
Flink这个问题怎么解决?datahub connector中sql是支持配置hashFields的,但是Datastream API DatahubSourceFunction中为啥没有hashFields配置的参数 https://help.aliyun.com/zh/flink/developer-reference/datahub-connector?spm=a2c4g.11186623.0.0.4b73fa0ccNa3kV 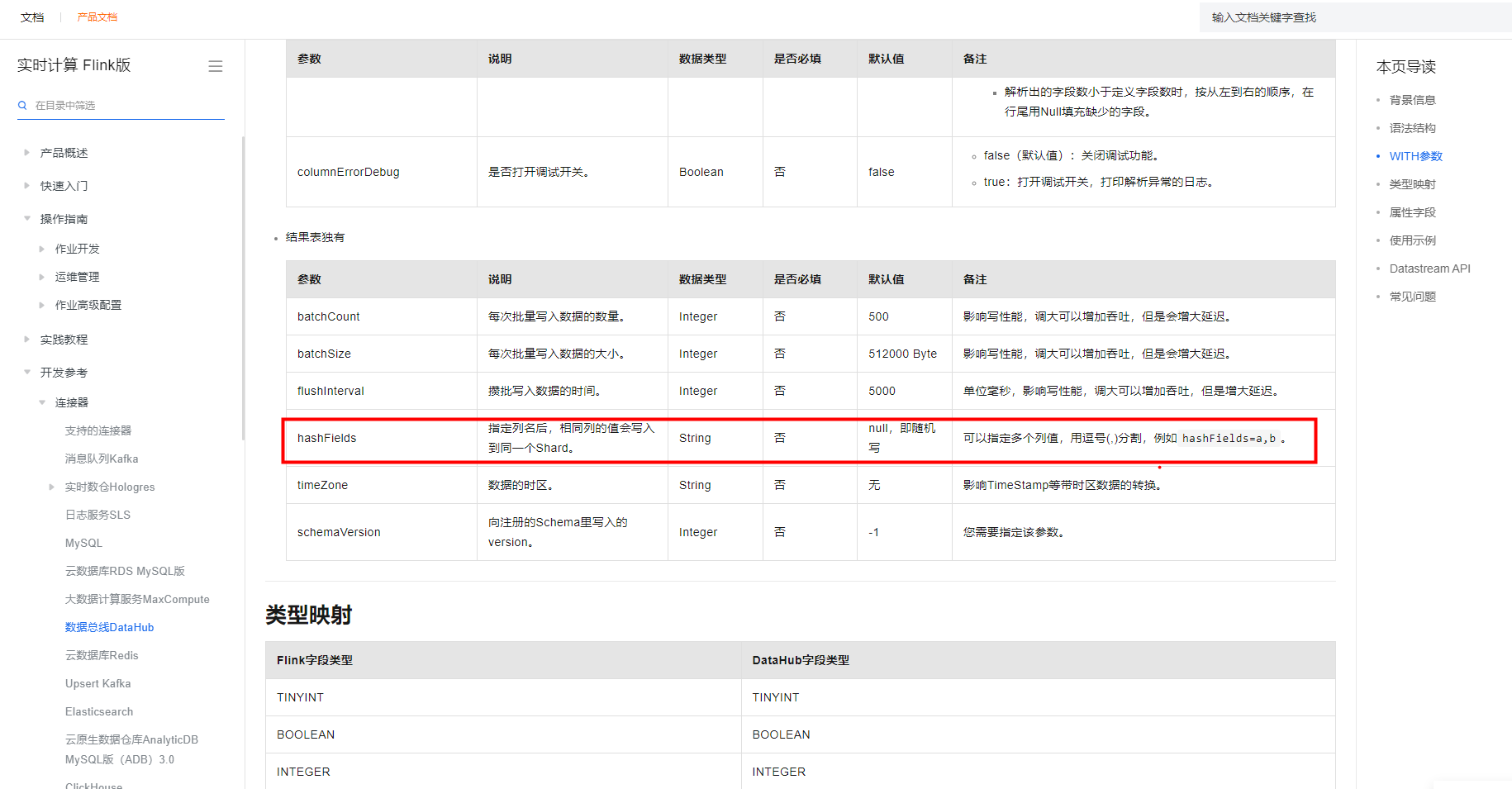
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink中,Datahub Connector的SQL接口和Datastream API中的DatahubSourceFunction确实存在一些差异。如果在使用DatahubSourceFunction时需要配置hashFields,可以通过以下步骤进行操作:
DatahubSourceFunction:在您的Flink作业中,创建DatahubSourceFunction实例。这个函数用于从Datahub中读取数据。DatahubSourceFunction:在创建DatahubSourceFunction实例后,您需要对其进行配置。其中,setHashFields方法可以用于指定hashFields。这个方法接受一个字符串数组作为参数,表示要用作hash分区的字段。DatahubSourceFunction:将配置好的DatahubSourceFunction应用到Flink的数据流中,以便从Datahub中读取数据并进行后续处理。需要注意的是,具体的API和配置选项可能会根据Datahub Connector的版本而有所不同。因此,建议您查阅Datahub Connector的官方文档或参考示例代码,以获取最准确的信息和指导。
在Flink中,DatahubSourceFunction没有hashFields配置参数的问题可以通过以下方式解决:
总之,您可以通过上述方法来解决Flink中DatahubSourceFunction没有hashFields配置参数的问题。如果您选择自定义实现,请确保对DataHub的操作有足够的了解,并考虑到性能和稳定性的因素。
目前还不支持,简单绕过的方案是在sink前keyby一下,但是这是有额外的开销。此回答整理自钉群“实时计算Flink产品交流群”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


