
云数据仓库ADB一年的数据量大概4000W,如果按年分区是达不到你们的合理性要求,但是不分区后面随着数据上来也是不行的,这种情况应该怎么办?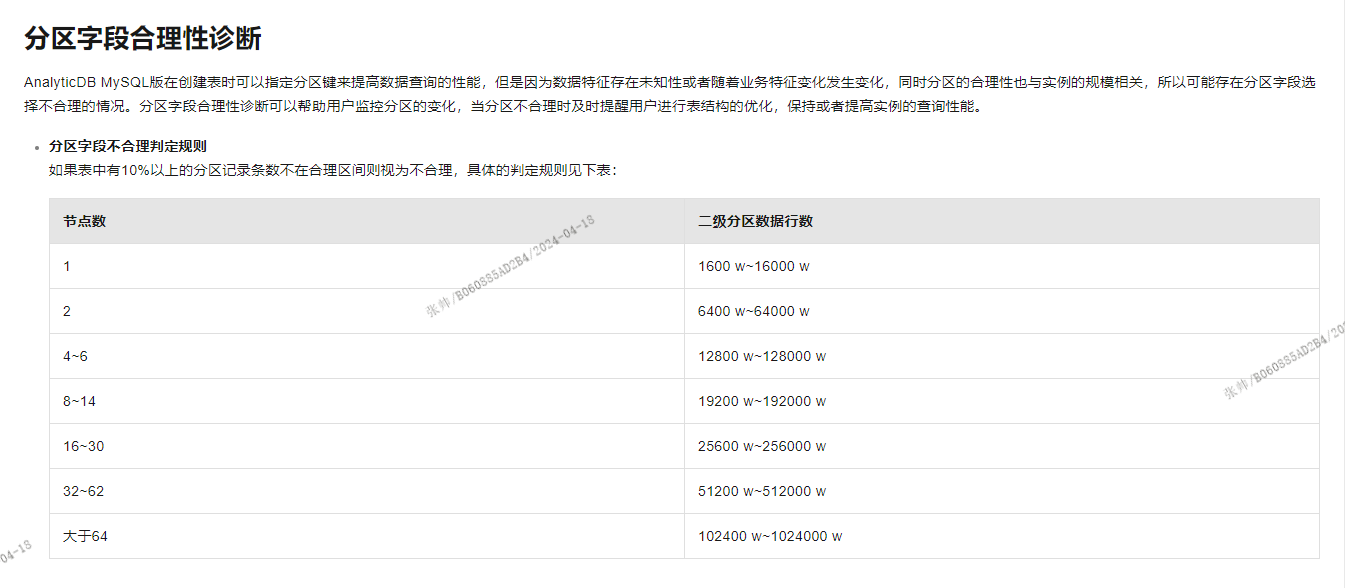
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在云数据仓库AnalyticDB(ADB)中,分区设计的合理性对查询性能和集群稳定性至关重要。根据您提供的场景,数据量为4000万/年,按年分区会导致单个分区的数据量过大,而完全不分区又会在数据增长后影响性能。以下是针对这种情况的专业建议:
根据知识库中的建议,分区大小应与Shard数成正比,合理的分区行数范围为 [100W * N, 500W * N],其中 N 是 Shard 数。假设您的集群 Shard 数为 64,则合理分区行数范围为 [6400万, 32000万]。因此,您可以考虑以下分区策略:
语法示例:
PARTITION BY VALUE(DATE_FORMAT(column_name, '%Y%m'))
此语法将日期字段格式化为 YYYYMM 的形式进行分区。
如果数据具有明确的生命周期(如仅保留最近一年的数据),可以通过 LIFECYCLE 关键字设置表的生命周期管理,自动清理过期分区。例如,设置 LIFECYCLE 365 表示每个节点最多保留 365 天的数据,超出部分会被自动删除。
语法示例:
PARTITION BY VALUE(DATE_FORMAT(column_name, '%Y%m%d')) LIFECYCLE 365
分区键的选择会影响数据分布的均匀性,但分布键的设计同样重要。为了确保数据在各个分片(Shard)之间均匀分布,建议选择高区分度的列作为分布键,例如交易ID、用户ID等。避免使用日期或时间戳类型的列作为分布键,因为这可能导致写入倾斜。
注意事项: - 分布键必须包含在主键中。 - 如果未显式定义分布键,系统会默认将主键作为分布键;如果没有主键,系统会自动生成一个隐藏列作为分布键。
在实际使用中,建议定期通过以下方式检查分区和分布键的合理性: - 分区诊断:通过 information_schema.kepler_partitions 查询分区行数,判断分区大小是否合理。 - 分布键诊断:通过存储空间诊断功能查看数据分布是否均匀,是否存在长尾节点。
查询分区行数示例:
SELECT partition_id, row_count
FROM information_schema.kepler_partitions
WHERE schema_name = '$DB' AND table_name = '$TABLE' AND partition_id > 0;
对于年数据量为 4000 万的场景,推荐采用 按月分区 或 按季度分区 的策略,并结合生命周期管理功能自动清理过期数据。同时,优化分布键设计以确保数据分布均匀,避免写入和查询性能瓶颈。定期利用诊断工具监控分区和分布键的合理性,及时调整设计以适应业务需求的变化。
最终分区设计示例:
CREATE TABLE example_table (
id BIGINT,
event_date DATE,
data STRING,
PRIMARY KEY (id)
)
DISTRIBUTED BY HASH(id)
PARTITION BY VALUE(DATE_FORMAT(event_date, '%Y%m')) LIFECYCLE 365;
通过上述方法,您可以在保证查询性能的同时,有效管理数据增长带来的挑战。
阿里云自主研发的云原生数据仓库,具有高并发读写、低峰谷读写、弹性扩展、安全可靠等特性,可支持PB级别数据存储,可广泛应用于BI、机器学习、实时分析、数据挖掘等场景。包含AnalyticDB MySQL版、AnalyticDB PostgreSQL 版。

