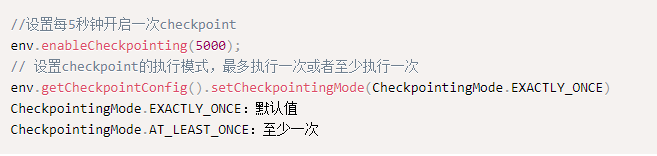
在Flink CDC中checkpoint为什么我设置了3000,它就同步速度很快,我设置3min他就同步速度很慢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink CDC的checkpoint interval设置与同步速度有直接关系。检查点间隔越小,意味着检查点的频率越高,数据同步的速度在单位时间内会更快,因为检查点能更快地捕获和持久化数据变化。反之间隔时间设置得较长,如3分钟,会导致检查点之间的数据积压,同步速度相对变慢。调整检查点间隔应根据作业的处理能力和数据变化速率来平衡,确保既能保证数据一致性,又不会对作业性能产生过大压力。可参考实时计算 Flink版 检查点和快照超时的诊断方法与调优策略
你设置3分钟肯定慢啊...Checkpoint的设置直接影响到数据一致性和故障恢复的速度,同时也关联着作业的运行效率
当你将 checkpoint 设置为更频繁(如每 3 秒)时,Flink 需要更频繁地保存状态,这可能会占用更多的资源(如内存和磁盘 I/O),从而影响处理速度。
状态大小:
如果 Flink 作业的状态很大,频繁的 checkpoint 会增加状态的保存和恢复开销。这可能导致处理速度变慢。
持久化存储系统的性能也会影响 checkpoint 的速度。如果存储系统(如分布式文件系统或数据库)的写入速度较慢,频繁的 checkpoint 会导致同步速度降低。
在Flink CDC中,Checkpoint的设置对同步速度有直接影响。您提到的设置“3000”和“3min”分别代表了两种不同的Checkpoint间隔配置。这里首先需要明确一点,Checkpoint间隔越短,意味着Flink会更频繁地创建检查点来保存作业状态,这样在发生故障时可以更快地恢复,减少数据丢失的风险。
相反,当您将Checkpoint间隔设为“3min”(即3分钟),虽然减少了对系统资源的频繁占用,但这也意味着在两次Checkpoint之间,Flink需要维护更多的状态信息在内存中。如果在这段时间内数据量很大,那么在创建Checkpoint时,需要处理和持久化更多的状态数据,这可能导致Checkpoint过程变慢,甚至因Checkpoint超时而失败,进而影响到整个数据同步的速度和稳定性
此外,根据文档建议,对于大规模数据表的全量同步,应适当增大Checkpoint间隔(如设置execution.checkpointing.interval为10分钟)以避免因Checkpoint频繁触发而导致的Failover问题。同时,合理设置execution.checkpointing.tolerable-failed-checkpoints来容忍一定程度的Checkpoint失败,也是保障作业稳定性的关键策略之一。
相关链接
Postgres CDC(公测中) 注意事项 https://help.aliyun.com/zh/flink/developer-reference/postgresql-cdc-connector
在Flink CDC中,checkpoint的频率设置会影响作业的性能和同步速度。checkpoint的目的是为了在发生故障时能够恢复状态,保证数据的完整性和一致性。
当您设置checkpoint频率为3000毫秒(即每3秒进行一次checkpoint)时,Flink CDC会频繁地保存状态,这有助于快速恢复状态,但也可能会增加作业的开销,因为频繁的状态保存和恢复需要额外的计算资源和存储空间。
相反,当您将checkpoint频率设置为3分钟时,Flink CDC的checkpoint会间隔更长时间,这意味着在发生故障时,可能会有更多的数据丢失,因为恢复状态时只保存最近一次checkpoint之间的数据。但是,较长的checkpoint间隔可能会提高作业的同步速度,因为它减少了状态保存和恢复的开销。
总的来说,checkpoint的频率设置需要根据您的具体需求和可用资源来调整。较短的checkpoint间隔可以提高故障恢复的速度,但可能会增加作业的开销;较长的checkpoint间隔可以提高同步速度,但可能会增加数据丢失的风险。
为了找到最佳的checkpoint频率,您可以尝试不同的设置,并监控作业的性能和状态恢复时间。在实际应用中,可能需要权衡同步速度、数据丢失风险和资源使用效率。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。