
"You are using the default legacy behaviour of the . This is expected, and simply means that the legacy (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set legacy=False. This should only be set if you understand what it means, and thouroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
D:\Program Files\Python311\Lib\site-packages\transformers\convert_slow_tokenizer.py:473: UserWarning: The sentencepiece tokenizer that you are converting to a fast tokenizer uses the byte fallback option which is not implemented in the fast tokenizers. In practice this means that the fast version of the tokenizer can produce unknown tokens whereas the sentencepiece version would have converted these unknown tokens into a sequence of byte tokens matching the original piece of text.
warnings.warn(
D:\Program Files\Python311\Lib\site-packages\transformers\modeling_utils.py:942: FutureWarning: The device argument is deprecated and will be removed in v5 of Transformers.
warnings.warn(
D:\Program Files\Python311\Lib\site-packages\transformers\modeling_utils.py:896: FutureWarning: The device argument is deprecated and will be removed in v5 of Transformers.
warnings.warn(
Traceback (most recent call last):
File ""e:\python_workspaces\text_classification\src\model\train.py"", line 67, in
train_test(
File ""e:\python_workspaces\text_classification\src\model\train.py"", line 63, in train_test
trainer.train()
File ""D:\Program Files\Python311\Lib\site-packages\modelscope\trainers\trainer.py"", line 711, in train
self.train_loop(self.train_dataloader)
File ""D:\Program Files\Python311\Lib\site-packages\modelscope\trainers\trainer.py"", line 1233, in train_loop
self.train_step(self.model, data_batch)
File ""D:\Program Files\Python311\Lib\site-packages\modelscope\trainers\trainer.py"", line 878, in train_step
train_outputs = model.forward(inputs)
^^^^^^^^^^^^^^^^^^^^^^^
File ""D:\Program Files\Python311\Lib\site-packages\modelscope\models\nlp\T5\text2text_generation.py"", line 376, in forward
loss = loss_fct(
^^^^^^^^^
File ""C:\Users\Administrator\AppData\Roaming\Python\Python311\site-packages\torch\nn\modules\module.py"", line 1511, in _wrapped_call_impl
return self._call_impl(*args, kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ""C:\Users\Administrator\AppData\Roaming\Python\Python311\site-packages\torch\nn\modules\module.py"", line 1520, in _call_impl
return forward_call(args, *kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ""C:\Users\Administrator\AppData\Roaming\Python\Python311\site-packages\torch\nn\modules\loss.py"", line 1179, in forward
return F.cross_entropy(input, target, weight=self.weight,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File ""C:\Users\Administrator\AppData\Roaming\Python\Python311\site-packages\torch\nn\functional.py"", line 3059, in cross_entropy
return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: expected scalar type Long but found Int modelscope中,在训练的时候报出以上问题了?
文本分类模型:iic/nlp_mt5_zero-shot-augment_chinese-base"
"貌似是windows上torch的原因。参考一下其他开发者改torch代码functional.py 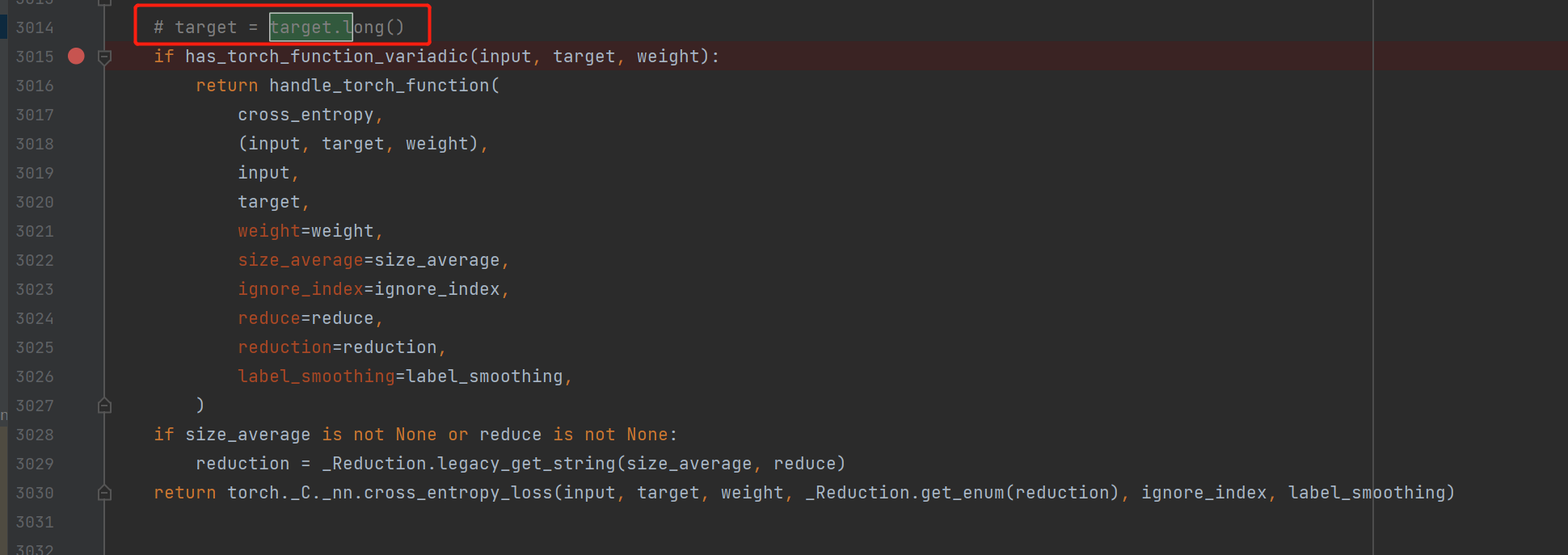
此回答整理自钉群“魔搭ModelScope开发者联盟群 ①”"
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352
