
Flink三种集群模式,Standalone模式,Flink On YARN,Flink On K8S,这三种模式有啥优缺点,生产环境如何选择呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink提供了三种集群部署模式:
每种模式都有各自的特点和适用场景:
Standalone模式的优点是可以快速搭建并运行Flink集群,并且不需要额外的资源管理系统;缺点是没有资源隔离,当多个应用共用同一台机器时可能发生资源竞争。另外,当应用数量增加时,集群扩展性和管理复杂度也会提高。
Flink on YARN的优点是提供了强大的资源管理和隔离能力,可以同时运行多个应用,而且可以根据需要动态分配资源;缺点是在安装和维护方面相比Standalone模式更加复杂。
Flink on Kubernetes的优点是提供了更好的资源管理和容错能力,并且可以无缝集成到现有的Kubernetes生态系统中;缺点是对于Kubernetes有一定的学习成本和技术门槛。
在实际生产环境中,根据项目需求选择合适的部署模式非常重要。如果项目规模较小,可以选择StandAlone模式;如果项目涉及多个应用共享资源,可以选择Flink on YARN;如果是大规模分布式场景,推荐采用Flink on Kubernetes。
Apache Flink提供了三种主要的集群部署模式:Standalone模式、Flink On YARN、Flink On Kubernetes。
Standalone模式:
优点:易于配置和快速开始;适合小规模测试环境;
缺点:无HA(高可用)功能;无法动态扩缩容;资源管理单一;
适合场景:适合于测试阶段的小规模实验环境;
Flink On YARN:
优点:利用YARN集群管理资源;具备一定的HA能力;可通过YARN实现动态扩缩容;
缺点:依赖于YARN生态;资源管理相对复杂;
适合场景:已有YARN集群的企业内部开发;
Flink On Kubernetes:
优点:利用Kubernetes集群管理资源;可实现自动化运维;具有高度的弹性和扩展性;
缺点:依赖于Kubernetes生态;需掌握Kubernetes相关技能;
适合场景:云原生时代下的大规模分布式环境。
在生产环境中,具体选择哪种模式,需要根据实际业务需求和现有IT环境进行综合考虑。若已有YARN集群,优先推荐使用Flink On YARN;若没有YARN集群但有Kubernetes集群,则推荐使用Flink On Kubernetes;对于规模较小、仅用于试验性质的项目,则可以选择Standalone模式,以降低运维成本。
Apache Flink有三种主要的集群部署模式:Standalone模式、Flink On YARN、Flink On Kubernetes。
生产环境中如何选择,主要取决于以下几个因素:
Flink有三种基本的集群运行模式:
以下是这三种模式的一些优缺点:
Standalone模式:
优点:简单易用,易于理解和配置,适合小型集群或测试环境。
缺点:资源管理和调度能力有限,不适合大规模生产环境。
Flink On YARN模式:
优点:可以利用YARN的强大资源管理和调度能力,适合大型生产环境。
缺点:需要配置YARN环境,对用户有一定的技术要求。
Flink On Kubernetes模式:
优点:可以利用Kubernetes的容器化能力和强大的生态,适合云原生环境。
缺点:需要配置Kubernetes环境,对用户的技术要求较高。
