
文字识别OCR里 只写data数据吗?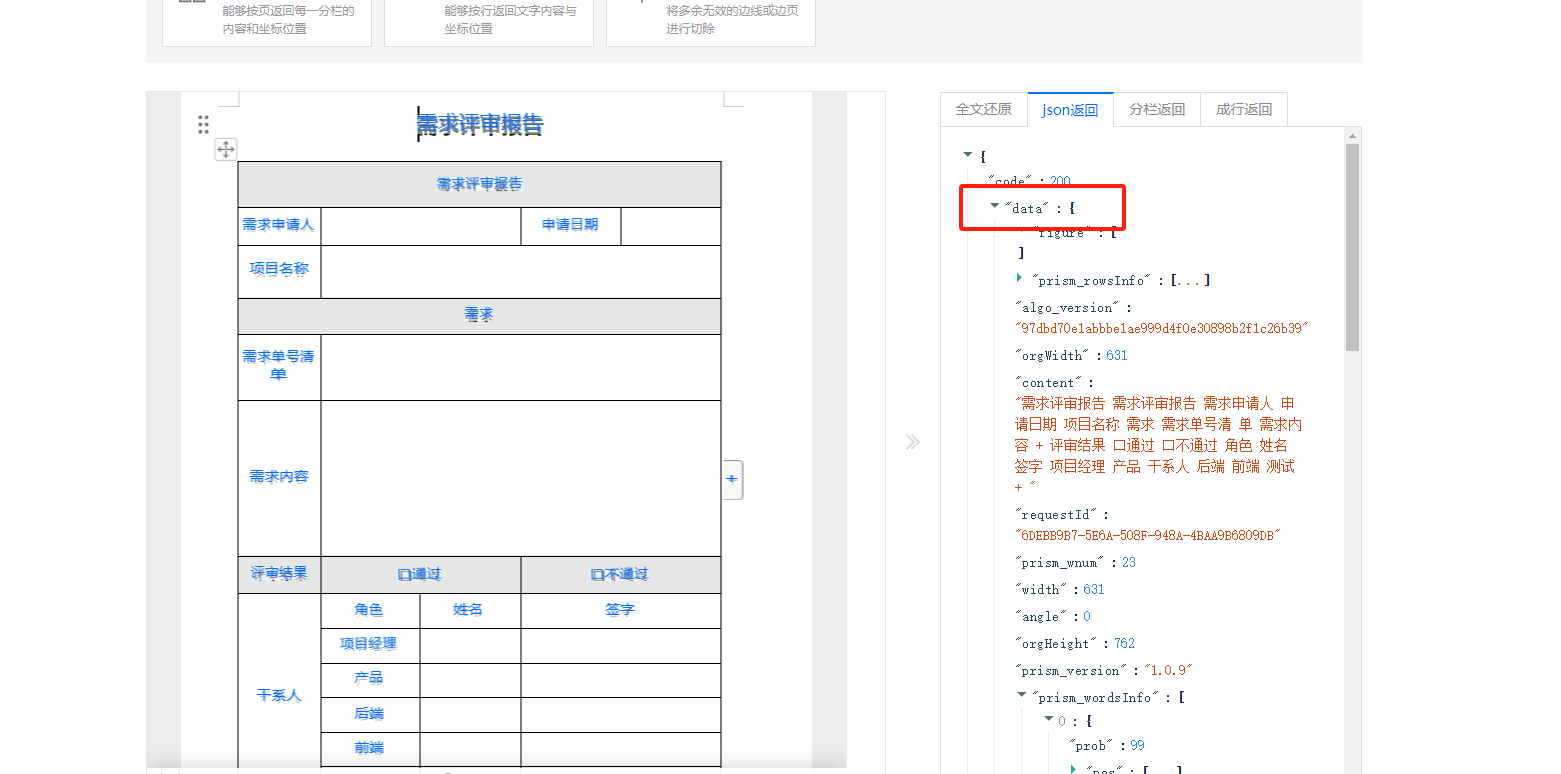
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您好,根据文字识别OCR 官方API文档来看,图片识别接口返回数据是需要通过data获取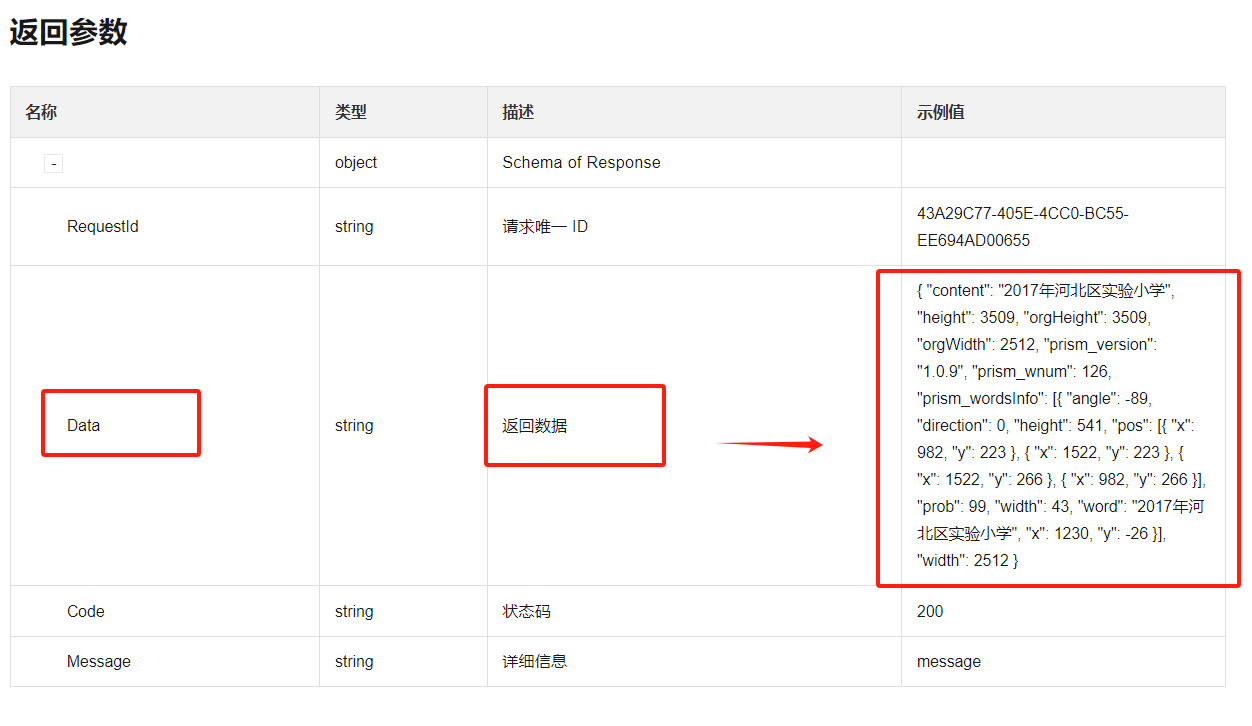
正常返回示例的json格式如下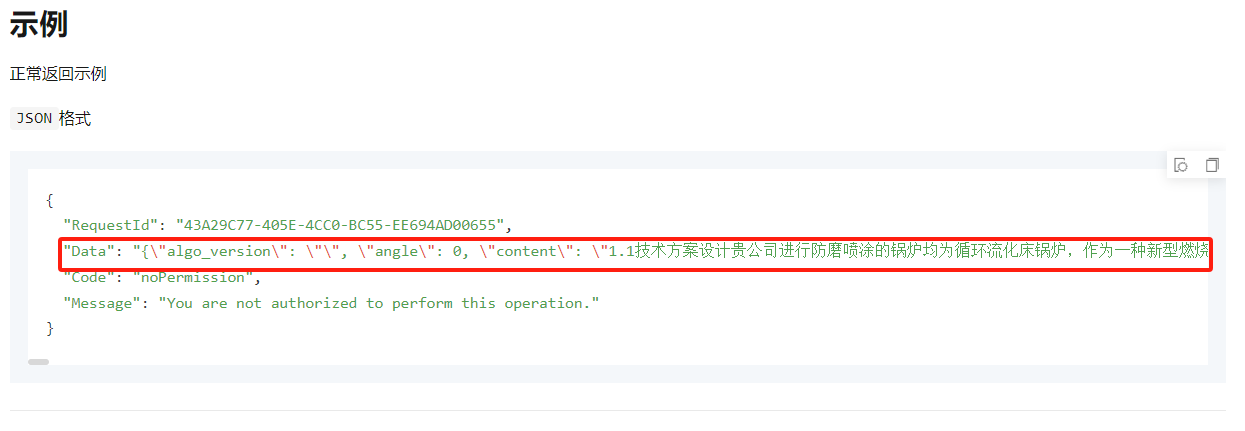
您可以通过获取json格式中data数据来进行json解析,获取具体返回数据信息。
在文字识别OCR中,不仅需要处理和传递数据,还需要考虑如何对图像文件进行分析和处理以获取文字及版面信息。例如,在使用Python进行OCR(光学字符识别)时,通常会使用一些开源库如 pytesseract、Tesseract等来进行识别。此外,通常的流程包括扫描和识别两个步骤:首先进行图像扫描,然后识别出扫描结果中的文字信息。因此,这个过程涉及到的不仅仅是数据的编写,还包括了对图像的处理和分析等多个环节。
可以先看下这里的返回参数说明
https://help.aliyun.com/document_detail/442247.html?spm=a2c4g.442246.0.0.38184c47woxy1R
。此回答来自钉群【官方】阿里云OCR公共云客户交流群。


