
Flink单独抽几个ck看状态并不单调递增,是不是状态清理不对?
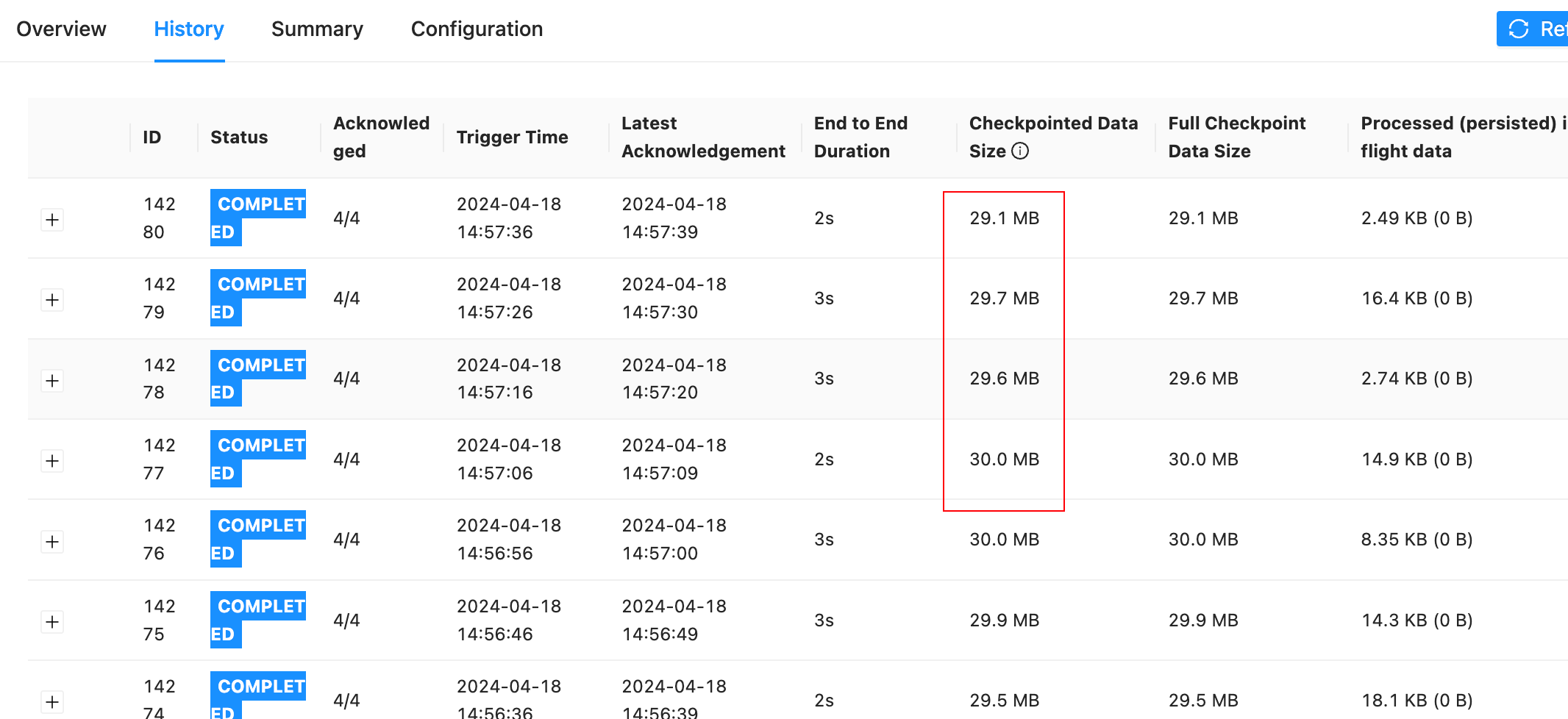
Flink使用interval left join,单独抽几个ck看状态并不单调递增,但是每过一天,ck都比前一天大,运行个几天后就会到几百M了,是不是状态清理不对?理论上应该每天的状态大小都差不多?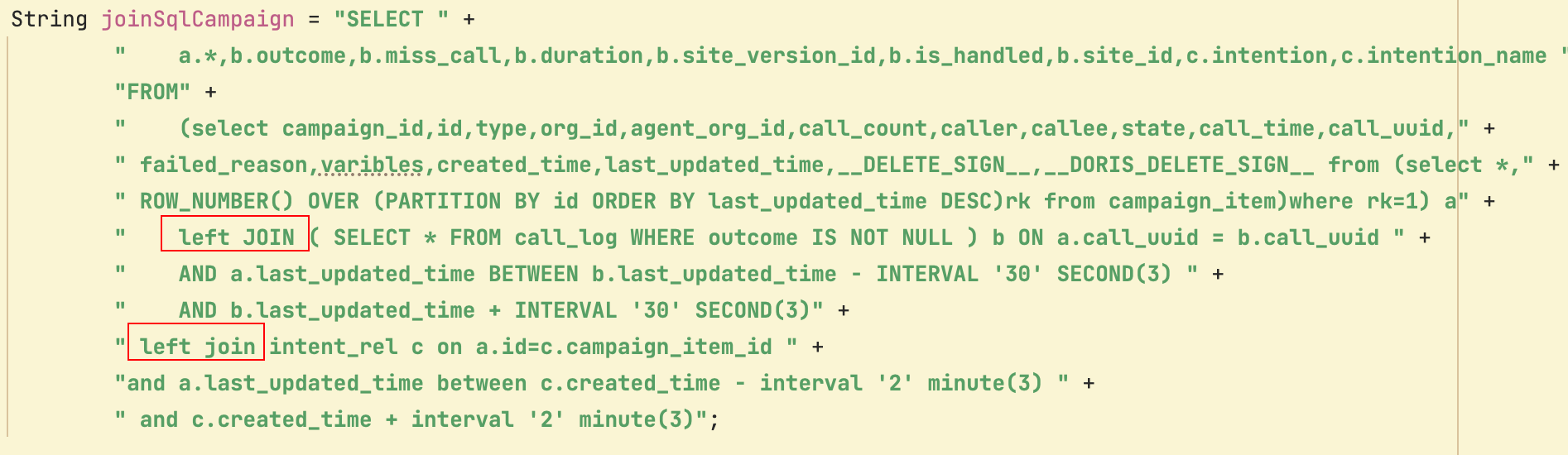

-
 深耕大数据和人工智能
深耕大数据和人工智能Flink中的检查点(checkpoint)状态不单调递增可能是由于状态管理或清理不当导致的。在Flink中,状态管理分为托管状态(Managed State)和原始状态(Raw State)。以下是一些可能导致该问题的原因及建议:
状态数据结构:如果您使用的是原始状态(Raw State),则需要自行管理状态的序列化和反序列化。原始状态只支持字节数组,任何上层数据结构需要序列化为字节数组,这可能导致状态在检查点间不一致。建议使用托管状态,因为Flink可以自动处理常见的数据结构,如ValueState、ListState、MapState等。
状态清理策略:如果状态数据具有时效性,例如某些统计结果只在特定时间内有效,那么应该实现状态的清理逻辑。Flink SQL中可以通过定义状态的TTL(Time-To-Live)来自动清理过期状态。确保您的状态清理策略正确实施,以避免无效或过时的状态数据影响检查点的正确性。
并行度变化:当Flink应用的并行度发生变化时,托管状态会被重新分布到新的并行实例上。如果在这个过程中状态管理不当,也可能导致检查点状态不单调递增。请确保在调整并行度时,状态的迁移和重新分配是正确处理的。
检查点配置:检查点的配置也会影响状态的一致性。例如,检查点间隔、超时设置、最小间隔等参数需要根据具体的作业负载和状态大小进行合理配置。不正确的配置可能导致检查点过程中状态的不一致。
故障恢复:检查点是Flink容错机制的核心,确保故障恢复后的状态与故障前一致。如果检查点过程中发生故障或者网络延迟,也可能导致状态不单调递增。需要检查日志以确定是否有故障发生,并分析故障对检查点的影响。
总的来说,为了解决状态不单调递增的问题,您需要仔细检查状态管理策略,包括选择正确的状态类型、实现适当的状态清理逻辑、正确处理并行度变化以及优化检查点配置。同时,监控Flink作业的运行情况,及时调整相关配置和策略,以确保状态的一致性和准确性。2024-04-23 13:13:13赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
热门讨论
热门文章
相关课程
更多

相关文章
相关电子书
更多