在生产环境中,具体选择哪种模式主要取决于你的应用场景和技术需求。如果你的应用场景比较简单,或者你的团队对技术的要求不高,那么Standalone模式可能是最适合你的选择。如果你的应用场景比较复杂,或者你的团队对技术的要求比较高,那么Flink On YARN模式或Flink On Kubernetes模式可能是更适合你的选择。
Flink支持的三种主要集群模式包括:Standalone模式、Flink On YARN和Flink On K8S。
Standalone模式是最简单的一种集群模式,不需要依赖外部的资源调度平台如yarn或mesos。这种模式下,Flink自身提供集群管理功能,适合用于开发和测试环境。
Flink On YARN模式允许你将Flink任务提交到YARN集群上运行。在这种方式下,Flink可以充分利用YARN的资源管理器来调度和管理任务。但需要注意,当某个任务出现问题时,可能会导致整个YARN集群崩溃。
Flink On K8S模式则是将Flink部署到Kubernetes集群上。与前面两种模式不同,K8S是一个强大的容器编排工具,可以为Flink提供更多的资源管理和扩展性特性。
参考:flink三种集群运行模式的优缺点对比https://blog.csdn.net/qq_44831907/article/details/127454478
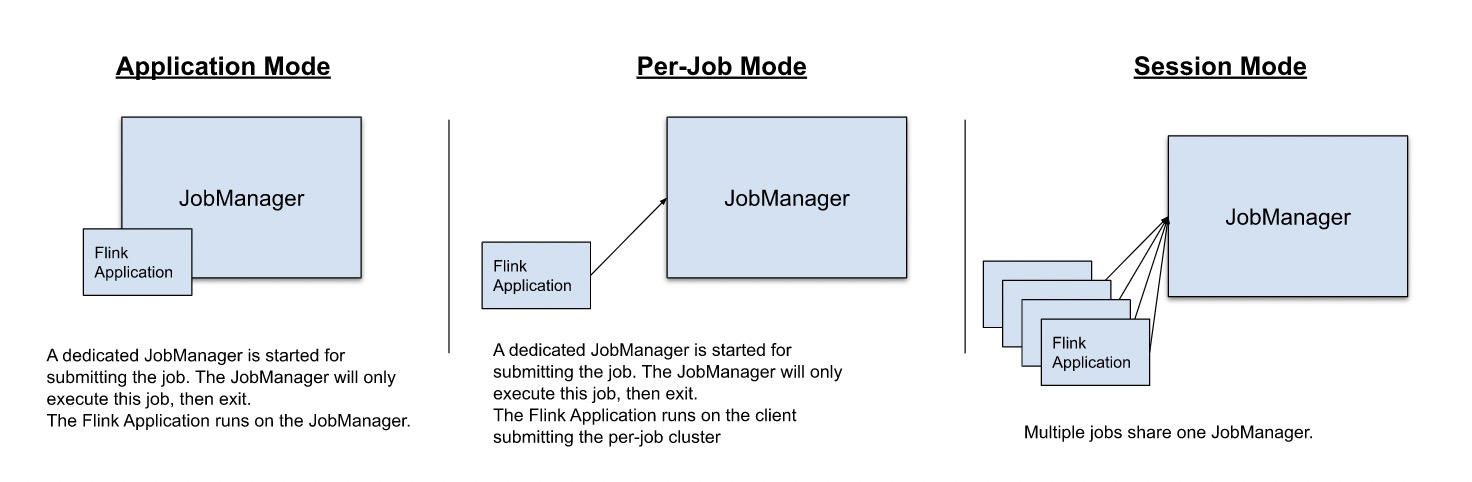
flink 三种基本运行模式(抽象概念):Session、Per-job、Application
standalone、Yarn、k8s等——flink基于三种基本运行模式根据不同集群资源管理策略衍生出的不同实现类
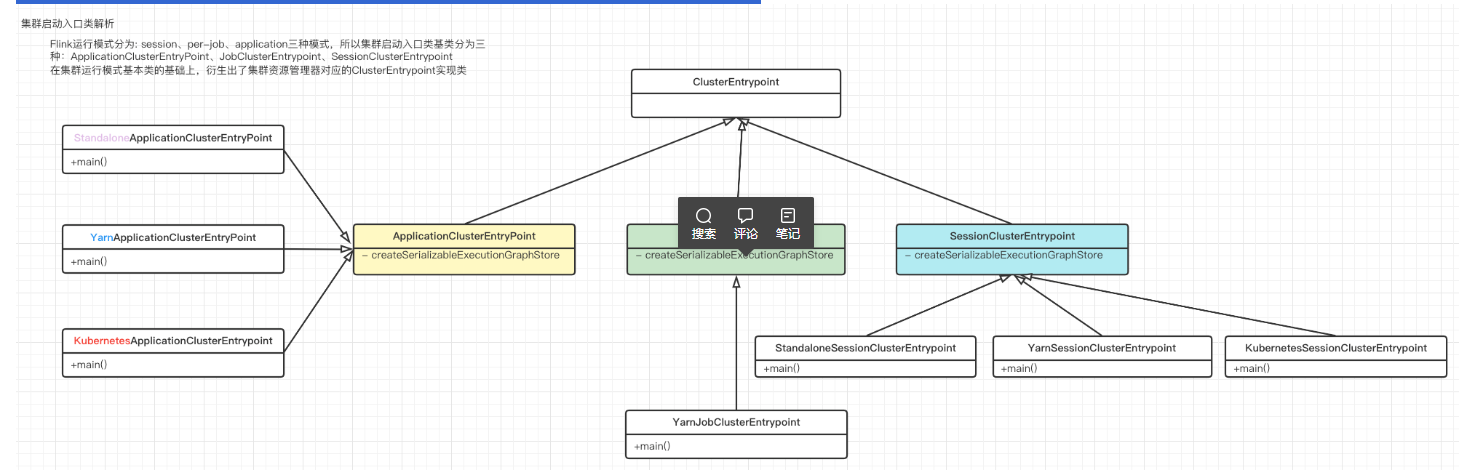
1.1 先看每种模式的介绍:
Session :多个jobs共享一个JobManager,即所有的任务都运行在这一个集群。例如Standalone静态部署模式。适合单个规模小、执行时间短的大量作业。
集群生命周期:不与任务挂钩,作业完成后仍会继续运行知道手动停止session。
集群资源隔离:所有任务都运行在一个集群上面,所以隔离性差。Flink的Slot仅能隔离内存,并不能隔离CPU资源。如果 TaskManager 崩溃,则在此 TaskManager 上运行 task 的所有作业都将失败。
main()方法在Client执行。
Per-job:每一个job都会动态创建一个专属于自己的集群。
集群生命周期:与任务挂钩,随任务运行创建;一旦作业完成,集群将被销毁。
集群资源隔离:一个任务独占一个集群,隔离性最好。
main()方法在Client执行。
Application:Application这个词指的是包含一个或多个job的程序。用线程进程概念来类别,一个游戏进程(Application)会专门有渲染画面的线程(job)也会有播放音乐的线程(job)。此模式,一个Application动态创建一个专属自己的集群,Application内所有job共享该集群。
集群生命周期:与Flink 应用(Application)挂钩,随Application创建,随Application结束而消亡。
集群资源隔离:Application之间资源隔离,Application内所有job共享集群。
main()方法在Cluster执行
1.2 一些结论
其他概念比较容易理解,main()方法在哪执行这点会挺让人迷惑的:究竟main()方法里面干了什么?导致main()方法成为指标的原因又是什么?
