
在Flink CDC项目中,我正在使用Flink PostgreSQL CDC功能,想知道它是否支持断点续传(即从上次停止的位置恢复读取变更数据)。我已经设置了checkpoint,周期为3分钟,并且在每次checkpoint时保存了PostgreSQL CDC source的offset记录。在配置文件中,我设置了如下参数:snapshot.mode: never
plugin.name: pgoutput
slot.name: myslot_test
但是在作业重启时,我尝试使用上一次checkpoint中保存的offset来恢复CDC数据流,却发现从老数据开始读取,而不是从上次checkpoint的offset处开始。请问我的配置或恢复方式是否存在错误,为什么断点续传没有生效?有没有相关的代码示例可以参考?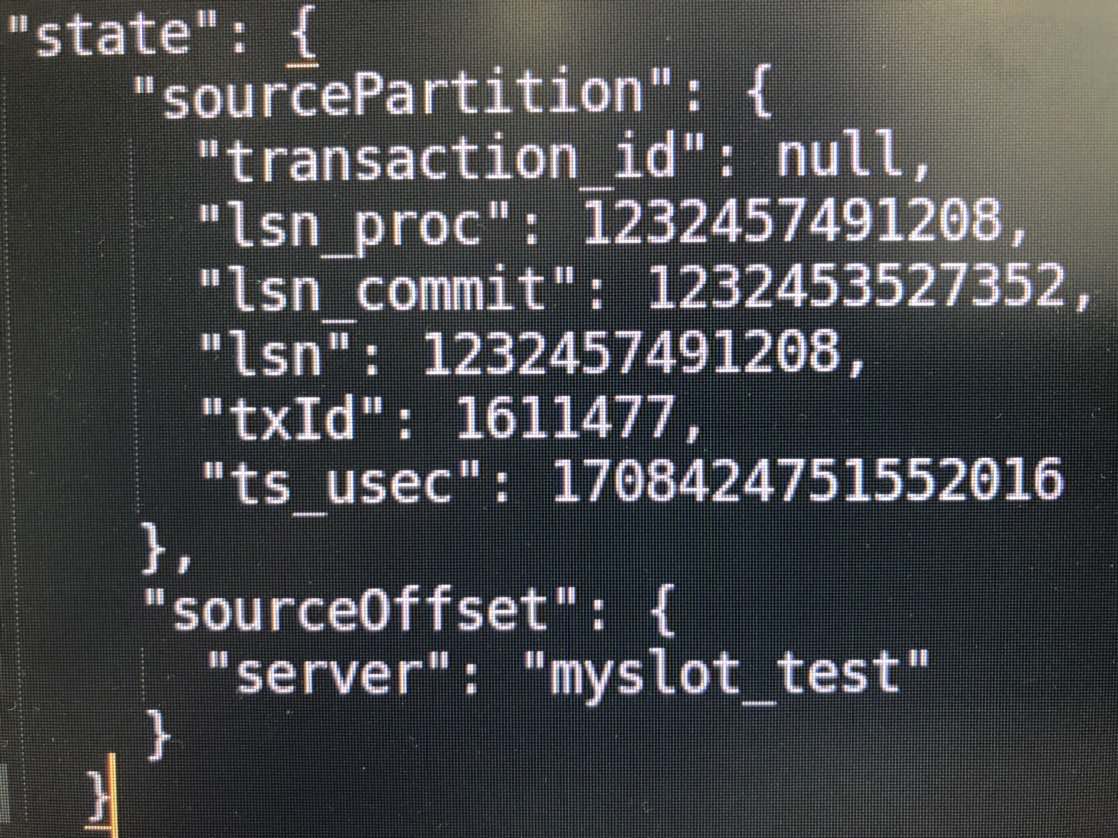
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink CDC中的PostgreSQL CDC支持断点续传。
在Flink CDC中,可以通过设置scan.startup.mode参数来控制数据同步的起始位置。如果将该参数设置为latest-offset,则从最新的偏移量开始同步数据;如果将其设置为0,则从头开始同步数据。
要实现断点续传,可以将scan.startup.mode参数设置为0,然后使用Flink的检查点机制来保存同步进度。当任务失败或重启时,可以从上次的检查点恢复同步进度,并继续从上次的偏移量开始同步数据。
以下是一个简单的示例代码,演示了如何在Flink中使用PostgreSQL CDC进行断点续传:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableDescriptor;
import org.apache.flink.table.descriptors.PostgreSQL;
import org.apache.flink.table.descriptors.Schema;
public class FlinkCDCDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 配置PostgreSQL CDC连接器
PostgreSQL postgres = new PostgreSQL()
.hostname("localhost")
.port(5432)
.database("mydb")
.username("myuser")
.password("mypassword");
// 定义表结构
Schema schema = new Schema()
.field("id", DataTypes.INT())
.field("name", DataTypes.STRING());
// 注册PostgreSQL CDC源表
tableEnv.connect(postgres)
.withSchema(schema)
.withScanStartupMode(ScanStartupMode.EARLIEST_OFFSET) // 设置为从最早的偏移量开始同步数据
.inAppendMode() // 以追加模式写入结果表
.registerTableSource("source_table");
// 创建结果表
tableEnv.connect(new StreamTableDescriptor("result_table", ...)) // 替换为实际的结果表描述符
.withSchema(schema)
.inAppendMode()
.registerTableSink("result_table");
// 执行查询并将结果写入结果表
Table result = tableEnv.sqlQuery("SELECT * FROM source_table");
tableEnv.toAppendStream(result, Row.class).print(); // 打印结果到控制台,可以替换为其他输出方式
// 执行作业
env.execute("Flink CDC Demo");
}
}
上述代码中,通过设置ScanStartupMode为EARLIEST_OFFSET,可以实现从最早的偏移量开始同步数据。同时,可以使用Flink的检查点机制来保存同步进度,并在任务失败或重启时从上次的检查点恢复同步进度。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


