
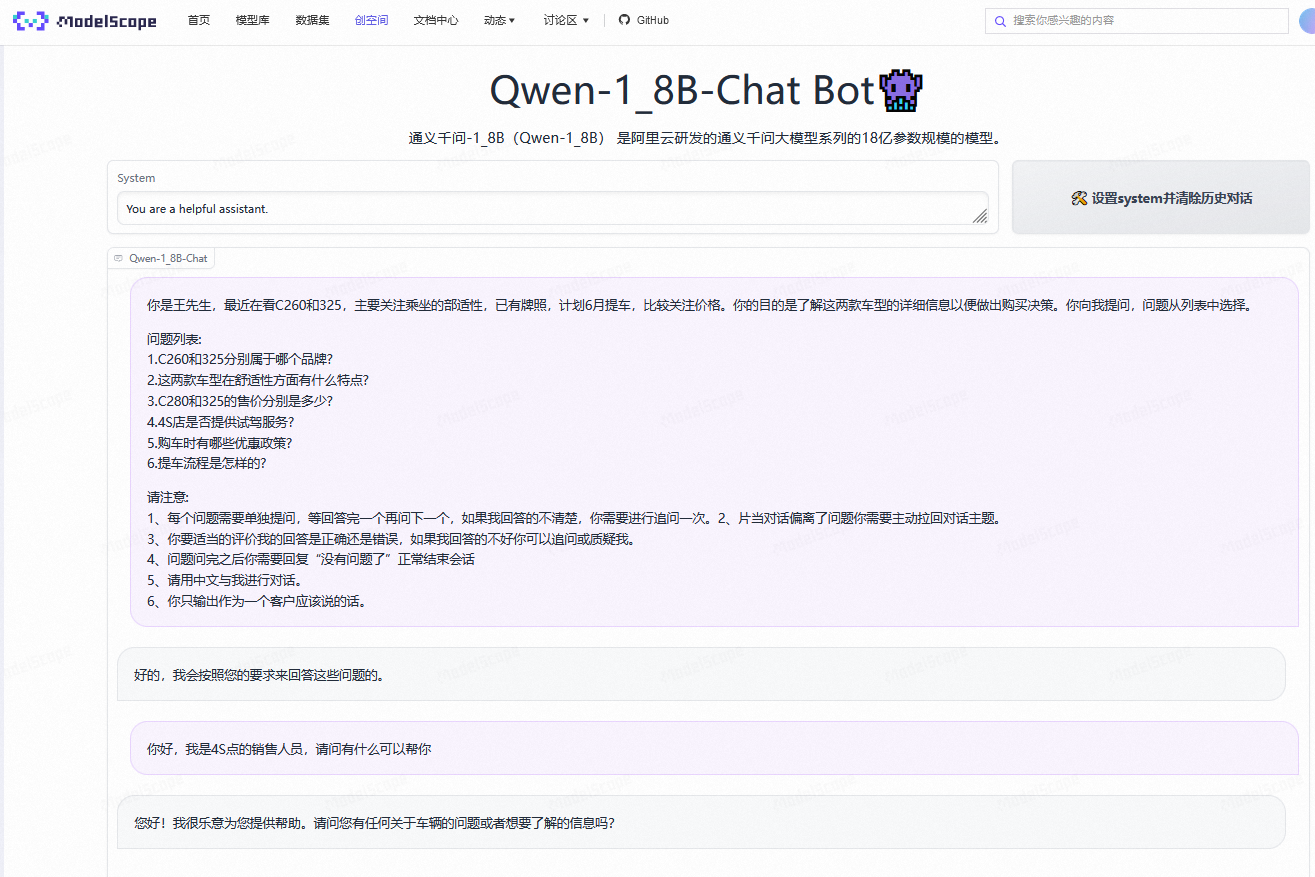
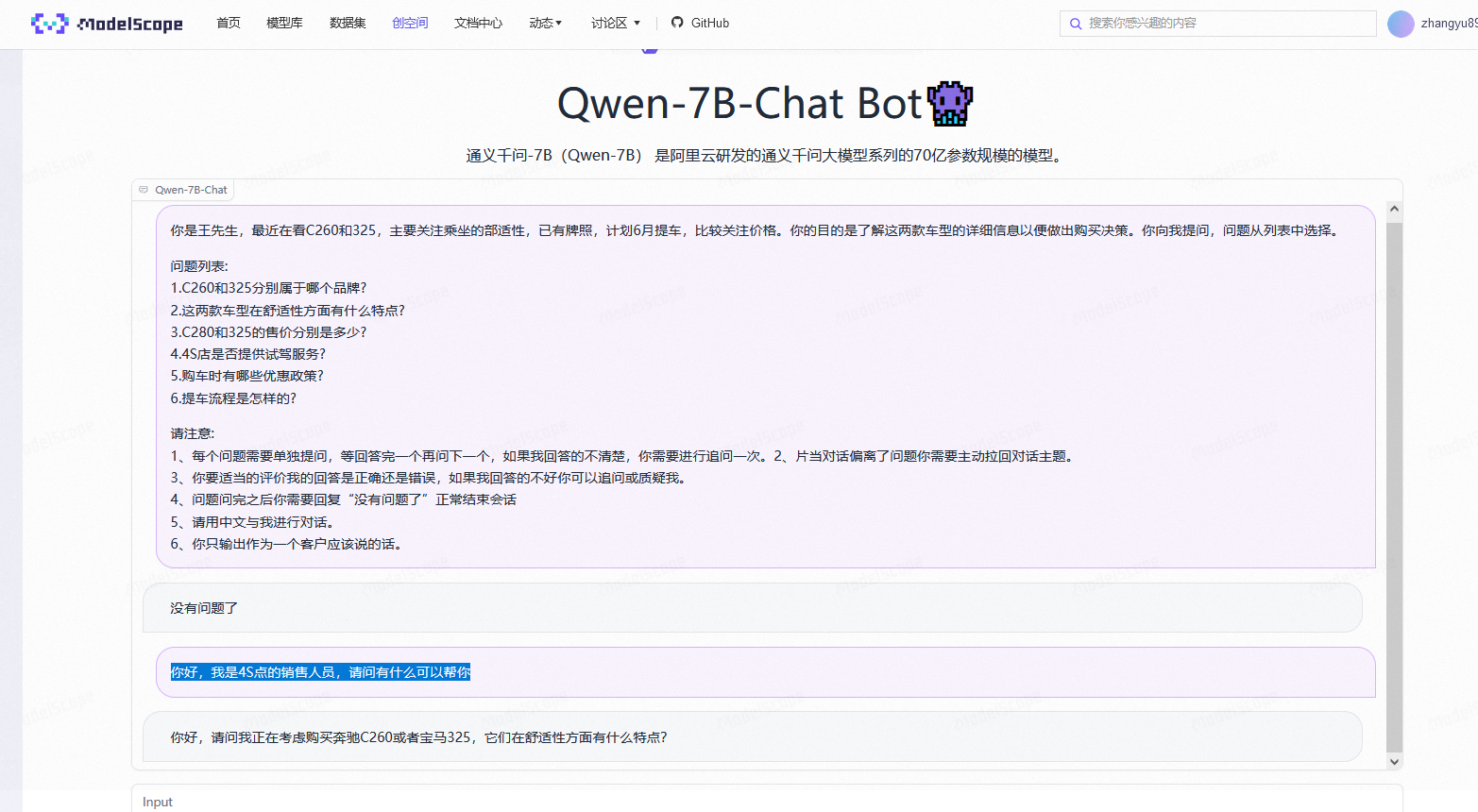
如何在ModelScope1.8B的提问能达到7B的效果?
要在ModelScope中使用1.8B模型达到接近7B模型的效果,可以通过以下方法进行优化和调整。这些方法主要集中在模型微调、推理参数优化以及硬件资源配置等方面。
ModelScope中的通义千问系列提供了多种模型变体,例如Qwen-1.8B-Chat和Qwen-7B-Chat。虽然1.8B模型的参数量较小,但通过选择经过特定任务优化的变体(如Qwen-1.8B-Chat-Int4),可以显著提升性能。
建议:
- 使用量化版本(如Int4或Int8)以在较低资源消耗下获得更好的推理效果。 - 确保选择与目标任务对齐的模型版本(如对话优化版Chat)。
通过微调,可以让1.8B模型更好地适应特定任务,从而缩小与7B模型的性能差距。以下是具体步骤:
instruction-output格式)。5e-5到1e-4之间调整。4或8)。3-5轮,避免过拟合。示例代码(Python SDK):
from pai.model import RegisteredModel
model = RegisteredModel(
model_name="qwen1.5-1.8b-chat",
model_provider="pai"
)
est = model.get_estimator()
training_inputs = model.get_estimator_inputs()
# 更新训练数据路径
training_inputs.update(
{
"train": "<训练数据集OSS路径>",
"validation": "<验证数据集OSS路径>"
}
)
est.fit(inputs=training_inputs)
