
modelscope-funasr这个失效了之后,如果需要使用非量化的模型,需要怎么设置呢?在我的应用场景量化和非量化准确率还是有一定差距的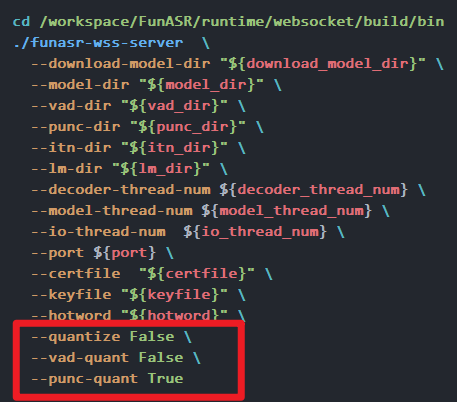
在使用ModelScope-FunASR时,如果需要切换到非量化的模型以避免量化带来的准确率损失,可以按照以下步骤进行设置和操作:
非量化模型通常是指未经任何压缩或精度降低处理的原始浮点模型(如FP32)。在ModelScope中,您可以直接从模型库中获取非量化版本的模型。确保选择的模型版本未经过量化优化。
FP32或未明确标注量化)。在本地环境中,您需要正确安装依赖并加载非量化模型。以下是具体操作步骤:
git clone https://github.com/alibaba-damo-academy/FunASR.git
cd FunASR
确保安装所有必要的依赖包,包括PyTorch和其他相关工具:
pip install -r requirements.txt
在代码中加载非量化模型时,需指定模型路径并确保不启用量化配置。例如:
import torch
from funasr import AutoModel
# 加载非量化模型
model = AutoModel(model="path_to_non_quantized_model")
注意:确保path_to_non_quantized_model指向的是未经过量化的模型文件。
如果您使用的是PAI-Blade或其他量化工具,需明确禁用量化功能以保证模型运行在非量化模式下。
在调用PAI-Blade进行模型优化时,可以通过配置参数禁用量化的执行。例如:
import blade
# 禁用量化优化
optimized_model, opt_spec, report = blade.optimize(
model=original_model,
optimization_level='o0', # 设置为'o0'以禁用优化
device_type='gpu',
test_data=test_data,
calib_data=calib_data
)
在禁用量化后,建议对模型进行精度验证,确保其性能符合预期:
# 验证非量化模型的输出
output = model(input_data)
print(output)
在部署推理服务时,需确保服务配置与非量化模型的要求一致。例如,在ACK或PAI-EAS中部署时,需调整资源分配和环境变量以适配非量化模型的需求。
非量化模型通常对内存和计算资源的需求较高,建议根据模型规模调整实例规格: - 普通Pipeline模型:内存不低于8 GB。 - 大语言对话模型:建议选择GPU实例(如ml.gu7i.c16m60.1-gu30)。
在部署服务时,确保环境变量中未启用量化相关的配置。例如:
MODEL_ID=iic/nlp_csanmt_translation_en2zh
TASK=translation
REVISION=v1.0.1
完成上述设置后,需对非量化模型进行充分的测试,确保其准确率满足应用需求。
通过WebUI界面测试模型输出: 1. 单击服务页面中的查看Web应用。 2. 在测试内容框中输入请求数据,单击执行测试,观察返回结果。
使用API接口发送请求,验证模型输出是否符合预期。例如:
curl -XPOST http://localhost:8000/generate \
-H "Content-Type: application/json" \
-d '{"text_input": "什么是人工智能?", "parameters": {"stream": false}}'
通过以上步骤,您可以成功切换到非量化模型,并确保其在您的应用场景中正常运行。
