
Flink CDC中使用mysql-cdc进行增量快照到starrcocks,源表有1.8亿数据量,但增量读取总是在没有完成的情况下停止,日志中也没有报错。日志最后停在块的读取上,MySQL中也没有关于CDC的查询进程了,但在未停止时,是可以正常查询到CDC的查询进程。Flink版本是1.14.4,CDC版本是2.4.1。以下是Flink关于CDC的最后日志和相关的FlinkSQL参数配置: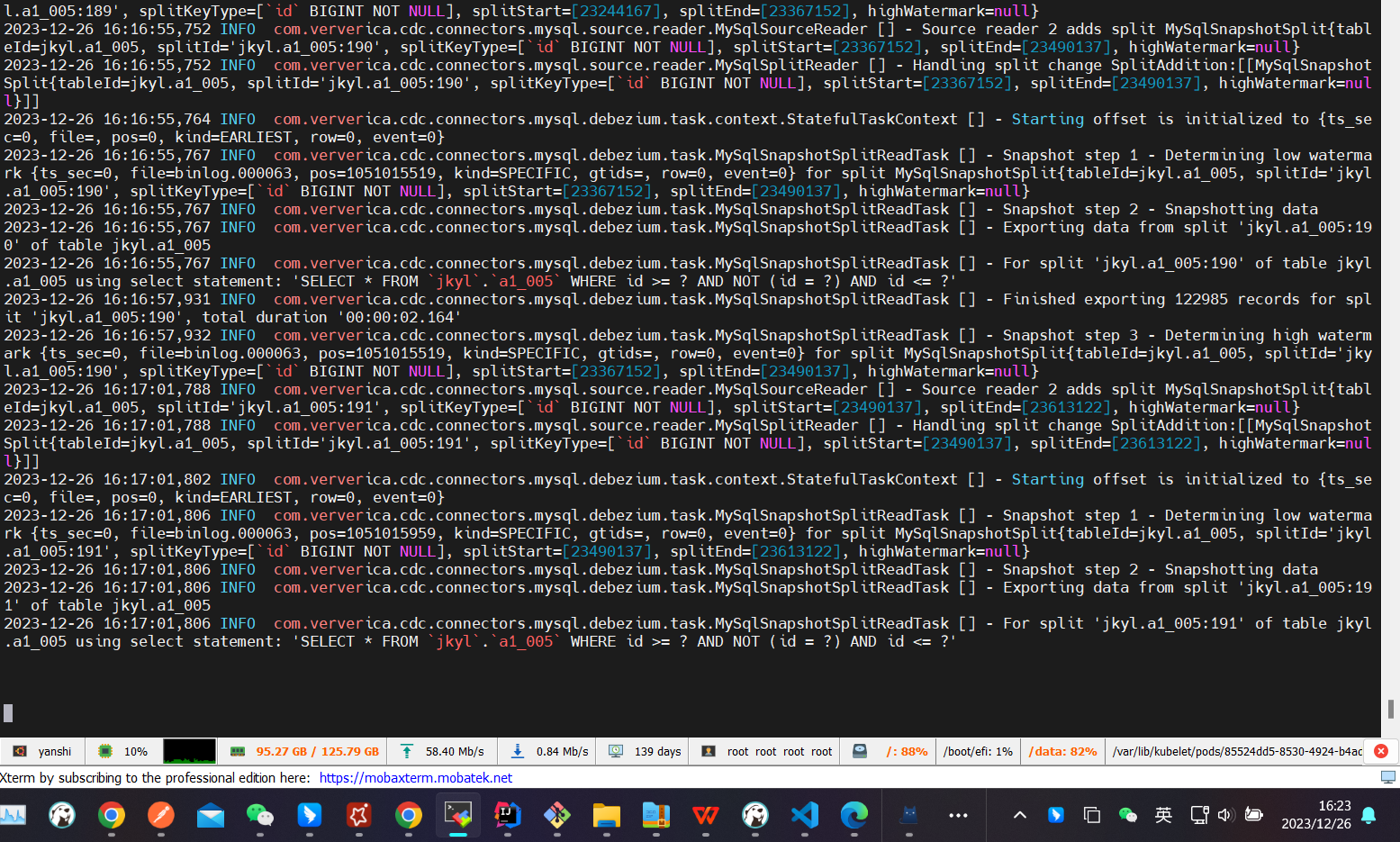
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,Flink CDC在增量快照读取过程中停止,且日志中未显示任何错误信息。结合知识库中的相关资料,以下是可能导致该问题的原因及解决方案:
scan.incremental.snapshot.chunk.size的值来降低每个分片的数据量。例如,将其设置为较小的值(如5000或10000)。
'scan.incremental.snapshot.chunk.size' = '5000'
taskmanager.memory.process.size参数为更大的值(如4GB或8GB)。'execution.checkpointing.interval' = '60s'
'server-id' = '123456-123457'
scan.incremental.snapshot.chunk.key-column参数指定主键中的其他字段进行分片划分。例如:
'scan.incremental.snapshot.chunk.key-column' = 'column_name'
监控日志和资源使用情况:
优化StarRocks写入性能:
sink.buffer-flush.interval-ms和sink.properties.row_delimiter等参数。分批处理历史数据:
根据上述分析,建议您优先检查以下配置: - 调整scan.incremental.snapshot.chunk.size和TaskManager内存配置。 - 设置合理的Checkpoint间隔时间。 - 确认MySQL实例类型是否支持增量读取。 - 为每个CDC源表指定唯一的Server ID。 - 升级Flink和CDC版本以解决潜在的兼容性问题。
如果问题仍未解决,请提供更多日志信息以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

