
Flink CDC 里有见过这个问题的吗 生产用的好好的 突然挂了 重新发布作业也不行。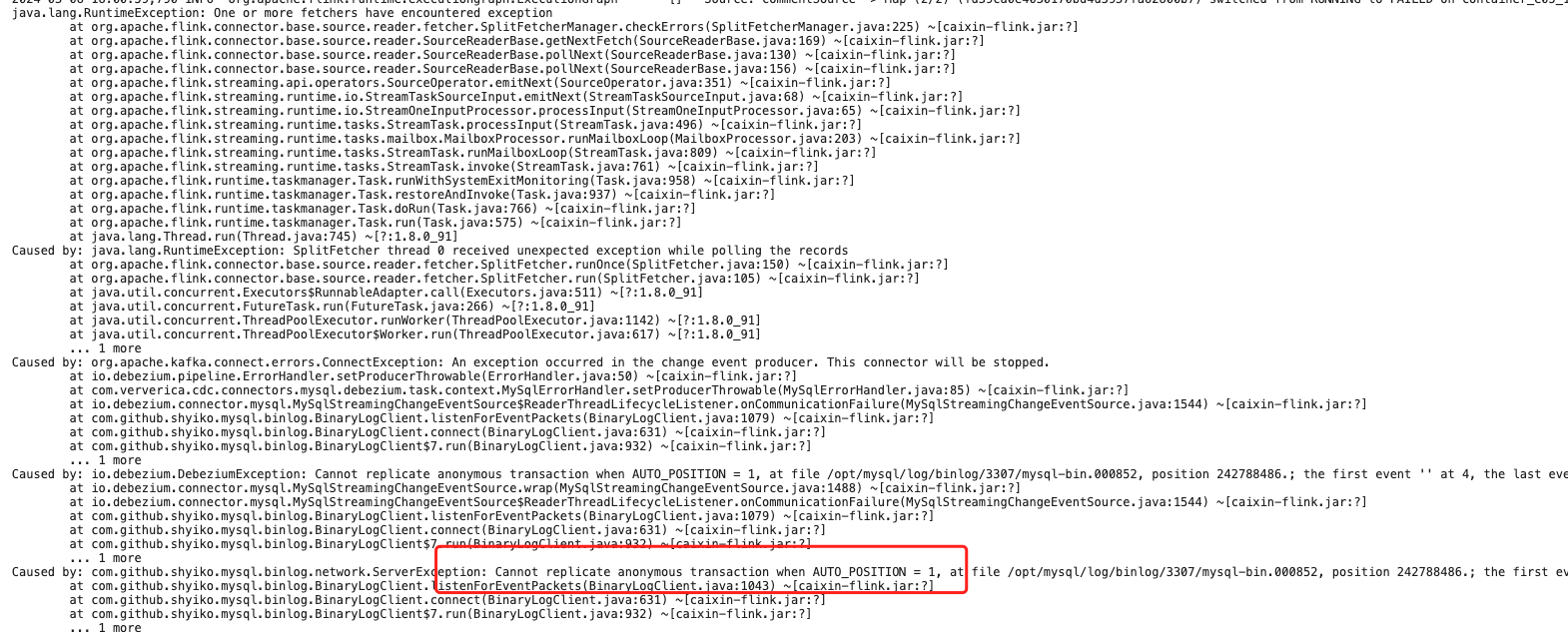
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题“Flink CDC 作业在生产环境中突然挂掉,且重新发布作业也无法恢复”,结合知识库中的相关资料,以下是可能的原因分析及解决方案:
REPLICATION SLAVE 或 REPLICATION CLIENT),导致无法读取 Binlog 数据。检查 MySQL 的 Binlog 文件是否完整:
SHOW BINARY LOGS;
确保作业需要的 Binlog 文件未被清理。如果已被清理,可以尝试从最新的 Binlog 位点重新启动作业。
检查数据库用户的权限:
SHOW GRANTS FOR 'userName'@'host';
确保用户具有以下权限: - SELECT - REPLICATION SLAVE - REPLICATION CLIENT
检查网络连通性,确保 Flink 集群能够正常访问 MySQL 数据库。
finish split response timeout 异常,进而导致作业挂掉。SET 'table.optimizer.source-merge.enabled' = 'true';
注意:开启 Source 复用后,建议保持 pipeline.operator-chaining 为默认值(true),以避免序列化和反序列化的额外开销。
SET 'table.exec.source.cdc-events-duplicate' = 'true';
server-time-zone 参数不一致,可能导致时间戳字段解析错误。SET 'server-time-zone' = 'Asia/Shanghai';
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 2
restart-strategy.fixed-delay.delay: 10 s
如果问题仍未解决,请提供更详细的错误日志信息,以便进一步分析和定位问题。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

