
Flink CDC这种情况是不是代表cdcsource发送的数据有堆积,下一个process算子,需要增加并行度?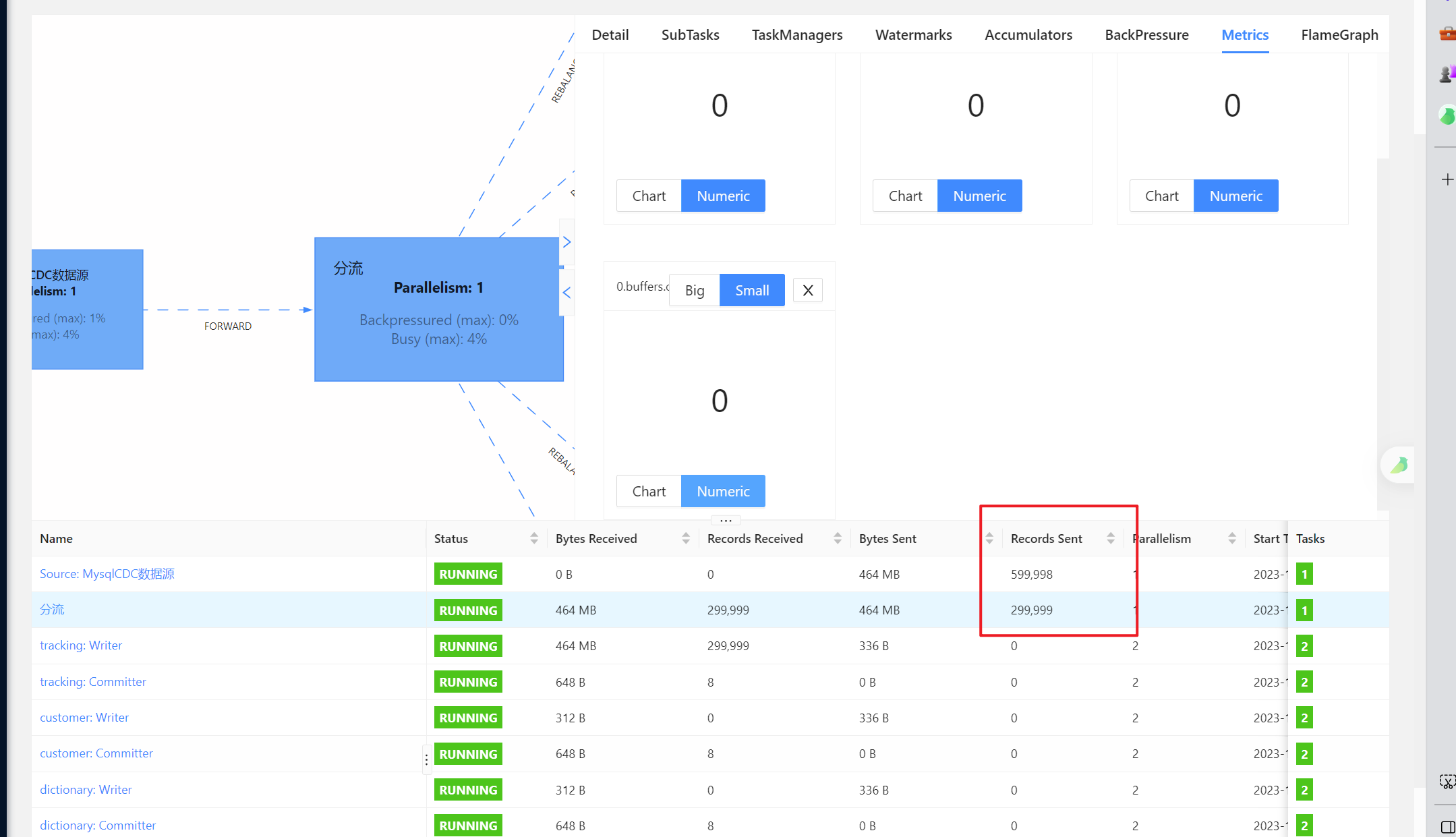
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink CDC作业中,如果发现CDC Source发送的数据存在堆积现象,可能是因为下游算子的处理能力不足,导致数据无法及时消费。这种情况下,可以通过增加下游Process算子的并行度来提升处理能力,从而缓解数据堆积问题。
以下是针对该问题的详细分析和解决方案:
数据堆积通常发生在以下场景: - Source端并发较高:MySQL CDC Source通过多并发读取全量或增量数据,生成大量变更消息。 - 下游算子处理能力不足:如果下游Process算子的并行度较低,无法及时处理Source端发送的数据,则会导致数据堆积。 - 网络或序列化开销:当开启Source复用时,合并的Source越多,序列化和反序列化的开销越大,可能导致数据传输延迟。
为了缓解数据堆积问题,可以采取以下措施:
在Flink作业中,全局并行度决定了任务的最大并行执行数量。如果下游算子的并行度不足,可以通过以下方式调整: - 在实时计算开发控制台的基础模式中设置全局并行度。 - 或者在专家模式中为特定的VERTEX(如Process算子)单独设置更高的并发数。
在VVR 8.0及以上版本中,Flink批作业默认支持自动并行度推导功能。通过以下配置项优化并行度分配: - execution.batch.adaptive.auto-parallelism.enabled:启用自动并行度推导。 - execution.batch.adaptive.auto-parallelism.min-parallelism 和 execution.batch.adaptive.auto-parallelism.max-parallelism:设置允许的最小和最大并行度。 - execution.batch.adaptive.auto-parallelism.avg-data-volume-per-task:根据每个任务期望处理的数据量动态调整并行度。
Flink作业中的Slot是资源分配的基本单位。确保申请的Slot数量与全局并行度一致,以避免资源不足导致的任务阻塞。如果Slot数量不足,可以通过增加TaskManager的资源来扩展Slot数量。
除了增加下游算子的并行度外,还可以通过以下方式进一步优化作业性能:
如果多个MySQL CDC源表的配置项(除数据库、表名和server-id外)相同,可以开启Source复用功能,减少重复连接带来的资源消耗。启用方法如下:
SET 'table.optimizer.source-merge.enabled' = 'true';
注意:开启Source复用后,建议保持pipeline.operator-chaining为默认值(true),以避免因算子链断开导致的序列化开销增加。
如果全量阶段结束后进入增量阶段时卡住,可能是因为Checkpoint间隔时间设置过大。建议根据业务需求合理设置Checkpoint间隔时间,例如:
SET 'execution.checkpointing.interval' = '60s';
通过监控告警页面查看currentEmitEventTimeLag指标,判断是否已完成全量数据同步。如果该指标大于0,说明已进入Binlog读取阶段,此时可以重点关注增量阶段的性能表现。
如果确认CDC Source发送的数据存在堆积,建议优先增加下游Process算子的并行度,并结合自动并行度推导和Source复用功能进行优化。同时,合理配置Checkpoint间隔时间和监控关键指标,确保作业稳定运行。
重要提醒:在调整并行度或启用Source复用后,需重新启动作业以应用新的配置。如果作业状态无法恢复,建议选择无状态启动。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

