
Flink CDC里这是啥原因?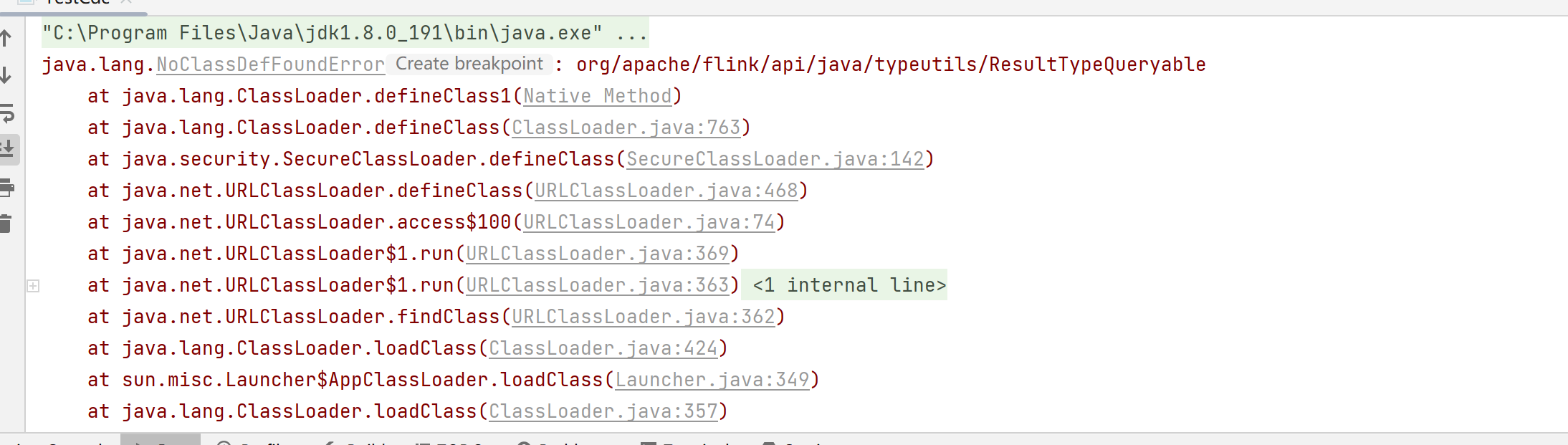
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用 Flink CDC 时,可能会遇到各种问题,以下是针对常见问题的原因分析和解决方案,结合知识库资料进行详细说明:
原因
MySQL 的 Binlog 是实例级别的,记录了所有数据库和表的变更。即使 Flink 作业只涉及某一张表的变更,Binlog 中仍然会包含整个实例的所有变更记录。Flink CDC 在 Debezium 或连接器层面过滤特定表的变更记录,而不是在 MySQL 层面完成过滤。
解决方案
- 启用 Source 复用:通过复用 CDC Source 减少额外的带宽使用。 - 优化网络配置:确保网络带宽充足,避免因带宽不足导致性能瓶颈。
timestamp 字段时区相差 8 小时原因
在解析 Binlog 数据中的 timestamp 字段时,CDC 作业中配置的 server-time-zone 参数与 MySQL 服务器的实际时区不一致,导致时区偏差。
解决方案
- 确保 Flink CDC 配置中的 server-time-zone 参数与 MySQL 服务器的时区一致。例如,如果 MySQL 服务器使用 UTC+8,则需要在 Flink CDC 配置中设置:
'server-time-zone' = 'Asia/Shanghai'
MyDeserializer),需参考 RowDataDebeziumDeserializeSchema 中对 timestamp 类型的解析逻辑,并正确处理时区信息。原因
- 配置的 MySQL 实例为 RDS MySQL 5.6 的备库或只读实例,这些实例可能未向日志文件写入增量数据,导致下游同步工具无法读取增量变更信息。 - 全量阶段读取时间过长,导致最后一个分片数据量过大,出现 OOM 问题,作业 Failover 后卡住。
解决方案
- 升级 MySQL 实例:建议使用可写实例或将 RDS MySQL 升级至更高版本。 - 增加并发度:提高 MySQL Source 端的并发度,加快全量读取速度。 - 调整 Checkpoint 间隔:合理设置 Checkpoint 间隔时间,确保全量数据写入下游后再切换到增量读取。
原因
Flink CDC 不直接捕获 DDL 变更,而是通过前后两条数据之间的 Schema 差异来推断表结构变更。如果上游表仅发生 DDL 变更但无新增数据或数据变更,则不会触发下游表结构的更新。
解决方案
- 确保上游表在发生 DDL 变更后有新增数据或数据变更,以触发下游表结构的更新。 - 如果必须立即同步表结构变更,可以手动停止作业并重新启动。
finish split response timeout 异常原因
Task 的 CPU 使用率过高,导致无法及时响应 Coordinator 的 RPC 请求。
解决方案
- 增加资源:在资源配置页面增加 Task Manager 的 CPU 资源。 - 优化作业逻辑:检查作业是否存在性能瓶颈,优化数据处理逻辑以降低 CPU 消耗。
原因
MongoDB CDC 支持从 Checkpoint 恢复,其原理是基于 MongoDB 的 Oplog 或 Change Stream 记录的偏移量信息,结合 Flink 的状态管理机制实现数据恢复。
解决方案
- 确保启用了 Checkpoint 功能,并合理配置 Checkpoint 间隔时间。 - 如果作业失败,可以从最近的 Checkpoint 恢复,继续读取增量数据。
原因
Postgres 的 TOAST(The Oversized-Attribute Storage Technique)用于存储大字段数据。如果 TOAST 数据未被传输,可能是由于配置不当或数据格式不兼容。
解决方案
- 检查 Postgres CDC 配置,确保启用了对 TOAST 数据的支持。 - 如果问题持续存在,可以尝试将大字段数据拆分为较小的字段,避免使用 TOAST 存储。
原因
每个 CDC 作业都需要连接数据库读取 Binlog,随着作业数量增加,数据库的压力也会显著增加。
解决方案
- 引入 Kafka 解耦:将表数据同步到 Kafka 消息队列中,再通过消费 Kafka 数据进行解耦。 - 合并 CTAS 作业:将多个 CTAS 语句合并为一个作业运行,并为每个 MySQL CDC 源表配置相同的 Server ID,实现数据源复用。
原因
MySQL CDC 源表的设计目标是读取 MySQL 数据库中的全量和增量数据,因此只能作为 Source 使用。而普通的 MySQL 表可以用作维表或结果表。
解决方案
- 如果需要将数据写入 MySQL,可以使用普通的 MySQL 表作为结果表。
tableList 选项原因
tableList 选项用于指定需要同步的表列表,格式为 databaseName.tableName。
解决方案
- 示例配置如下:
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("localhost")
.port(3306)
.databaseList("mydb") // 数据库名
.tableList("mydb.mytable") // 表名
.username("root")
.password("password")
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
以上是对 Flink CDC 常见问题的原因分析和解决方案,希望对您有所帮助!
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

