
文字识别OCR这种表格信息抽取准确率不高,需要怎么调整,现在训练测试样本是20个,现在里面识别的文字有的还是错的?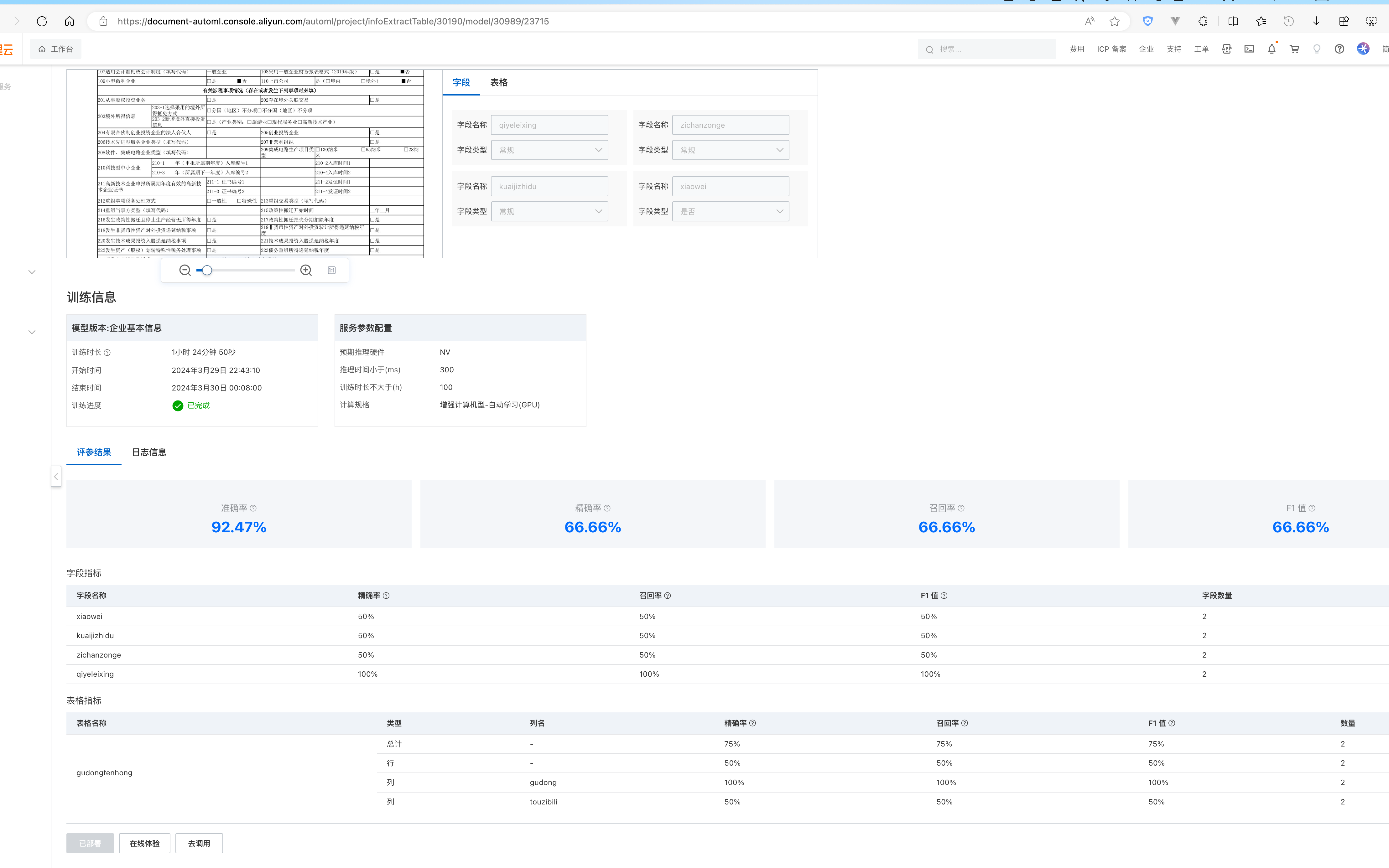
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要提高文字识别OCR表格信息抽取的准确率,您可以从以下几个方面进行调整和优化:
目前您使用的训练测试样本仅有20个,这可能不足以让模型充分学习表格中的特征。建议增加训练数据量,以提升模型的泛化能力: - 建议数据量:根据知识库资料,表格信息抽取建议使用至少20张以上的有效数据进行训练,而长文档信息抽取则建议达到200+份数据才能获得较好的表现。 - 数据类型和版式分布应尽量覆盖真实业务场景,确保模型能够适应多样化的输入。
数据标注的质量直接影响模型的训练效果。以下是优化标注的具体建议: - 字段完整性:确保所有需要识别的字段都被完整标注,避免遗漏关键信息。 - 标注框贴合度:标注框应尽量贴合字段文字,减少冗余区域,从而提高模型对字段位置的敏感性。 - 字段类型配置:在模型训练配置环节,选择合适的字段类型或删除不必要的字段,以提高训练精准度。
如果当前手动划分的训练集和测试集不够科学,可以启用系统提供的「自动划分1/10训练集作为测试集」功能。这样可以避免人为划分导致的数据偏差,同时简化操作流程。
OutputCoordinate="points")。通过以上方法,您可以显著提升表格信息抽取的准确率。如果问题仍未解决,建议联系技术支持团队获取进一步帮助。

