
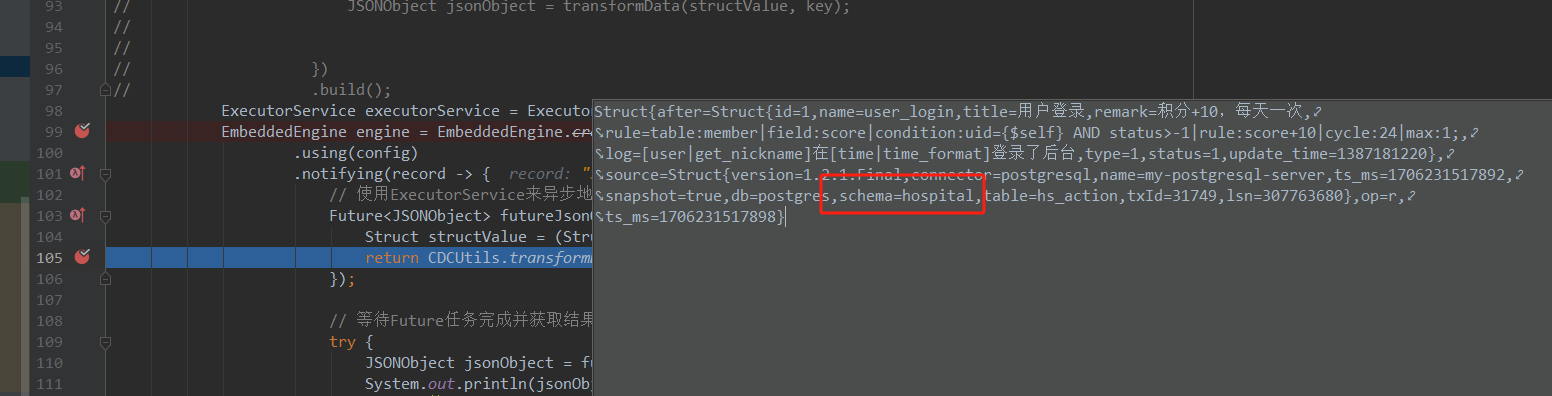
Flink CDC里明明设置了监听schema为test的表test2,为啥打包放进kettle就变成了监听别的schema了啊?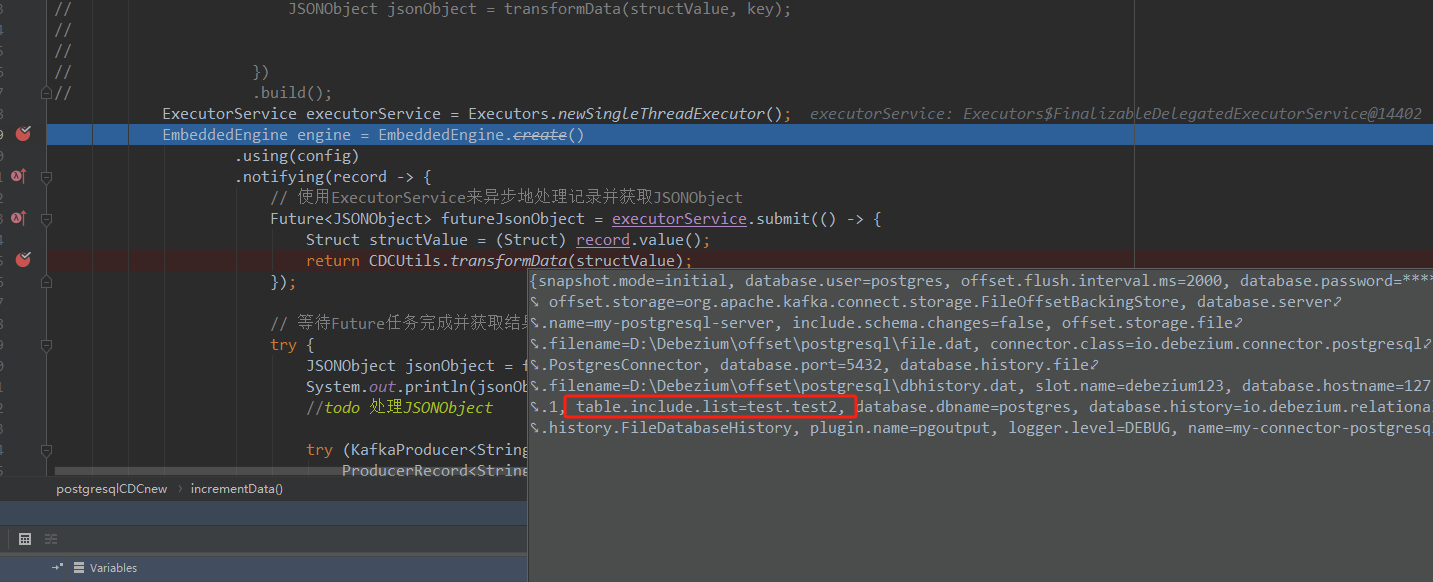
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用 Flink CDC 时,如果设置了监听特定 schema 的表(如 test.test2),但在将作业打包并放入 Kettle 后发现监听的 schema 发生了变化,可能是由于以下原因导致的:
Flink CDC 支持通过正则表达式匹配多个 schema 或表。如果在配置中使用了正则表达式,可能会意外匹配到其他 schema 或表。
可能原因:
如果 database-name 或 table-name 配置中使用了正则表达式(例如 ^(test).* 或 (test|other)),可能会匹配到其他 schema 或表,而不仅仅是 test.test2。
解决方法:
确保正则表达式的匹配范围严格限定为目标 schema 和表。例如:
'database-name' = 'test',
'table-name' = 'test2'
如果需要匹配多个表,可以明确指定,避免模糊匹配:
'table-name' = '(test2|test3)'
注意:正则表达式中的逗号需要用竖线(|)改写,避免歧义。
Kettle 可能会覆盖或修改 Flink CDC 的配置参数,导致监听的 schema 或表发生变化。
可能原因:
在 Kettle 中运行 Flink 作业时,可能会通过环境变量、参数传递或其他方式重新设置 database-name 和 table-name 参数,导致监听的目标 schema 被更改。
解决方法:
检查 Kettle 的配置文件或参数传递逻辑,确保没有覆盖 Flink CDC 的原始配置。可以通过打印日志或调试确认实际生效的参数值。
如果使用了 MySQL Catalog 来管理元数据,Catalog 的默认数据库配置可能会影响监听的 schema。
可能原因:
在创建 MySQL Catalog 时,default-database 参数指定了默认的数据库。如果未显式指定 database-name,Flink CDC 可能会使用 default-database 的值作为监听目标。
