
modelscope-funasr “Paraformer语音识别-中文-通用-16k-离线-large-长音频版-onnx”怎么可以像“Paraformer语音识别-中文-通用-16k-离线-large-长音频版”一样输出sentences信息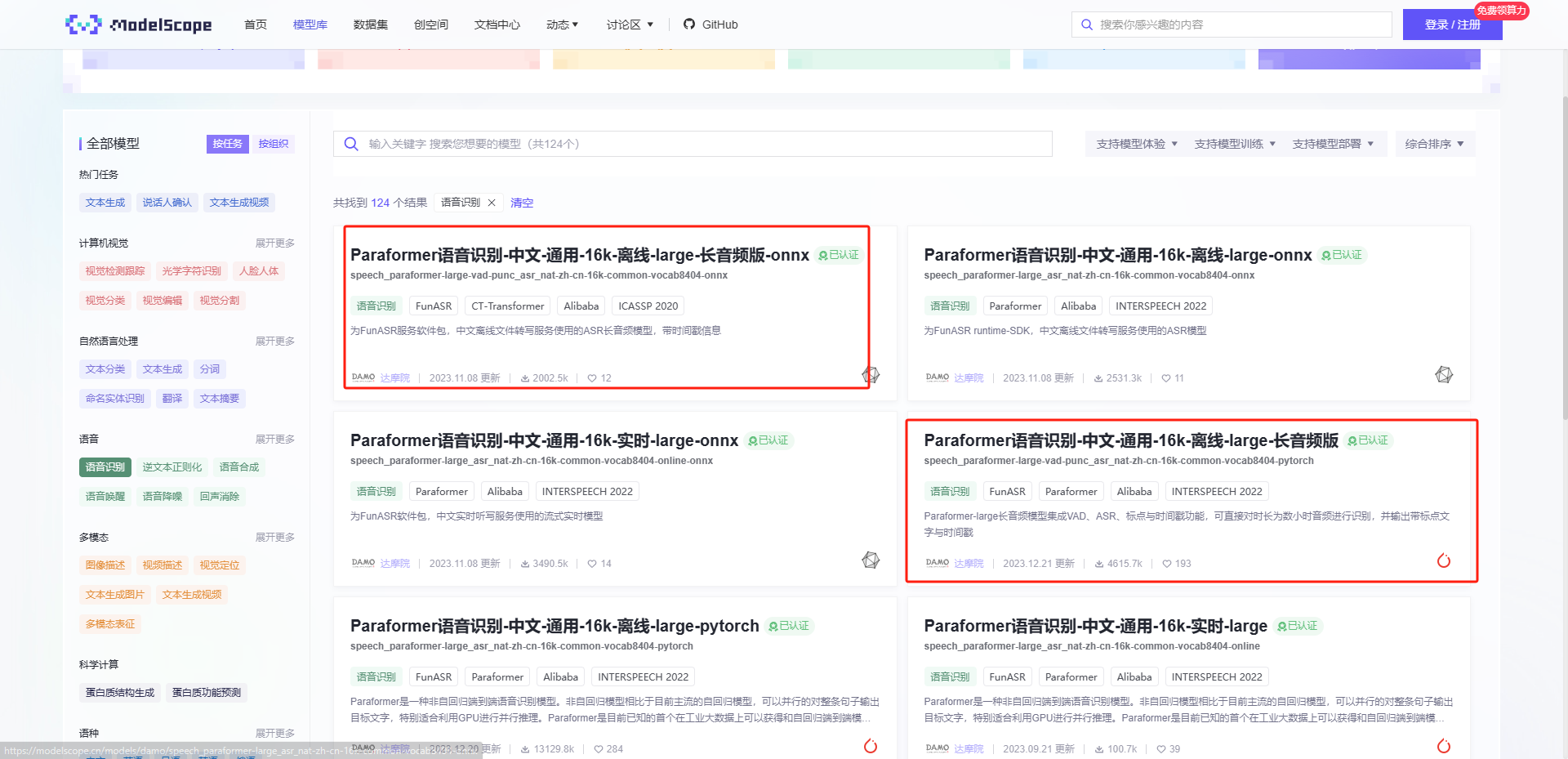
ModelScope的FunASR模型默认会输出识别结果的详细信息,包括每个词的开始时间、结束时间和置信度等。如果你想要像“Paraformer语音识别-中文-通用-16k-离线-large-长音频版”一样只输出sentences信息,你需要修改FunASR的配置文件。
在FunASR的配置文件中,有一个参数叫做"beam_size",这个参数决定了解码器在进行解码时使用的语言模型的大小。当"beam_size"设置为1时,解码器只会选择概率最高的词作为识别结果,这样就可以得到类似于“Paraformer语音识别-中文-通用-16k-离线-large-长音频版”的输出结果。
