
modelscope-funasr这个模型,用范例执行会报错,是哪里的问题?iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn 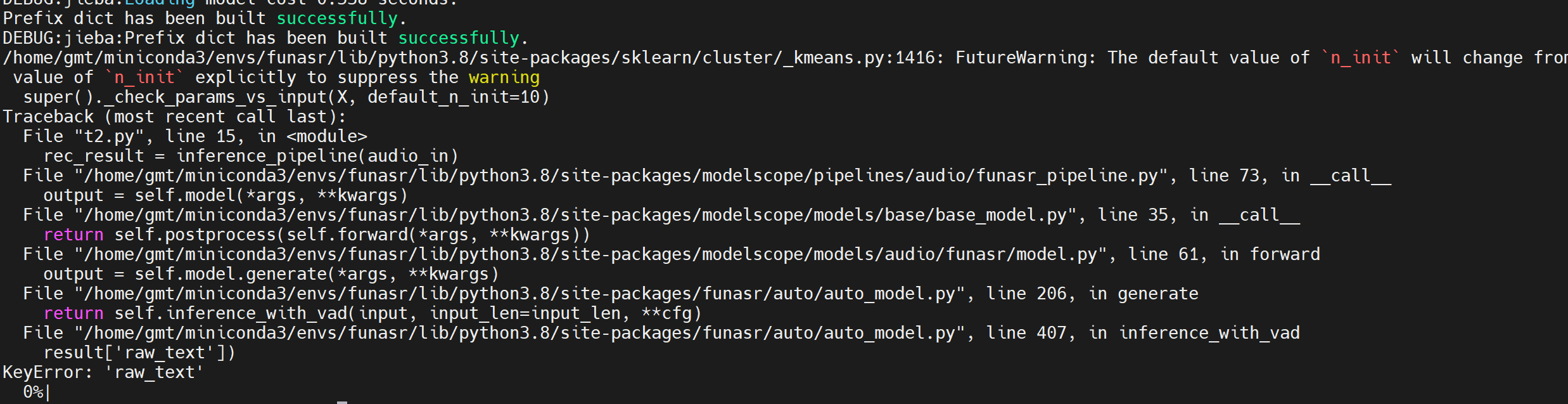
根据您提供的信息,modelscope-funasr模型在执行范例时出现报错,可能的原因涉及以下几个方面。以下是详细的分析和解决方法:
您提到的模型是iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn,这是一个语音识别模型,支持语音转文字、说话人分离等功能。如果模型在运行时出错,可能是由于以下原因:
模型ID或任务类型配置错误
在部署或调用模型时,需要正确配置MODEL_ID、TASK和REVISION参数。例如:
MODEL_ID: iic/speech_paraformer-large-vad-punc-spk_asr_nat-zh-cn
TASK: asr
REVISION: v1.0.0
如果这些参数未正确设置,可能会导致服务无法正常加载模型。
环境变量缺失或错误
如果模型是非公开模型,需要额外配置访问令牌(ACCESS_TOKEN)。请确保在部署时添加了正确的环境变量:
ACCESS_TOKEN: your_access_token
modelscope-funasr依赖于多个Python库,包括funasr和torch等。如果依赖未正确安装,可能会导致运行时错误。以下是检查和解决依赖问题的步骤:
验证依赖是否完整安装
确保已按照文档中的步骤安装所有依赖包:
pip install -r requirements.txt
pip install funasr[clip]
如果安装过程中出现错误,请检查Python版本是否满足要求(需为3.7或更高版本)。
验证FunClip安装是否成功
执行以下命令验证funasr是否安装成功:
python -c "import funasr.utils.cli_utils; funasr.utils.cli_utils.print_info()"
如果未看到成功消息,请重新安装依赖。
语音识别模型对输入数据有严格的要求,尤其是音频流的格式。如果输入数据不符合要求,可能会导致任务失败。以下是常见的输入问题及解决方法:
音频流格式不正确
模型要求输入音频为单声道音频流。如果输入的是多声道音频或格式不正确,可能会导致任务失败。请确保音频文件已转换为单声道格式,并使用正确的采样率(通常为16kHz)。
WebSocket事件处理问题
如果使用WebSocket API与模型交互,需正确处理task-finished和task-failed事件。例如,当接收到task-failed事件时,应检查错误信息:
{
"header": {
"task_id": "2bf83b9a-baeb-4fda-8d9a-xxxxxxxxxxxx",
"event": "task-failed",
"error_code": "CLIENT_ERROR",
"error_message": "request timeout after 23 seconds."
},
"payload": {}
}
根据错误信息调整代码逻辑,例如增加超时时间或优化音频传输方式。
语音识别模型通常对计算资源有较高要求,尤其是大模型。如果运行环境中GPU资源不足,可能会导致任务失败。以下是检查和解决资源问题的建议:
检查GPU资源分配
确保运行环境中已分配足够的GPU资源。对于大语言模型,建议选择ml.gu7i.c16m60.1-gu30实例规格或更高配置。
监控资源使用情况
使用以下命令检查GPU资源使用情况:
nvidia-smi
如果GPU显存不足,请尝试减少并发任务数或升级实例规格。
服务未正确启动
如果模型服务未正确启动,可能会导致调用失败。请确保服务状态为“运行中”,并检查日志以定位问题。
API调用参数错误
调用模型服务时,需确保请求参数格式正确。例如,调用语音识别服务时,需提供正确的音频流和元数据。如果参数格式错误,可能会导致任务失败。
根据上述分析,您可以按照以下步骤排查问题: 1. 检查模型配置参数(MODEL_ID、TASK、REVISION)是否正确。 2. 验证依赖是否完整安装,并确保Python版本符合要求。 3. 检查输入音频格式是否符合要求(单声道、16kHz采样率)。 4. 确保运行环境中已分配足够的GPU资源。 5. 检查服务状态和日志,定位具体错误原因。
如果问题仍未解决,请提供具体的错误信息(如error_code和error_message),以便进一步分析和解决。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