解决方法:
确保在创建 MySQL Catalog 时,default-database 参数与目标 schema 一致,或者在 Flink CDC 配置中显式指定 database-name。例如:
CREATE CATALOG mycatalog WITH (
'type' = 'mysql',
'hostname' = 'rm-bp1gcn0q0j0******.mysql.rds.aliyuncs.com',
'port' = '3306',
'username' = 'usertest',
'password' = '${secret_values.mysqlpw}',
'default-database' = 'test'
);
重要:default-database 的值应与目标 schema 一致,否则可能导致监听错误的 schema。
如果上游 MySQL 数据库发生了 schema 变更,但下游未及时同步,可能会导致监听目标发生变化。
可能原因:
Flink CDC 通过捕获前后数据的 Schema 变化来同步表结构。如果上游仅发生 DDL 变更但无数据变更,下游可能不会触发同步,导致监听目标不一致。
解决方法:
确保上游 MySQL 数据库的 schema 变更后有数据写入,以触发下游的同步。如果需要手动处理 schema 变更,可以参考以下步骤:
注意:在 EVOLVE 模式下,DROP TABLE 和 TRUNCATE TABLE 会直接同步到下游,需谨慎操作。
不同版本的 Flink CDC 连接器可能存在行为差异,尤其是在 schema 匹配和监听方面。
可能原因:
如果使用的 Flink CDC 连接器版本较旧,可能存在 schema 匹配逻辑的缺陷或兼容性问题。
解决方法:
升级到最新版本的 Flink CDC 连接器(如 VVR 8.0.7),并检查相关文档以确认 schema 匹配逻辑是否符合预期。
default-database 配置,确保与目标 schema 一致。通过以上步骤逐一排查,应该能够定位并解决监听 schema 错误的问题。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

