
flink-cdc3.0在实际操作中应该怎么用昵?比如我配置了一个作业从mysql同步了10张表,过了两天想增加一张表,该怎么搞法?
我理解的不知道对不对?
1.先停掉作业,记录读取binlog位置
2.把新增的表加入到配置文件
3.用其他工具把新增表的数据初始化到目标表
4.启动作业从之前记录binlog位置继续实时同步
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
你的理解是正确的。在Flink CDC 3.0中,如果你需要在已配置的作业中增加一张新的MySQL表进行实时同步,大致的操作步骤如下:
停止当前CDC作业:首先,确保当前运行的Flink CDC作业被安全地停止,并记录下该作业读取MySQL binlog的位置信息。这个位置信息对于后续恢复同步状态至关重要。
更新配置文件:修改Flink CDC作业的配置文件,将新增的MySQL表添加到CDC源表列表中,并根据需求配置相关的同步选项和目标表信息。
初始化新表数据(可选):如果希望在Flink CDC开始同步之前,目标库的新表已经有完整的初始数据,可以使用其他工具如DataX、ETL工具或者编写脚本等方式,将新增表的数据一次性迁移至目标表。
启动作业并从上次位置继续同步:设置Flink CDC作业重新启动时,从之前记录的binlog位置继续读取变更数据。这通常可以通过配置项来实现,比如在Flink CDC的配置中指定MySQL binlog的起始位置。
启动作业:启动修改后的Flink CDC作业,它会从你之前记录的位置开始读取binlog,并开始同步所有配置中的表,包括新添加的那张表。
验证同步状态:启动后,监控作业状态和日志输出,确保新表的数据变更能够正确地实时同步到目标存储中。
对于Flink CDC 3.0,如果你想在已经同步了10张表的基础上增加一张新表进行同步,可以按照以下步骤操作:
停止作业:首先需要停止当前的Flink CDC作业。
记录读取binlog位置:在停止作业之前,确保记录下当前作业读取的binlog位置。这可以通过查看作业的状态或日志来获取。
更新配置文件:将新增的表添加到Flink CDC的配置文件中。配置文件通常是一个JSON格式的文件,其中包含了要同步的数据库连接信息和要同步的表的信息。
初始化目标表:使用其他工具(如MySQL客户端)将新增表的数据初始化到目标表中。这可以通过执行INSERT语句或者导出数据文件再导入的方式完成。
启动作业:重新启动Flink CDC作业,并指定从之前记录的binlog位置开始继续实时同步。这样,新增的表的数据就会从该位置开始被同步到目标表中。
首先动态加表需要开启,打个快照,,然后在flink-conf中配置启动快照路径,即可实现动态加表。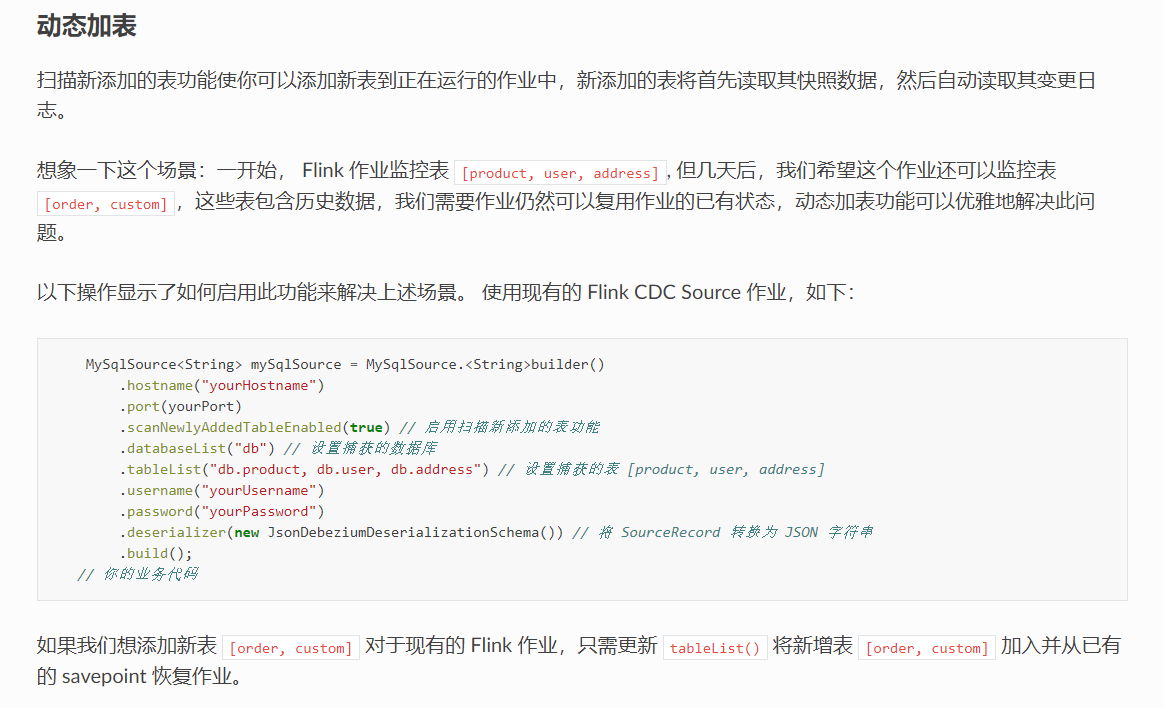 此回答来自钉群Flink CDC 社区。
此回答来自钉群Flink CDC 社区。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


