大语言模型(Large Language Models,简称LLMs)和知识图谱在人工智能领域扮演着不同但互补的角色,它们之间存在一定的相关性和相似性,同时也存在显著的区别。
相关性与互补性
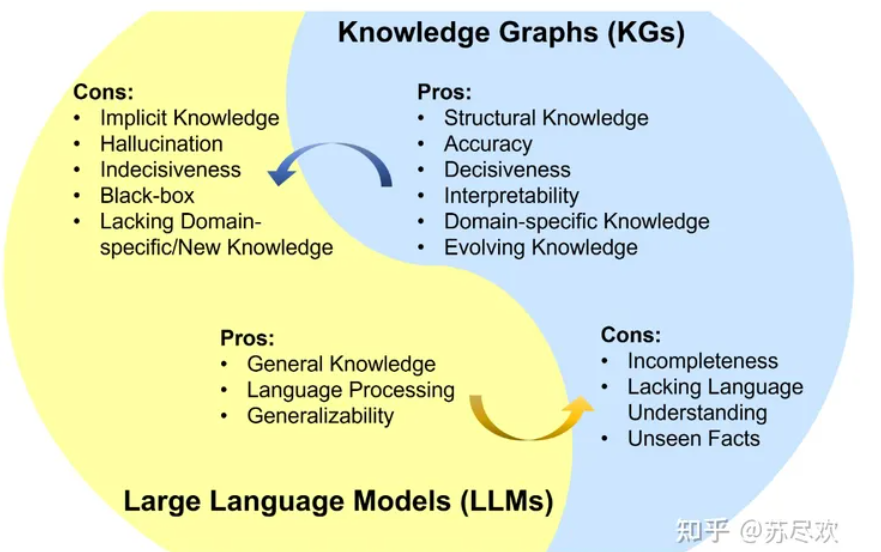
- 信息处理:两者都致力于理解和处理大量的信息。大语言模型通过学习海量文本数据,能够生成连贯、有逻辑的文本,进行问答、翻译、总结等多种自然语言处理任务。知识图谱则是一种结构化的数据组织形式,它以实体-关系-实体三元组的形式存储信息,便于查询和推理,支持复杂的关系分析和知识发现。
- 知识表示:虽然方式不同,但两者都涉及知识的表示。大语言模型通过深度学习自动捕获文本中的模式和关联,隐式地“记住”大量事实和概念。知识图谱则是显式地编码知识,每个节点代表一个实体,边代表实体之间的关系,提供了一种更直接、明确的知识表示方法。
- 应用场景:在某些应用场景中,两者可以结合使用,提升效果。例如,在智能问答系统中,大语言模型可以处理自然语言查询,而知识图谱可以提供精确的事实性答案或辅助模型理解上下文,增强回答的准确性和丰富度。
区别和差异
- 知识表达方式:大语言模型的知识是分布式的,意味着知识分布在模型的权重中,没有明确的结构化表示。而知识图谱是显式结构化的,便于查询和管理特定的知识点。
- 更新维护:知识图谱的更新相对容易控制,可以通过添加或修改三元组来增删改知识。大语言模型一旦训练完成,更新其内部知识需要重新训练或微调,过程更为复杂和资源密集。
- 推理能力:知识图谱天然支持逻辑推理,可以通过图算法进行链式推理,发现新的关系。大语言模型虽然在某些情况下能展现出推理能力,但这种能力通常是基于统计学的,缺乏严格的逻辑基础。
可以参考以下文章:
关于 LLM 和知识图谱、图数据库,大家都关注哪些问题呢?
聊聊 LLM 与知识图谱、图数据库的关系
大型语言模型与知识图谱协同研究综述:两大技术优势互补
知识图谱和大语言模型的共存之道
[论文]统一大语言模型和知识图谱综述


