
modelscope-funasr单独使用这个 vad model 会报 assert error,怎么解决?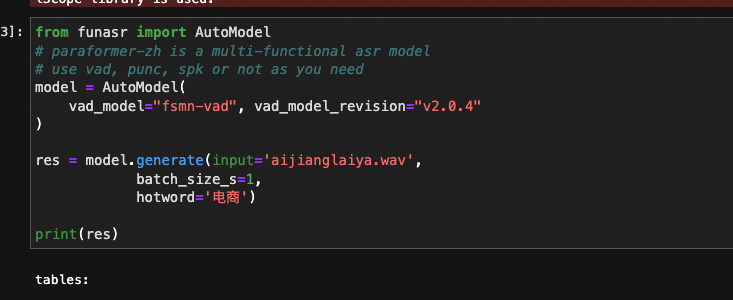
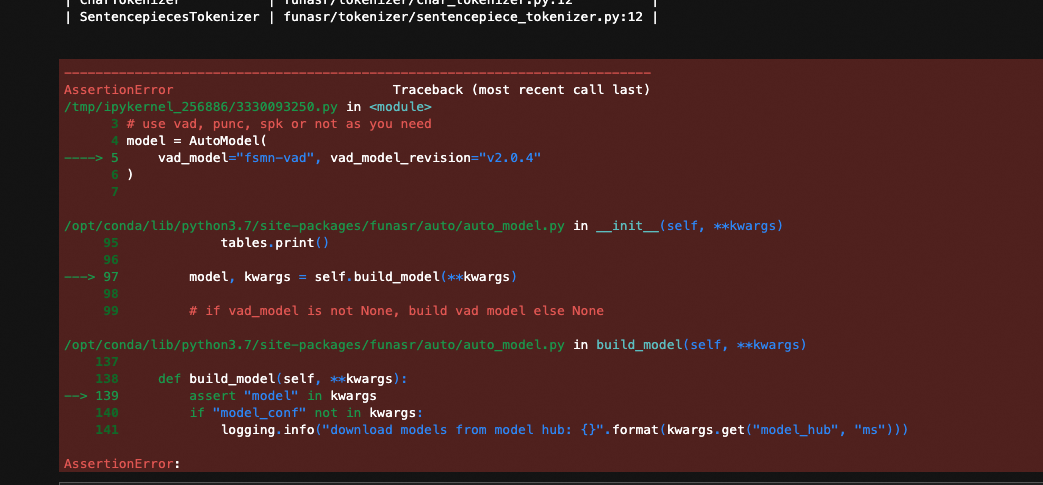
在使用 modelscope-funasr 的 VAD(Voice Activity Detection,语音活动检测)模型时,如果遇到 assert error 报错,可能是由于以下原因导致的。以下是详细的解决方法和步骤:
modelscope-funasr 的 VAD 模型依赖于特定版本的 Python 和 PyTorch 等库。如果依赖版本不匹配,可能会导致断言错误。
modelscope-funasr 兼容。modelscope-funasr 的依赖包时,请严格按照官方文档中的要求执行以下命令:
pip install -r requirements.txt
pip install funasr[clip]
VAD 模型的配置文件可能包含一些默认参数或路径设置。如果这些配置文件缺失、路径错误或内容不符合预期,可能会触发断言错误。
FunASR/funasr/configs/vad/default.yaml
如果配置文件路径有误,请手动指定正确的路径。例如,在调用 VAD 模型时,可以通过参数显式传递配置文件路径:
from funasr import AutoModel
model = AutoModel(model="vad_model_path", config="config_file_path")
VAD 模型对输入音频数据的格式有严格要求。如果输入数据的采样率、通道数或其他属性不符合模型的预期,可能会导致断言错误。
确保输入音频数据的采样率为 16kHz,并且为单声道(mono)。如果音频不符合要求,可以使用工具(如 librosa 或 pydub)进行预处理:
import librosa
# 加载音频并转换为16kHz单声道
audio, sr = librosa.load("input_audio.wav", sr=16000, mono=True)
如果模型初始化失败,可能会导致后续调用时出现断言错误。
在初始化模型后,添加调试信息以确认模型加载是否成功。例如:
from funasr import AutoModel
model = AutoModel(model="vad_model_path", config="config_file_path")
print("Model loaded successfully.")
MODEL_ID 和 TASK 参数。ACCESS_TOKEN(如果模型需要认证)。modelscope-funasr 可能存在已知问题,这些问题可能已在最新版本中修复。
modelscope-funasr 到最新版本:
pip install --upgrade funasr
git clone https://github.com/alibaba-damo-academy/FunASR.git
cd FunASR
pip install -e .
如果上述方法均未解决问题,请根据报错信息进一步定位问题。
try:
# 调用 VAD 模型
result = model(audio)
except AssertionError as e:
print(f"AssertionError: {e}")
如果问题仍未解决,建议联系阿里云技术支持团队,提供以下信息以便快速定位问题: - 完整的错误日志。 - 使用的模型版本和配置文件。 - 输入数据的格式和示例。
通过以上步骤,您应该能够解决 modelscope-funasr 中 VAD 模型的 assert error 问题。如果仍有疑问,请随时提供更多上下文信息,我们将进一步协助您解决问题。