熟悉flink架构的大家应该记得,main()方法执行后,会获得任务的jar包及相关依赖jar包,同时,会将StreamGraph,最终生成JobGraph的转换。
main()方法在Client端执行,会给客户端带来额外的压力。且多个作业同时使用同一Client时,会存在单点瓶颈,拖累Cluster。
如果在集群侧执行main(),Client的工作就仅仅将任务的jar包提交即可,main()会在JM的集群入口类(ApplicationClusterEntryPoint)执行main()方法生成JobGraph。由于集群一般资源比较充足,并不会对集群带来太大的压力。
三种基本运行模式下根据不同集群资源管理策略衍生了多种不同的实现类,下一节我们会在三种基本运行模式的衍生实现类中挑选
参考:flink三种集群运行模式的优缺点对比https://blog.csdn.net/qq_44831907/article/details/127454478
link有三种集群模式:Standalone模式、Flink On YARN和Flink On K8S。这三种模式在生产环境中的选择取决于您的具体需求和环境。下面是这三种模式的优缺点以及如何在生产环境中选择合适的模式。
生产环境中推荐使用Flink On YARN。
Standalone模式是集群模式的一种,独立模式是独立运行的,不依赖任何外部的资源管理平台,存在资源不足,出现故障不会自动扩展或重分配资源的能力,一般用在开发测试或作业非常少的场景下。
部署相对简单,可以支持小规模,少量的任务运行;
缺少系统层面对集群中Job的管理,容易遭成资源分配不均匀;
资源隔离相对简单,任务之间资源竞争严重。
在FlinkonYARN模式下,Flink在YARN(Hadoop的资源调度和集群管理系统)之上运行。Flink作为一个YARN应用程序,利用YARN来管理资源分配和任务调度。使用这种模式,可以充分利用Hadoop集群的资源,实现Flink的分布式计算。计算资源统一由Hadoop YARN管理,生产环境使用。
Flink On K8S,在Flink 1.9以上版本内置了K8S的客户端,Flink的可以直接向K8S申请计算资源,集群资源得到了更高效的利用。Flink 1.10 在 Kubernetes 集群上已经GA(生产可用)的两种部署模式,然后分析了处于 Beta 版本的 native session 部署模式和即将在 Flink 1.11 发布的 native per-job 部署模式。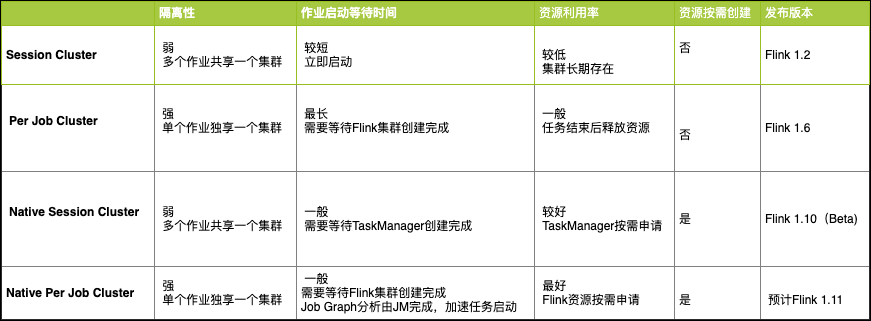
Flink的三种集群模式各有优缺点:
生产环境中的选择取决于具体的需求,例如如果希望充分利用现有的基础设施,那么可以选择Flink On YARN模式;如果希望更好地控制资源分配和调度,那么可以选择Flink On K8S模式。如果您对于Flink的使用场景不太熟悉,建议先在开发测试环境中使用Standalone模式进行试验,并根据实际需求逐步向生产环境过渡。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


