
modelscope-funasr官网,提供的模型,设别非常不准,有什么好的解决办法吗?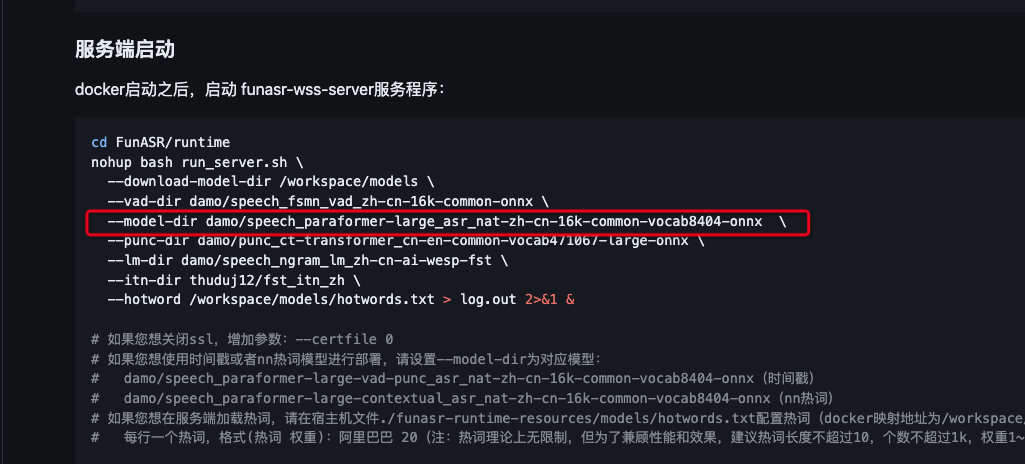
如果您发现modelscope-funasr官网提供的模型准确率不高,可以尝试以下解决办法:
检查输入音频的质量和清晰度。如果输入的音频质量较差或存在噪音干扰,可能会影响模型的识别准确率。建议使用高质量的音频文件进行测试。
调整模型参数。modelscope-funasr提供了一些可调节的参数,例如采样率、帧长、帧移等,可以根据具体情况进行调整,以提高模型的准确率。
尝试其他模型。modelscope-funasr官网提供了多个不同版本的模型,您可以尝试使用其他版本的模型进行测试,以找到最适合您需求的模型。
自定义训练模型。如果您有大量特定领域的音频数据,可以考虑使用这些数据来自定义训练一个适合自己需求的模型。modelscope-funasr提供了丰富的API和工具,可以帮助您快速完成模型训练和部署。
针对您提到的ModelScope-FunASR官网提供的模型识别不准确的问题,有几个可能的解决方法:
检查模型兼容性:请确保您选择的模型与您的数据集和应用场景相匹配。ModelScope提供了多种预训练模型,每个模型都有其特定的训练数据和适用场景。例如,如果您的音频数据较长,您可能需要选择一个能够处理长音频版本的模型,如"Paraformer-large长音频版本"。
数据预处理:确保您的音频数据预处理得当,音频质量良好,且符合模型的输入要求。一些模型可能需要特定的预处理方法,如激励增强的热词定制支持,这可以提高热词的召回率和准确率。
调整模型参数:根据您的需求调整模型参数,可能有助于改善识别准确性。例如,某些模型支持非实时和实时操作,根据您的应用场景选择合适的模式。
重新训练模型:如果对现有模型的准确性不满意,您可以考虑使用自己的数据集重新训练模型。ModelScope提供了模型训练的教程和工具,可以帮助您完成这一过程。
联系技术支持:如果问题依旧存在,建议联系ModelScope的技术支持获取更专业的帮助。他们可能能提供更深入的解决方案。
总的来说,解决模型识别不准确的问题需要综合考虑模型选择、数据处理、参数调整以及可能的模型再训练等多个方面。希望这些建议能对您有所帮助。
将wav文件转换16bit的pcm试试吧。ffmpeg -i video_path -vn -acodec pcm_s16le -ar 16000 -ac 1 wav_path 此回答整理自钉群“modelscope-funasr社区交流”
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352

