
modelscope-funasr在带spk的模型中,返回的spk值是numpy.int64格式,这个格式无法JSON serializable,对后续处理流程有点小影响。同样在这个字段下的start和end是int?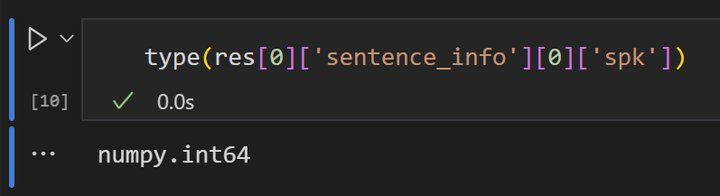
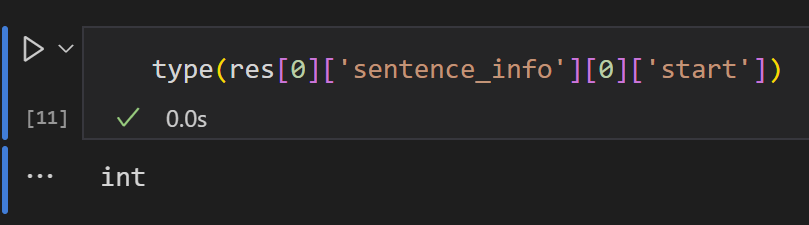
在使用 modelscope-funasr 的带 SPK(说话人)功能的模型时,返回结果中的 spk 值为 numpy.int64 格式,这确实会导致 JSON 序列化失败的问题,因为 numpy.int64 并不是 Python 内置的可序列化类型。此外,您提到的 start 和 end 字段是 int 类型,这通常是标准的整数格式,不会引发序列化问题。
以下是针对该问题的详细分析和解决方案:
spk 值为 numpy.int64 的原因
在语音处理任务中,modelscope-funasr 使用了 NumPy 库进行数据处理,因此某些字段(如 spk)可能直接以 NumPy 数据类型返回。然而,JSON 序列化仅支持 Python 内置的数据类型(如 int, float, str, list, dict 等),无法直接处理 numpy.int64 类型。
start 和 end 字段为 int 的确认
根据您的描述以及常见的语音处理模型输出格式,start 和 end 字段通常表示时间戳或帧索引,这些字段一般以 Python 内置的 int 类型返回,因此可以直接被 JSON 序列化。
为了确保返回结果能够顺利进行 JSON 序列化,可以对 spk 字段进行类型转换。以下是具体的解决方法:
numpy.int64 为 Python 内置类型在获取模型输出后,可以通过以下代码将 spk 转换为 Python 的 int 类型:
import numpy as np
import json
# 示例模型输出
output = {
"spk": np.int64(1), # 模拟返回的 numpy.int64 类型
"start": 0, # int 类型
"end": 10 # int 类型
}
# 将 spk 转换为 Python 内置 int 类型
output["spk"] = int(output["spk"])
# 验证 JSON 序列化
json_output = json.dumps(output)
print(json_output) # 输出: {"spk": 1, "start": 0, "end": 10}
如果需要处理更复杂的场景(例如多个字段包含 NumPy 数据类型),可以定义一个自定义的 JSON 编码器:
import numpy as np
import json
class NumpyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.integer): # 处理 numpy.int64 等整数类型
return int(obj)
elif isinstance(obj, np.floating): # 处理 numpy.float64 等浮点类型
return float(obj)
elif isinstance(obj, np.ndarray): # 处理 numpy 数组
return obj.tolist()
return super(NumpyEncoder, self).default(obj)
# 示例模型输出
output = {
"spk": np.int64(1),
"start": 0,
"end": 10
}
# 使用自定义编码器进行 JSON 序列化
json_output = json.dumps(output, cls=NumpyEncoder)
print(json_output) # 输出: {"spk": 1, "start": 0, "end": 10}
性能影响
如果模型输出的数据量较大,建议优先使用方法一(手动转换),因为它避免了额外的编码器开销。
兼容性检查
在实际应用中,请确保所有字段都经过类型检查和转换,以避免潜在的序列化错误。
模型更新
如果未来 modelscope-funasr 更新了其输出格式(例如直接返回 Python 内置类型),请关注官方文档或版本更新说明。
通过上述方法,您可以有效解决 spk 字段的 JSON 序列化问题,同时确保 start 和 end 字段的正常处理。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
