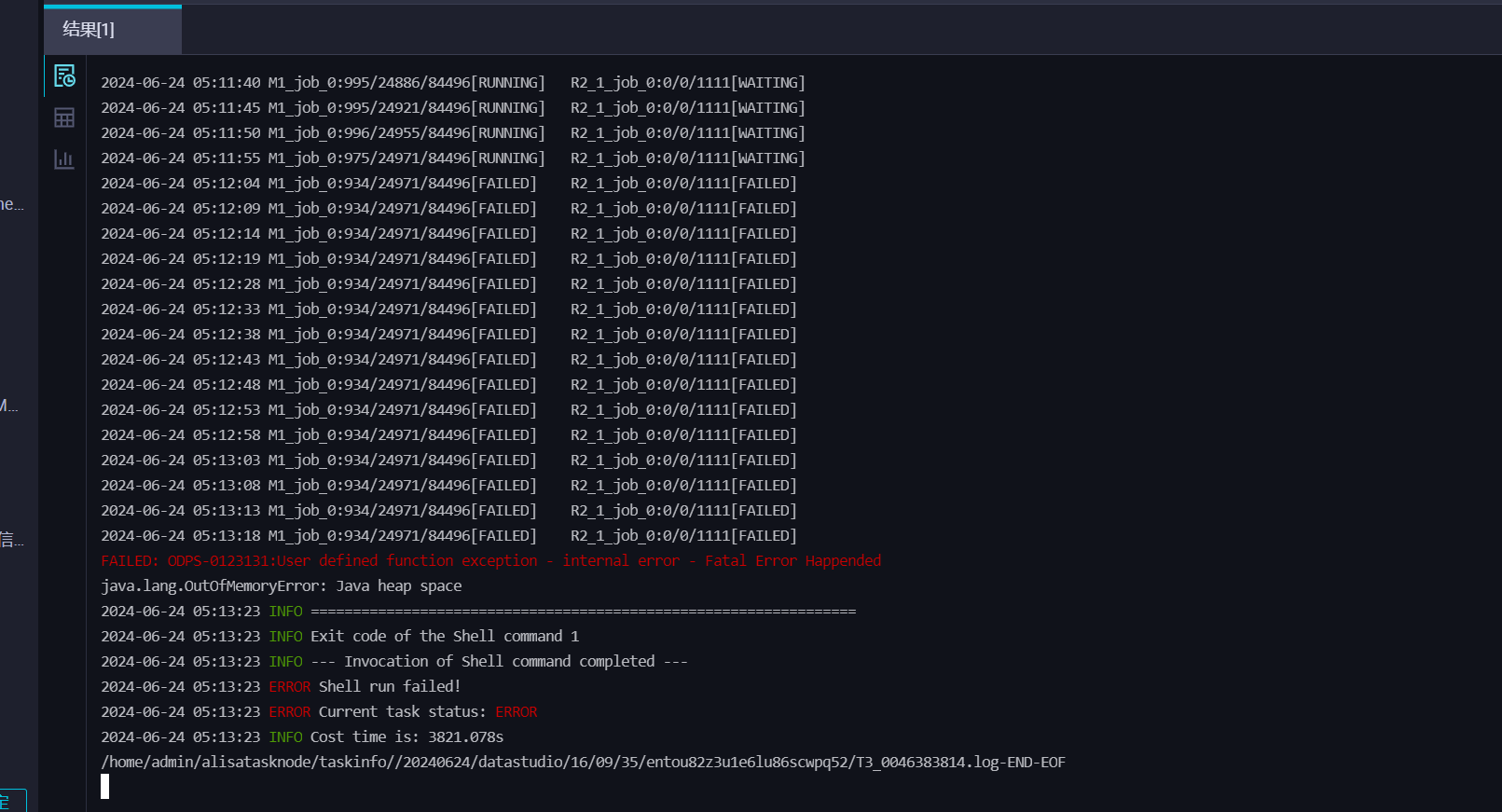
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在DataWorks中查看运行历史时遇到的具体报错信息对于问题的诊断至关重要。然而,您未提供具体的错误消息或日志内容,这使得直接定位问题变得有些困难。尽管如此,仍可以提供一些常见的错误排查步骤和可能的解决方案,以便您能够自行检查和尝试解决问题。下面将围绕通常在DataWorks中遇到的任务执行错误进行分析:
网络连通性问题
白名单设置:如果任务需要连接到外部数据库如Azure,确保在Azure的白名单中添加了正确的IP地址。
内网与公网:确定DataWorks与目标数据库之间的网络是否通过公网还是内网连接。若走公网,则需要使用公网的JDBC地址,并确保独享集成资源组EIP加入到了数据库的白名单中。
资源限制问题
资源组选择:检查是否使用了正确的资源组,并且该资源组拥有足够的资源来执行任务。
扩展资源:对于提示资源不足的错误(如GET_GROUP_SLOT_EXCEPTION),可能需要扩展当前的计算资源或切换到资源更多的独享调度资源组。
权限和授权问题
角色权限:确认当前使用的账号具备足够的权限执行特定操作。在DataWorks中,不同的功能和操作需要相应的权限才能访问和执行。
项目权限限制:即使具有总体权限,若项目级别没有授权,任务也无法执行。请确保你已经被授予了项目级别的适当权限。
任务配置问题
重试与超时设置:对于自动终止的任务,可能是由于超时设置过短导致。手动重启任务或调整超时时间可以解决这一问题。
任务代码大小:如果任务执行报错显示“Argument list too long”,可能是因为执行的代码大小超过了系统限制。需要拆分任务中的SQL代码后重新执行。
数据同步问题
数据源连通性测试:在同步任务之前,进行数据源连通性测试,确保DataWorks可以顺利访问源数据库。
同步策略调整:针对实时同步任务,确保选择了正确的同步策略和资源配置,以减少同步延迟和失败的可能性。
节点和日志问题
查看和管理节点:了解如何在运维中心查看和管理各个节点的运行情况和日志输出,这对于故障排查至关重要。
处理孤立和下线节点:正确处理孤立节点和下线节点,避免因节点管理不善导致的意外错误。
运行历史及日志解析
运行历史记录解读:登录DataWorks控制台,进入相应工作空间的数据开发界面,通过左侧导航栏的运行历史查看最近三天的运行记录。
分析运行日志:通过单击失败的任务,进一步查看详细的运行日志。日志中包含多种有用的参数,如执行机器、执行引擎名称、业务日期、任务ID等。这些信息可以帮助识别问题所在,例如是否是资源不足、权限问题、或是任务配置错误。