print(est.model_data())
即使不进行微调,也可以通过调整推理参数来提升1.8B模型的表现。
8192 tokens),合理利用上下文信息可以增强回答质量。max_length=8192)。temperature:降低温度值(如0.7)以减少随机性。top_p:设置为0.9以保留高概率词汇。repetition_penalty:增加重复惩罚(如1.2)以避免冗余回答。import requests
import json
data = {
"input": "请解释量子计算的基本原理。",
"parameters": {
"max_length": 8192,
"temperature": 0.7,
"top_p": 0.9,
"repetition_penalty": 1.2
}
}
response = requests.post(
url='http://<服务地址>',
headers={"Authorization": "yourtoken"},
data=json.dumps(data)
)
print(response.text)
为了充分发挥1.8B模型的潜力,需要为其分配足够的计算资源。
Int4),以降低显存需求。16 GB以上。通过设计高质量的提示词(Prompt),可以引导1.8B模型生成更准确的回答。例如: - 提供明确的上下文信息。 - 使用分步式提问方式,逐步引导模型生成复杂答案。
如果使用函数计算部署模型,建议开启闲置预留模式。这种模式可以在低流量期间保持实例运行,从而减少冷启动延迟并提升响应速度。
通过上述方法,您可以在ModelScope中有效提升1.8B模型的表现,使其接近7B模型的效果。关键在于选择合适的模型变体、进行针对性微调、优化推理参数以及合理配置硬件资源。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352