需要注意的是,将"beam_size"设置为1可能会降低识别的准确性,因为解码器在选择识别结果时不再考虑其他可能的词。
要将modelscope-funasr的输出从Paraformer语音识别-中文-通用-16k-离线-large-长音频版-onnx更改为像Paraformer语音识别-中文-通用-16k-离线-large-长音频版一样输出sentences信息,您可以尝试以下步骤:
modelscope-funasr库。如果没有安装,可以使用以下命令进行安装:pip install modelscope-funasr
from modelscope.funasr import FunAsrModel
import torch
# 加载模型
model = FunAsrModel.from_pretrained("modelscope/funasr-paraformer-chinese-common-16k-offline-large-long")
# 准备输入数据
input_audio = torch.randn(1, 16000) # 假设输入是一个随机音频张量
# 进行推理
output = model(input_audio)
# 获取sentences信息
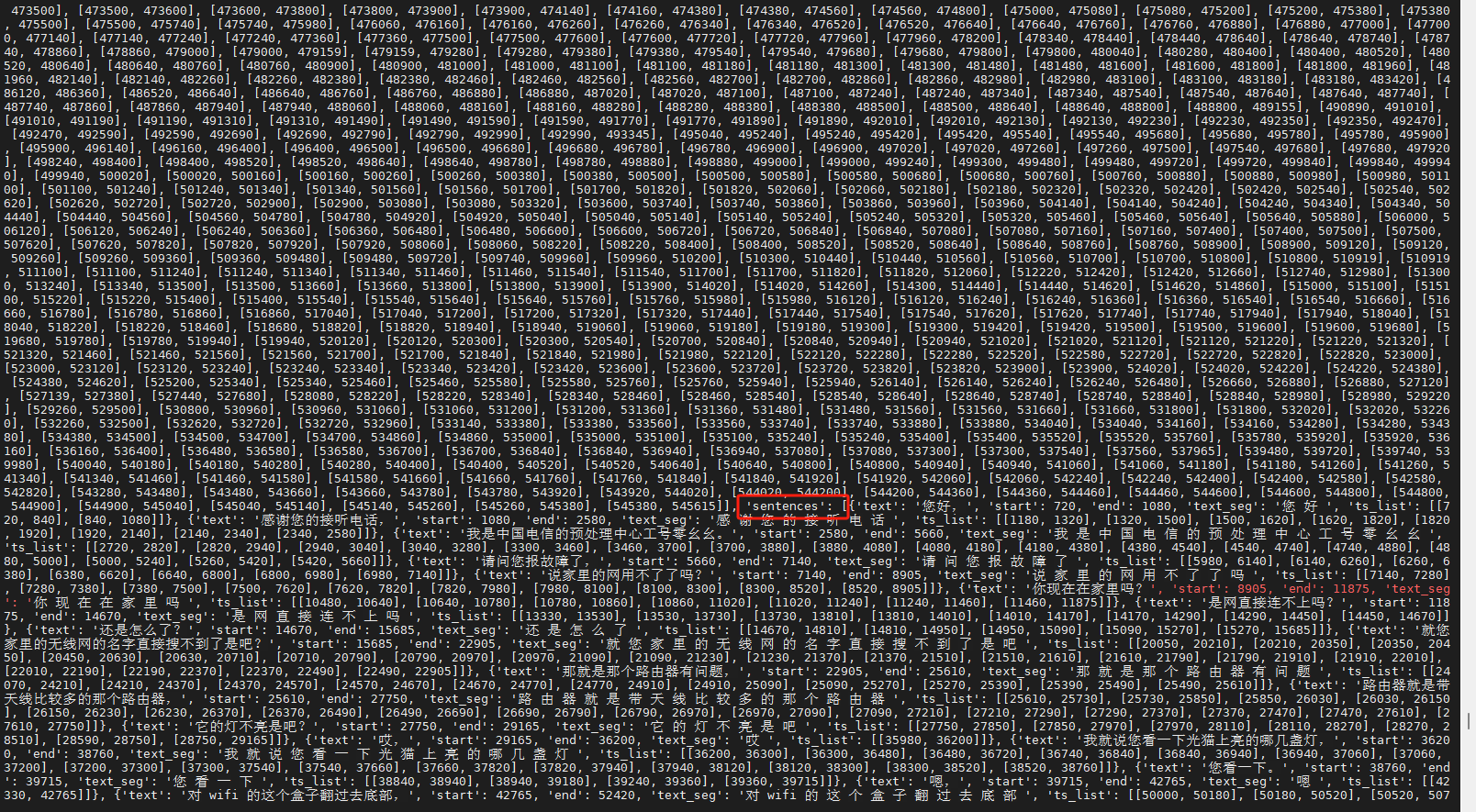
sentences = output["sentences"]
在这个例子中,我们首先从预训练模型中加载了FunAsrModel,然后使用一个随机生成的音频张量作为输入进行推理。最后,我们从输出中提取了sentences信息。
其实github上新的代码已经支持了, https://github.com/alibaba-damo-academy/FunASR/tree/main/runtime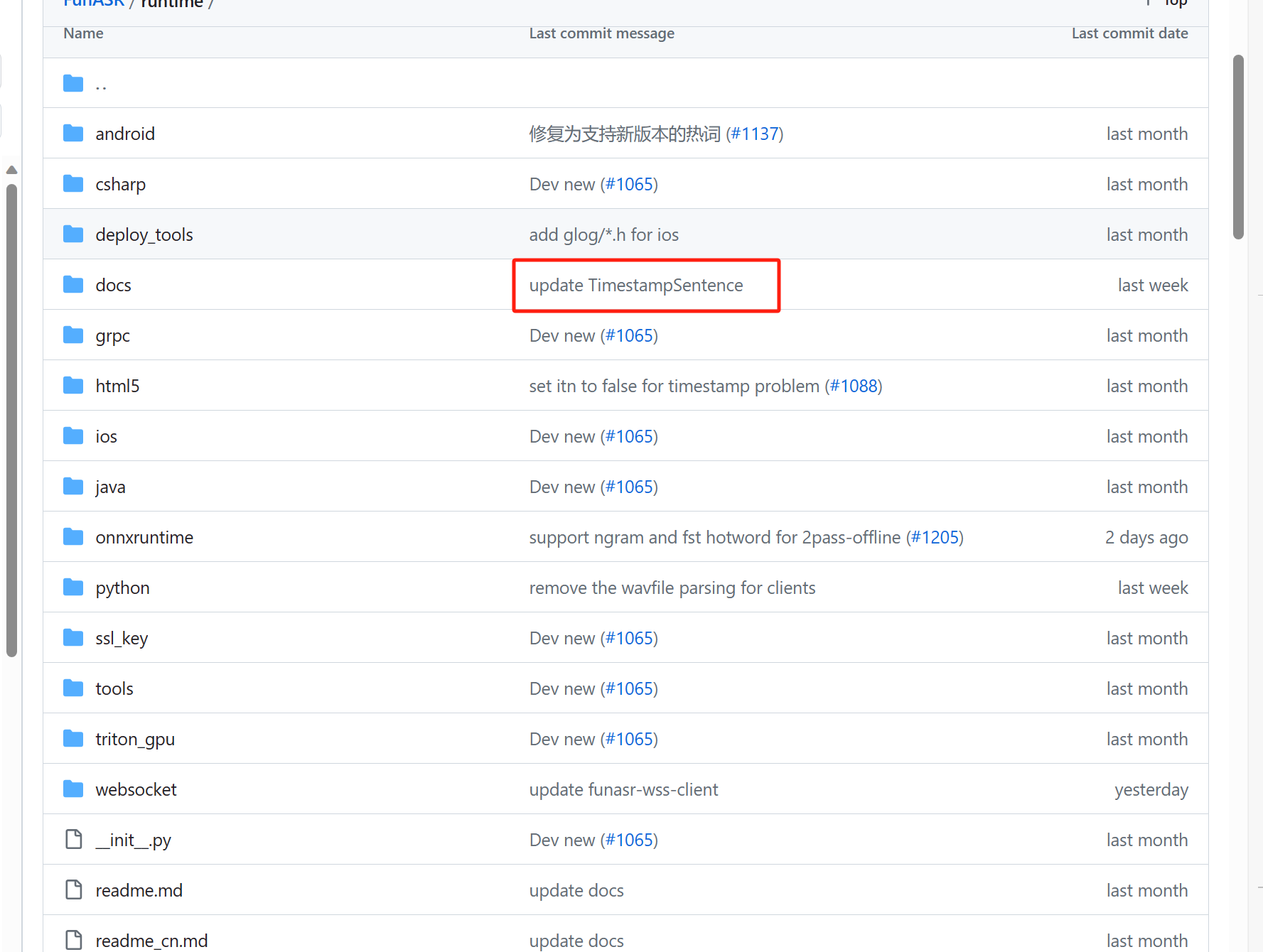
看这个
此回答整理自钉群“modelscope-funasr社区交流”
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352

