
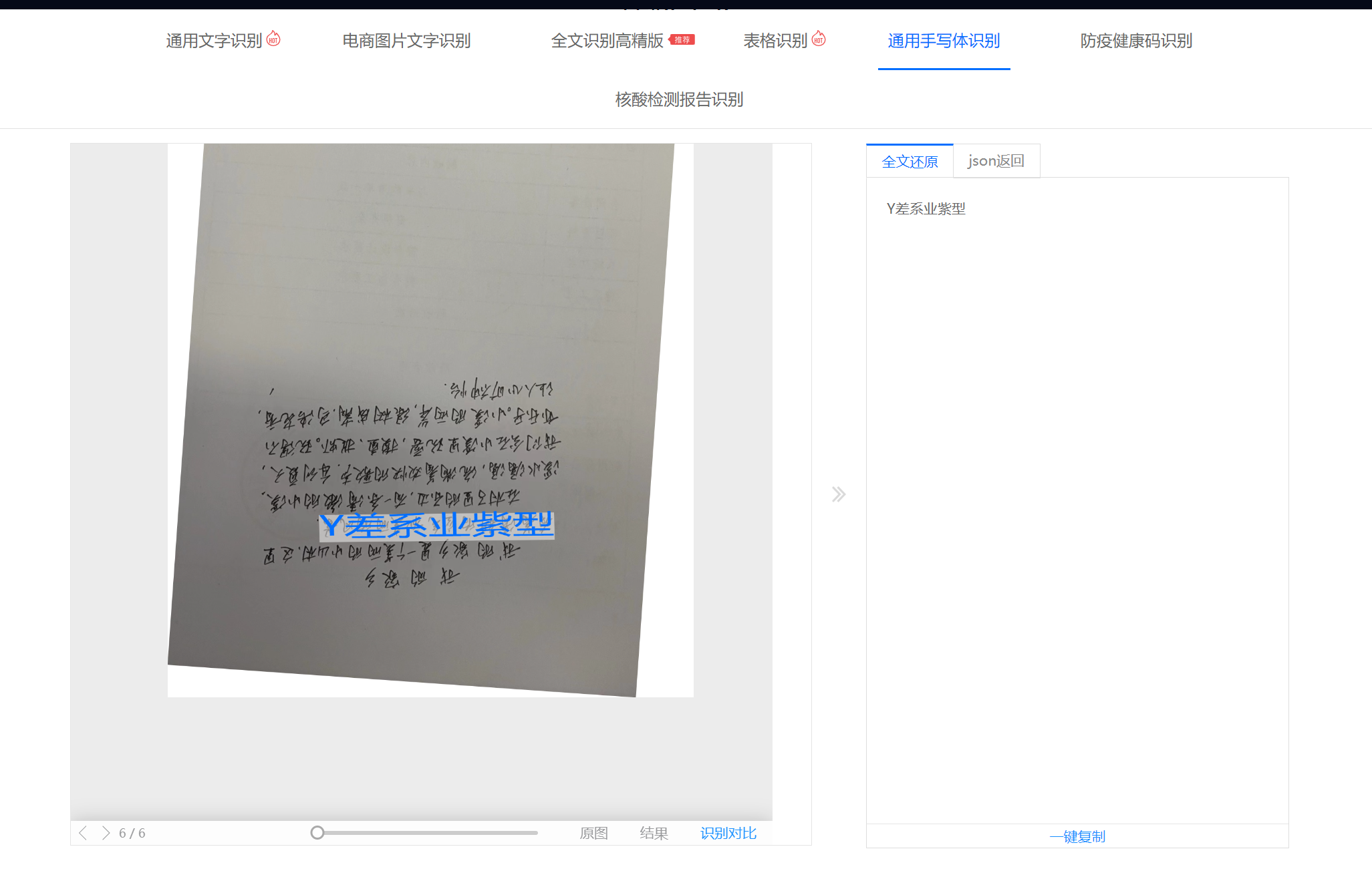
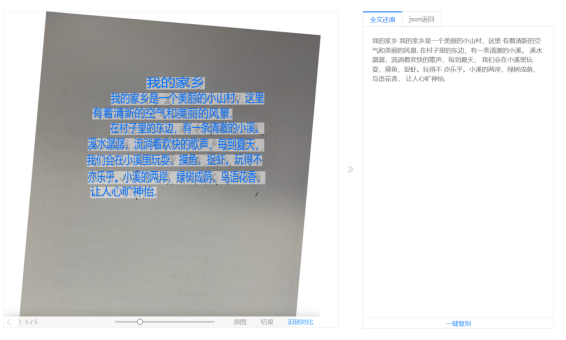
用文字识别OCR识别同样一篇文章,为啥我年前和年后调用接口返回的结果不一样?年前还能自动识别旋转。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
OCR(Optical Character Recognition,光学字符识别)技术是一种将图像中的文字转换为可编辑文本的技术。然而,由于OCR技术的局限性和复杂性,不同时间段调用接口返回的结果可能会有所不同。以下是可能导致这种差异的一些原因:
图像质量:图像的清晰度、对比度和亮度等因素会影响OCR的准确性。如果图像质量较差或存在噪声干扰,可能会导致OCR结果不准确。
文字排版:文字的排版方式也会影响OCR的准确性。例如,文字排列整齐、字体统一且清晰的情况下,OCR结果通常更准确。而如果文字排列混乱、字体不一致或模糊不清,可能会导致OCR结果出现错误。
OCR算法更新:OCR技术在不断改进和发展,不同的OCR服务提供商可能使用不同的算法和模型进行文字识别。因此,不同时间段调用接口时,使用的OCR算法版本可能不同,导致结果有所差异。
数据源变化:如果OCR识别的是网络上的文章,那么文章的内容可能会随着时间的推移发生变化。这可能是因为作者对文章进行了修改、删除或添加新内容,或者因为网站更新了文章内容。


