
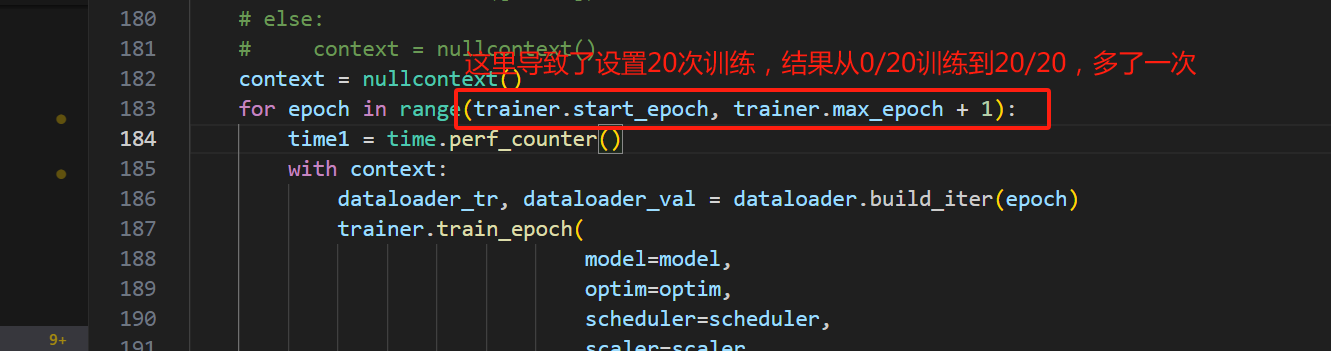
modelscope-funasr中,这里导致设置了20次训练,结果从0/20训练到20/20,多了一次,是不是可以改成:for epoch in range(trainer.start_epoch + 1, trainer.max_epoch + 1): ?
在ModelScope的funasr(Full-featured Automatic Speech Recognition,全功能自动语音识别)项目中,训练轮次计算从1开始到指定的最大轮次结束是常见的做法。您提到的情况,如果训练确实多执行了一次,那可能是因为计数是从0开始的,导致实际训练次数比预期多了一次。
您的修改建议for epoch in range(trainer.start_epoch - 1, trainer.max_epoch - 1):理论上是想解决这个问题,但这里有一个小错误:减去1应该是在范围的结束处,而不是开始处。因为训练的起始epoch应该是包含在内的,所以我们通常保持起始epoch不变,只调整结束条件。正确的修改应为:
for epoch in range(trainer.start_epoch, trainer.max_epoch):
但如果要确保训练恰好执行到max_epoch指定的次数,而不超过,正确的调整方式是让range的上限为trainer.max_epoch - 1,这样当循环到trainer.max_epoch - 1时,正好完成了从1到max_epoch的全部训练周期。因此,修正后的代码应该是:
for epoch in range(trainer.start_epoch, trainer.max_epoch - 1 + trainer.start_epoch):
或者更简洁地表达为:
for epoch in range(trainer.start_epoch, trainer.max_epoch):
如果trainer.start_epoch默认为0,并且你希望总训练次数确实是max_epoch指定的数量,那么直接使用range(trainer.max_epoch)即可,前提是你的框架或训练逻辑能够正确处理这种计数方式。不过,大多数情况下,上述第一种修正方法能更好地匹配多数训练循环的设计逻辑。
