
请问下大数据计算MaxCompute这个为什么会报错?测试的是官网的例子。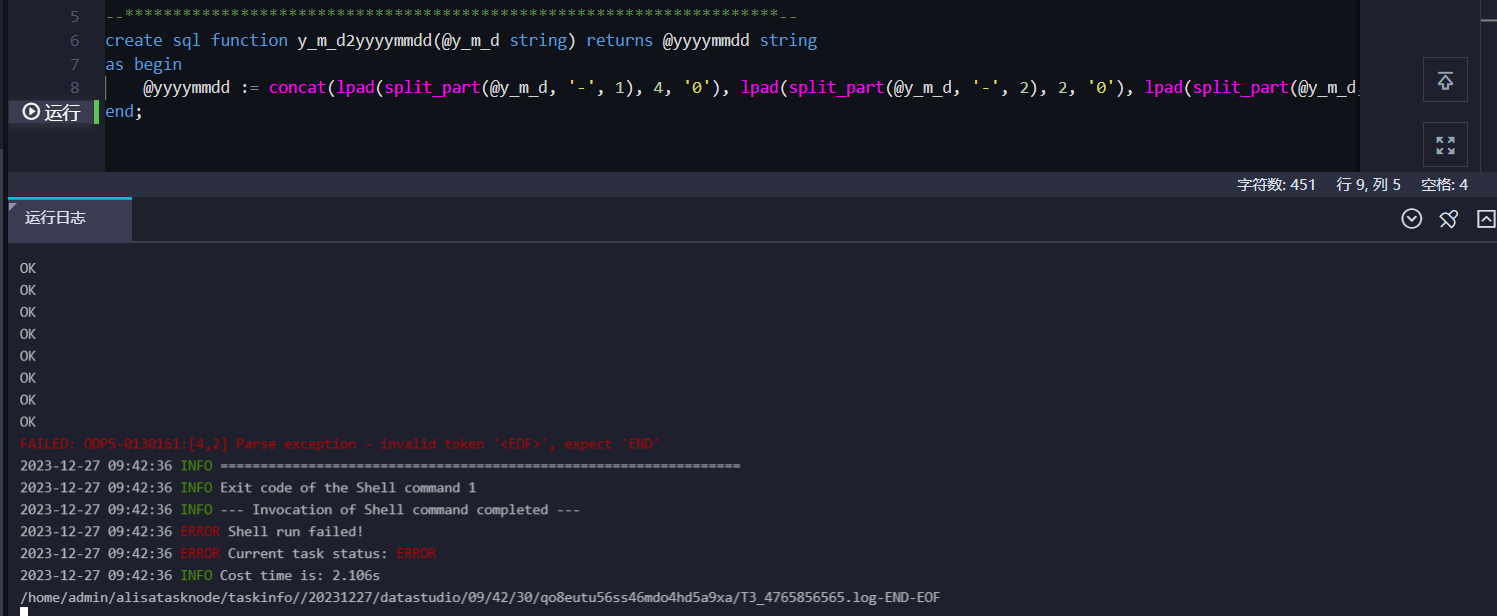
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的问题描述,MaxCompute在测试官网示例时出现报错,但未明确具体的错误信息。以下是基于知识库中常见问题的分析和解决方法,请结合实际报错信息进行排查和处理。
如果报错信息中包含kInstanceMonitorTimeout,可能是由于UDF(用户自定义函数)处理时间过长导致超时。
ExecutionContext.claimAlive方法,定期重置计时器。odps.function.timeout参数,延长超时时间。例如:
set odps.function.timeout=3600; -- 将超时时间设置为3600秒
set odps.stage.mapper.split.size=512; -- 调整Mapper输入数据量
set odps.stage.reducer.num=10; -- 增加Reducer数量
如果报错信息中包含Authorization Failed或You have NO privilege,可能是权限配置问题。
odps:Select、odps:CreateResource等必要权限。如果报错信息中包含Semantic analysis exception,可能是SQL语法或UDTF(用户自定义表函数)使用不当。
expect 2 aliases but have 0as子句指定输出列名。例如:
select udtffunction_name(paramname) as (col1, col2);
only a single expression in the SELECT clause is supported with UDTF's如果报错信息中包含OutOfMemoryError或No space left on device,可能是资源不足导致的问题。
spark.driver.memory参数,例如:
spark.driver.memory=8g
spark.executor.memory参数,例如:
spark.executor.memory=8g
spark.hadoop.odps.cupid.disk.driver.device_size参数,例如:
spark.hadoop.odps.cupid.disk.driver.device_size=50g
spark.executor.cores),并增加Executor数量(spark.executor.instances)。如果报错信息中包含Table or view not found,可能是表或视图未正确创建。
show tables;
enableHiveSupport()配置。例如:
spark = SparkSession.builder.appName(app_name).getOrCreate()
如果以上情况均不适用,请参考以下补充说明:
身份验证失败:
User signature does not matchspark-defaults.conf中的AccessKey ID和AccessKey Secret是否正确。Session过期:
The download session is expired小文件过多:
StatusConflict请根据实际报错信息,结合上述分析逐一排查问题。如果仍无法解决,请提供具体的错误码或报错信息,以便进一步定位问题。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