常见错误的额外参考
任务执行超时:如果任务执行超时,可以尝试调整任务配置中的超时设置或优化任务中的SQL代码。
权限访问拒绝:对于权限问题导致的访问失败,需要检查项目状态是否启用以及账户是否具有必要的权限。
数据读取错误:如果遇到数据读取相关的问题,检查输入参数是否正确,并确保查询语句合理地限制了返回的数据量。
综上所述,理解和解决DataWorks任务运行中出现的错误需要综合分析多个可能的因素。建议您从检查网络配置、资源分配、权限设置、任务配置开始,同时利用运行历史和日志来获取更详细的错误信息。另外,适时的文档查阅和社区求助也是解决问题的有效途径。
当在DataWorks中点开运行历史并发现报错时,解决这一问题通常需要遵循一系列排查步骤。以下是一些常见的解决策略:
查看错误日志
首先,仔细查看DataWorks控制台中的错误日志。错误日志通常会提供详细的错误信息,包括错误代码、错误描述等,这些信息对于定位问题至关重要。
分析错误类型
根据错误日志中的信息,判断错误的类型。常见的错误类型包括但不限于:
语法错误:检查SQL语句、脚本或配置文件中的语法是否正确。
连接错误:检查数据源连接信息(如数据库地址、端口、用户名、密码等)是否正确,以及网络连接是否正常。
权限错误:确保当前用户具有执行相关操作的权限,检查数据库或表的访问控制设置。
资源不足:如果DataWorks的资源(如CPU、内存、网络带宽等)不足,也可能导致任务运行失败。
数据问题:检查输入数据是否符合预期,包括数据格式、字段名称、数据类型等。
尝试重启任务
如果错误是由于临时问题引起的,尝试重启任务或服务可能会解决问题。在DataWorks控制台中,找到对应的任务实例,尝试重新运行或重启任务。
咨询官方文档或社区
如果以上步骤无法解决问题,可以参考DataWorks的官方文档或社区论坛。在文档中查找类似错误的解决方案,或者在社区中提问寻求帮助。在提问时,提供详细的错误信息和复现步骤,以便他人更好地理解和解决问题。
联系技术支持
如果问题依然无法解决,可以联系DataWorks的技术支持团队。提供详细的错误信息和复现步骤,以便技术支持人员更好地理解和解决问题。
常见问题排查
数据源连通性问题:检查网络配置、防火墙设置等,确保DataWorks能够成功连接到数据源。
数据格式问题:确保输入数据的数据格式与任务配置中的要求一致。
并发控制:如果任务并发量较大,可能导致资源竞争或性能瓶颈,考虑调整并发设置或优化任务逻辑。
通过以上步骤,您应该能够逐步排除错误并找到解决方案。请注意,具体的解决方法可能因错误类型和环境而异,因此在解决问题时需要根据实际情况进行调整和尝试。
您在DataWorks中遇到的错误分为两个部分,我将分别为您解析并提供解决方案:
