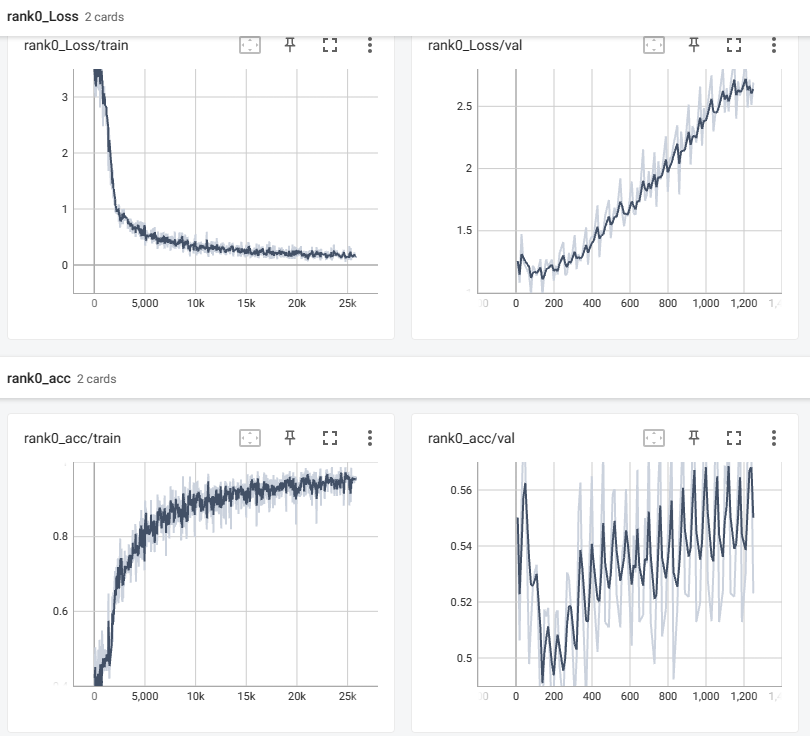
在使用ModelScope-FunASR进行训练时,如果训练集拟合得较好但验证集表现较差(即出现过拟合现象),可以通过以下方法来解决。这些方法旨在提升模型的泛化能力,使其在未见过的数据上表现更好。
1. 增加数据量
- 扩充训练数据:验证集表现差可能是因为训练数据不足或分布不均。尝试收集更多样化的数据,尤其是与验证集分布相似的数据。
- 数据增强:对现有数据进行增强处理,例如添加噪声、调整语速、改变音调等,以提高模型对不同场景的适应能力。
2. 正则化技术
- L2正则化:在损失函数中加入权重衰减项(L2正则化),限制模型参数的大小,防止过拟合。
- Dropout:在模型的关键层(如全连接层或注意力机制层)中引入Dropout,随机丢弃部分神经元,降低模型对特定特征的依赖性。
- 早停法(Early Stopping):在验证集性能不再提升时提前停止训练,避免模型过度拟合训练数据。
3. 调整模型复杂度
- 简化模型结构:如果模型过于复杂,可能会导致过拟合。可以尝试减少模型层数或隐藏单元数量,降低模型容量。
- 迁移学习:使用预训练模型(如FunASR提供的预训练权重)进行微调,而不是从头训练,这样可以利用大规模数据中学到的通用特征。
4. 优化训练策略
- 学习率调整:使用动态学习率调度器(如Cosine Annealing或ReduceLROnPlateau),根据验证集性能动态调整学习率。
- Batch Size调整:适当增大Batch Size可以提高训练稳定性,但需注意显存限制。
- 混合精度训练:通过混合精度训练(Mixed Precision Training)加速收敛并减少过拟合风险。
5. 改进验证集评估
- 检查验证集分布:确保验证集与训练集的分布一致。如果验证集包含训练集中未覆盖的场景或噪声类型,模型可能无法很好地泛化。
- 交叉验证:采用K折交叉验证,确保模型在不同数据划分下的稳定性。
6. 后处理优化
- 解码策略调整:FunASR支持多种解码策略(如Beam Search、CTC Prefix Beam Search)。尝试调整解码参数(如Beam Size)以提升验证集性能。
- 语言模型融合:在解码阶段引入外部语言模型(LM),通过结合声学模型和语言模型的输出,提升识别准确率。
7. 监控与调试
- 可视化训练过程:使用工具(如TensorBoard)监控训练和验证损失曲线,及时发现过拟合趋势。
- 分析错误样本:对验证集中的错误样本进行分析,找出模型的薄弱环节,并针对性地优化。
示例代码:数据增强与Dropout应用
以下是一个简单的示例,展示如何在训练过程中应用数据增强和Dropout:
from funasr import train
# 数据增强配置
data_augmentation = {
"noise": {"snr": (10, 20)}, # 添加随机噪声
"speed_perturb": {"factor": (0.9, 1.1)} # 调整语速
}
# 模型配置
model_config = {
"encoder": "conformer",
"decoder": "transformer",
"dropout_rate": 0.2 # 添加Dropout
}
# 开始训练
train(
data_augmentation=data_augmentation,
model_config=model_config,
early_stopping_patience=5 # 早停法
)
总结
通过上述方法,您可以有效缓解FunASR模型在验证集上的过拟合问题。建议优先从数据增强和正则化入手,同时结合模型结构调整和训练策略优化,逐步提升模型的泛化能力。