
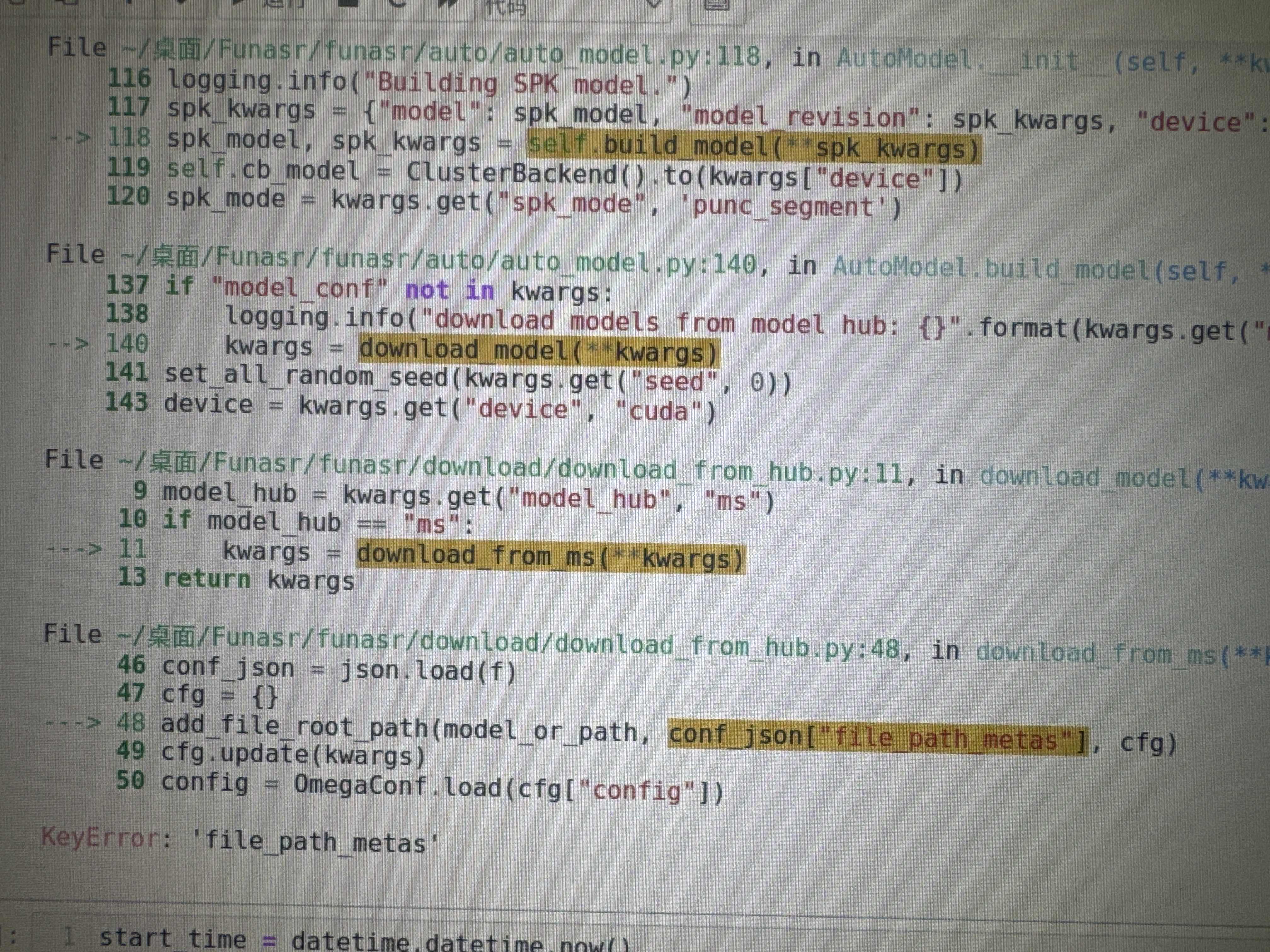
speech_eres2net_base_200k_sv_zh-cn_16k-common modelscope-funasr的这个模型能使用automodel 加载吗? 我这边显示找不到这个模型的下载信息
根据您提供的信息,speech_eres2net_base_200k_sv_zh-cn_16k-common 是一个来自 ModelScope 的模型。您提到尝试使用 AutoModel 加载该模型时,系统提示找不到该模型的下载信息。以下是针对此问题的详细解答和建议:
首先,您需要确认该模型是否确实存在于 ModelScope 平台中。根据知识库中的参考资料,ModelScope 提供了支持的模型服务列表,但并未列出 speech_eres2net_base_200k_sv_zh-cn_16k-common 这一具体模型。因此,可能存在以下两种情况: - 模型未公开发布:如果该模型是私有或非公开模型,则无法通过 AutoModel 直接加载,需要额外配置访问令牌(ACCESS_TOKEN)。 - 模型名称错误:请检查模型 ID 是否正确,确保与 ModelScope 平台上的实际模型名称完全一致。
如果您确认该模型存在于 ModelScope 平台中,可以尝试以下方法加载模型:
ModelScope 提供了专门的 SDK 来加载模型。您可以按照以下步骤操作: 1. 安装 ModelScope SDK:
pip install modelscope
使用 AutoModel 加载模型:
from modelscope import AutoModel, AutoTokenizer
model_id = "speech_eres2net_base_200k_sv_zh-cn_16k-common"
model = AutoModel.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
如果模型为非公开模型,请确保已配置访问令牌(ACCESS_TOKEN),并将其添加到环境变量中:
export ACCESS_TOKEN="your_access_token"
如果 AutoModel 无法自动找到模型的下载信息,您可以尝试手动下载模型文件并加载: 1. 登录 ModelScope 平台,进入目标模型页面,获取模型的下载链接。 2. 下载模型文件并解压到本地目录。 3. 使用本地路径加载模型:
model = AutoModel.from_pretrained("/path/to/local/model")
tokenizer = AutoTokenizer.from_pretrained("/path/to/local/model")
根据您的描述,系统提示“找不到该模型的下载信息”,可能的原因及对应解决方案如下:
如果该模型是非公开模型,则需要配置访问令牌(ACCESS_TOKEN)。请参考以下步骤: 1. 在 ModelScope 首页左侧导航栏中,单击 访问令牌,获取 SDK 访问令牌。 2. 将访问令牌配置到环境变量中:
export ACCESS_TOKEN="your_access_token"
请仔细核对模型 ID 是否正确。如果不确定模型名称,可以在 ModelScope 平台上搜索相关任务类型(如语音识别、语音合成等),找到正确的模型 ID。
如果您的网络环境无法访问 ModelScope 的模型存储服务器,可能会导致下载失败。建议检查网络连接,并确保能够正常访问 ModelScope 平台。
model = AutoModel.from_pretrained("speech_eres2net_base_200k_sv_zh-cn_16k-common", revision="v1.0.0")
如果未指定版本,默认会尝试加载最新版本,可能导致加载失败。
如果 speech_eres2net_base_200k_sv_zh-cn_16k-common 模型无法通过 AutoModel 加载,建议按照以下步骤排查问题: 1. 确认模型是否公开,若为非公开模型,请配置访问令牌。 2. 核对模型 ID 和版本是否正确。 3. 检查网络连接是否正常。 4. 若问题仍未解决,可尝试手动下载模型文件并加载。
希望以上信息能帮助您解决问题!如有进一步疑问,请随时提供更多信息以便我们协助您。