问题描述:此错误表明Java应用程序在运行过程中耗尽了分配给它的堆内存空间,导致内存溢出。
解决方案:
-Xms(初始堆大小)和-Xmx(最大堆大小)来扩大内存分配。一个示例配置为:-Xms1024m -Xmx1024m,这表示最小和最大堆内存均为1GB。concurrent参数值。问题描述:此错误通常与用户自定义函数(UDF)执行时遇到的内部错误相关,可能是由于权限、依赖问题或环境配置不当导致。
解决方案:
综上所述,解决这两个问题的关键在于调整内存管理配置以避免内存溢出,并确保UDF的正确配置及环境兼容性。
在您提供的日志中,可以看到失败的原因是java.lang.OutOfMemoryError: Java heap space,这通常表示程序在运行过程中耗尽了可用的内存空间,也就是Java堆溢出了。这是由于Java应用程序分配的内存不足以满足其运行需求所导致的问题。您可以尝试:增加JVM堆大小;优化代码;减少并发量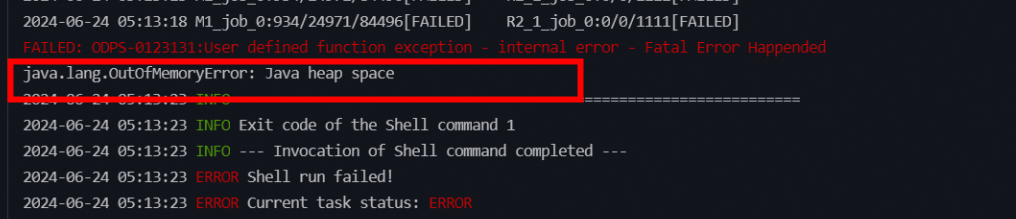
您在DataWorks的任务运行历史中看到的错误信息 "FAILED: oDpS-0123131:User defined function exception -internal error -Fatal Error Happended" 表明在执行用户自定义函数(UDF)时遇到了一个内部错误。这种错误通常是由于UDF代码中的问题或者执行环境的问题引起的。
检查UDF代码:
查看错误堆栈:
调试UDF:
检查环境配置:
查看日志级别:
联系支持:
查看完整的错误信息:
检查UDF:
调试:
环境配置:
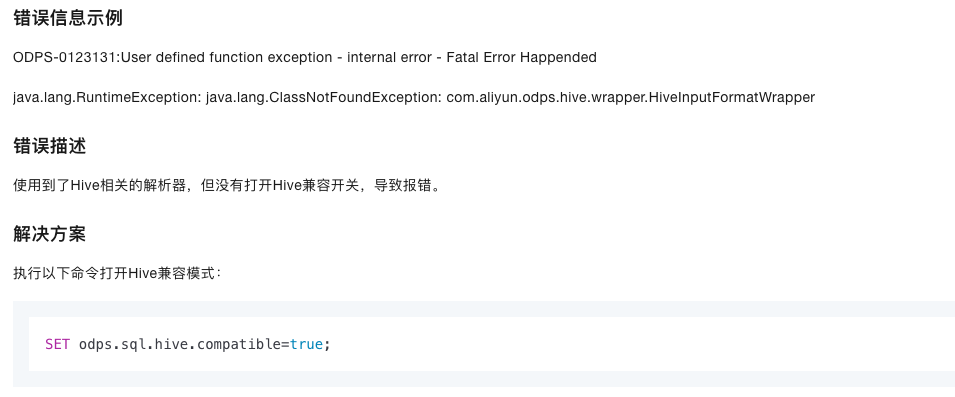
ODPS-0123131:User defined function exception,该错误通常涉及到用户自定义函数(UDF)的使用问题。
使用与向量处理相关的UDF时遇到此错误,可能是由于数据向量的实际维度与UDF配置的预期维度不一致。请检查您的数据,确保每个向量的维度与UDF中设定的维度相匹配。如有必要,调整-vector_separator参数以正确解析向量数据
ODPS-0123131:User defined function exception
模块:PROCESSOR。
严重等级:1。
触发条件:自定义函数异常。
处理方法:修改自定义函数。

参考文档https://help.aliyun.com/zh/maxcompute/user-guide/sql-errors?spm=a2c4g.11186623.0.i216
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。