
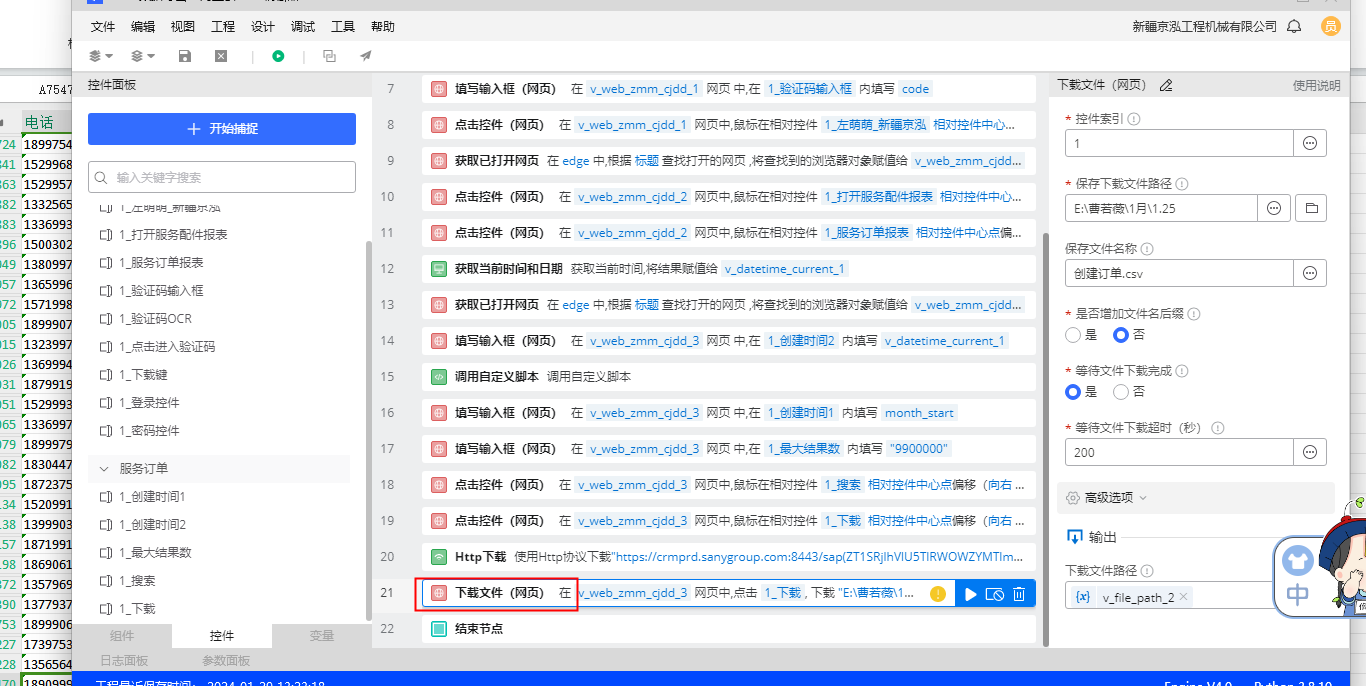
机器人流程自动化RPA这个另存为捕捉不到控件,用图2这个下载也是弹出图一那张图,捕捉不到控件,Http下载也不行,没有下载地址。请问一下,这个哪里有讲怎么解决吗?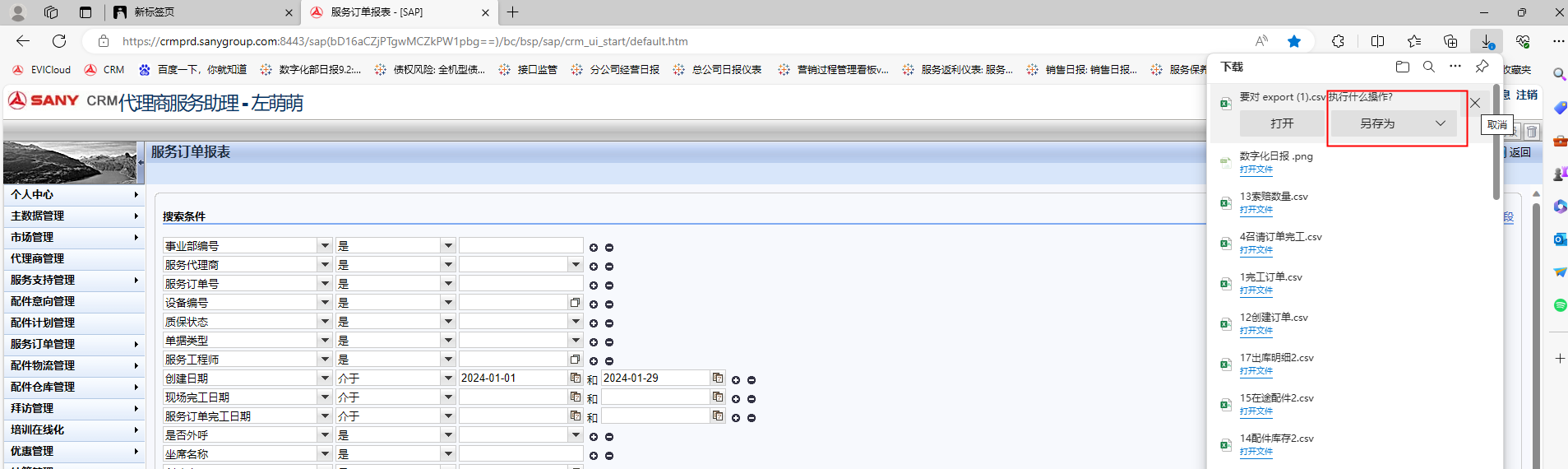
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,机器人流程自动化(RPA)在操作过程中无法捕捉到控件,并且尝试使用图像录制模式或HTTP下载时也未能成功。以下是针对该问题的详细分析和解决方案:
控件捕捉失败可能由以下原因导致: - 控件属性动态变化:目标控件的属性(如outertext、class等)可能随页面内容动态变化,导致捕捉失败。 - 浏览器兼容性问题:如果未正确安装或启用Aliyun RPA对应的Chrome扩展插件,可能导致控件无法被识别。 - 页面加载不完全:目标控件可能尚未完全加载,导致捕捉工具无法定位。
outertext,勾选class或nth-child)来提高捕捉稳定性。当自动匹配模式无法捕捉控件时,可以尝试使用图像录制模式。以下是具体步骤: 1. 在RPA编辑器中,选择“图像录制模式”。 2. 对目标区域进行截图,确保截图范围准确覆盖目标控件。 3. 验证截图区域是否能够正确匹配目标控件: - 点击“验证控件”按钮,测试截图区域是否能准确定位。 - 如果验证失败,调整截图范围或修改匹配规则(如使用正则表达式)。 4. 保存控件并将其应用到流程中。
如果目标页面没有明确的下载地址,可以通过模拟点击下载按钮的方式实现文件下载。以下是具体操作步骤: 1. 捕捉下载按钮控件: - 使用自动匹配模式或图像录制模式捕捉页面上的下载按钮。 - 确保捕捉到的控件能够触发下载操作。 2. 调用下载方法: - 使用download_by_element方法,指定保存路径和控件信息。例如: python url = '目标页面URL' page = rpa.app.chrome.create(url) download_path = r'本地保存路径' page.download_by_element(download_path, '下载按钮控件名称') - 确保在Chrome设置中取消“下载前询问每个文件的保存位置”选项。 3. 等待下载完成: - 设置合理的超时时间(如complete_timeout=120),以确保文件下载完成。
如果上述方法仍无法解决问题,可以尝试以下方法: - 手动模拟用户操作:通过鼠标点击或键盘输入的方式模拟用户操作,绕过控件捕捉的限制。 - 联系技术支持:如果问题涉及特定页面或环境配置,建议联系阿里云RPA团队获取技术支持。
通过以上方法,您可以有效解决控件捕捉失败和下载地址缺失的问题。如果仍有疑问,请提供更多具体信息(如目标页面的结构或错误日志),以便进一步分析和解决。

