
ModelScope这个max -length是一次调用输入和输出共这么多吗?另外怎么转到具体多少个中英文字符?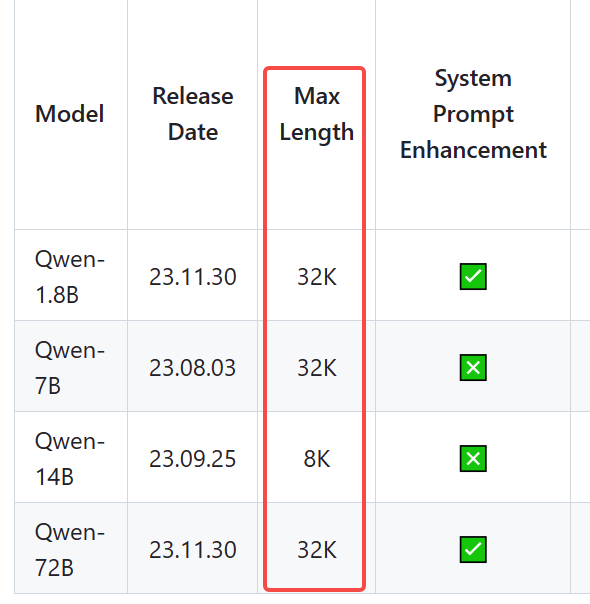
在ModelScope中,max_length参数主要是指生成的token的最大长度,包括输入和输出的token总和。例如,如果设置max_length为50,那么输入和输出的token总数就不能超过50。这个参数在模型推理过程中起着重要的作用,可以控制输出结果的长度,防止过长的输出对理解造成困扰。同时,需要注意的是,max_length需要与输入文本的长度以及可能的生成token的数量(由max_new_tokens参数控制)一起考虑。
ModelScope中的max_length参数是指一次调用中输入和输出的最大字符数。它包括了所有的字符,无论是中文还是英文。
如果您想将输入和输出限制为特定的中英文字符数,可以使用Python的字符串处理函数来实现。例如,您可以使用len()函数来计算字符串中的字符数,并使用切片操作来截取所需的部分。以下是一个示例代码:
# 计算输入和输出的字符数
input_chars = len(input_str)
output_chars = len(output_str)
# 计算需要截取的字符数
total_chars = input_chars + output_chars
if total_chars > max_length:
# 如果总字符数超过了最大长度,则进行截取
if input_chars > max_length // 2:
# 如果输入字符数超过了最大长度的一半,则优先截取输入部分
input_str = input_str[:max_length // 2]
output_str = output_str[input_chars - max_length // 2:]
else:
# 否则优先截取输出部分
input_str = input_str[-max_length // 2:]
output_str = output_str[:max_length // 2]
请注意,此代码仅适用于Python语言。如果您使用的是其他编程语言,请相应地调整代码。

