
Flink哪个大神来个助攻呗,这是什么情况啊?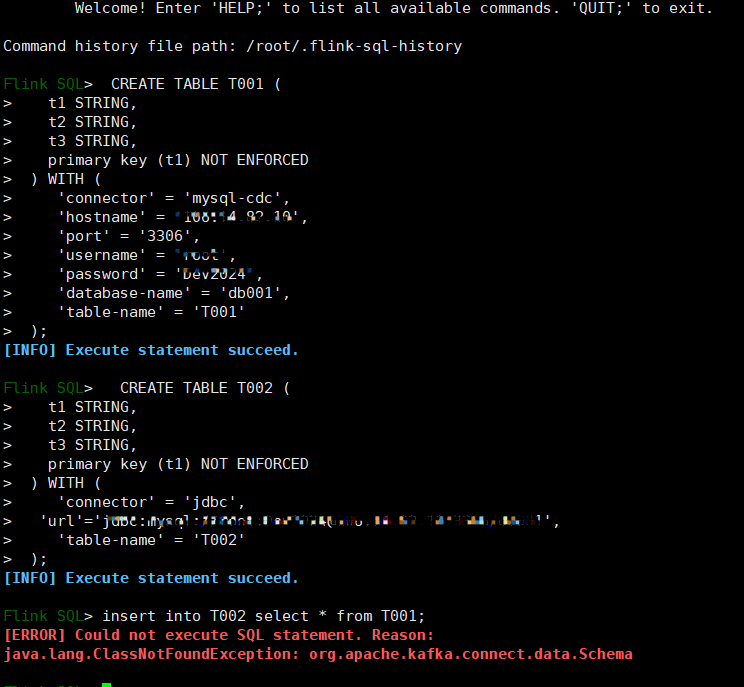
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Apache Flink中,如果遇到与org.apache.kafka.connect.data.schema相关的错误,通常是因为Flink在处理来自Kafka或其他使用Kafka Connect格式的数据时出现了Schema不匹配或解析问题。Kafka Connect数据模型包括了对消息结构的描述,也就是Schema,用于确保数据序列化和反序列化的正确性。
以下是一些可能出现这类错误的原因及相应的解决措施:
当源数据表结构发生改变(如添加、删除或重命名列)而Flink CDC没有及时更新其内部持有的Schema信息时,可能会导致Schema不匹配的错误。
解决方案:重新同步Schema信息或者配置Flink CDC以自动适应Schema变更。
如果消息体中的某个字段值缺失,但Flink期望该字段存在且非空,会抛出类似“Datarow is smaller than a column index”这样的错误。
解决方案:检查并调整Flink CDC的配置,确保能够正确处理字段缺失的情况,例如启用容忍度模式或者过滤掉不需要的字段。
如果实际数据的类型与Flink任务中定义的Schema类型不一致,会出现“Invalid value: used for required field"之类的错误。
解决方案:验证并更新Flink作业中的Schema定义,使其与实际数据的Schema保持一致。
Kafka Connect Schema可能存在嵌套结构,如果Flink在解析这种复杂结构时出现问题,也会导致错误。
解决方案:确保Flink能够正确处理嵌套的Schema结构,并进行适当的类型转换。
如果使用了自定义的Serializer/Deserializer(Serde),可能存在Serde逻辑错误导致无法正确解析或生成符合预期Schema的消息。
解决方案:检查并修复自定义Serde代码,确保它能正确处理所有可能的数据场景。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



