
ModelScope根据范例,把文件下载到当前目录中,执行时返回报错,示例代码?import soundfile
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='damo/speech_UniASR_asr_2pass-en-16k-common-vocab1080-tensorflow1-offline')
waveform, sample_rate = torchaudio.load("asr_example_en.wav")
rec_result = inference_pipeline(audio_in=waveform)
print(rec_result)
报错如下: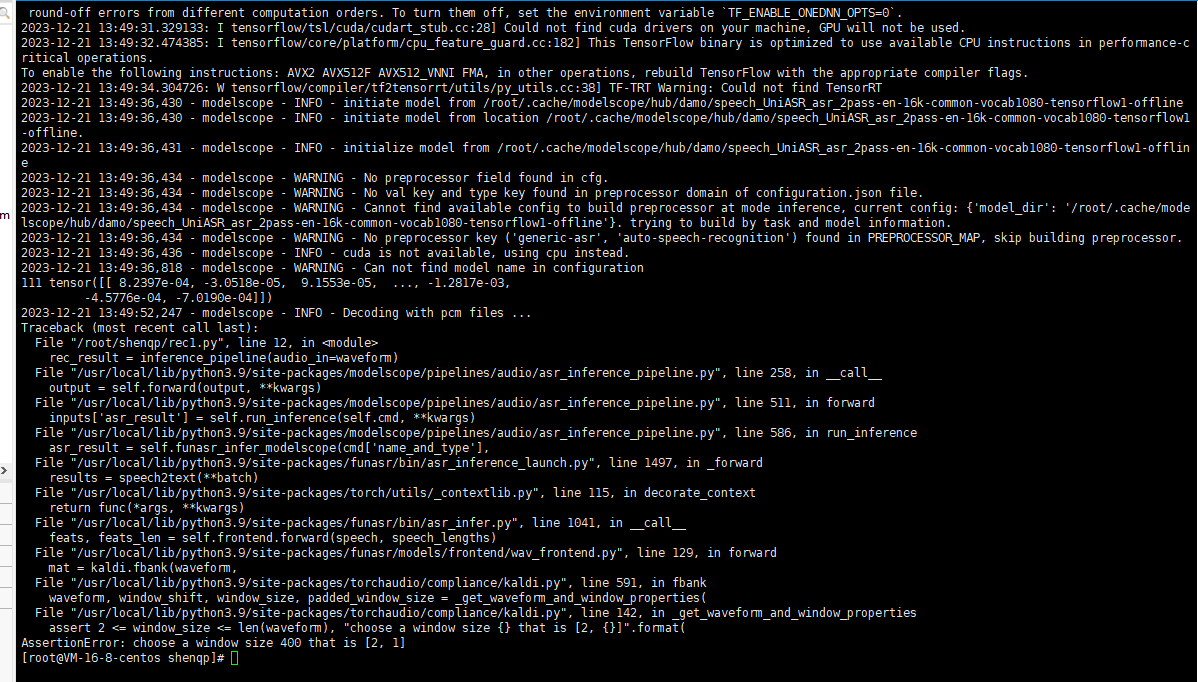
根据您提供的代码示例和报错信息,问题可能与文件下载路径或依赖项未正确配置有关。以下是详细的分析和解决方案:
ModelScope 默认会将模型文件下载到用户的缓存目录中。例如,在 Linux 系统中,默认路径为 ~/.cache/modelscope。如果当前目录没有正确设置,可能会导致文件加载失败。
解决方法: - 您可以通过打印 model_dir 变量来确认模型的实际下载路径。 - 如果需要将文件下载到当前目录,请在代码中显式指定路径。例如:
import os
from modelscope.hub.snapshot_download import snapshot_download
# 下载模型到当前目录
model_dir = snapshot_download('damo/speech_UniASR_asr_2pass-en-16k-common-vocab1080-tensorflow1-offline', cache_dir='./')
print(f"模型下载路径: {model_dir}")
您的代码中使用了 torchaudio 和 soundfile 等库。如果这些依赖项未正确安装或版本不匹配,也可能导致报错。
解决方法: - 确保已安装以下依赖项,并检查其版本是否兼容:
pip install torch torchaudio soundfile modelscope
pip install --upgrade torch torchaudio soundfile modelscope
根据您的代码示例,可能存在以下问题: - 音频文件路径错误:asr_example_en.wav 文件可能不存在于当前工作目录中。 - 模型加载路径错误:模型文件未正确加载到指定路径。
以下是调整后的完整代码示例:
import os
import torchaudio
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
from modelscope.hub.snapshot_download import snapshot_download
# 下载模型到当前目录
model_dir = snapshot_download('damo/speech_UniASR_asr_2pass-en-16k-common-vocab1080-tensorflow1-offline', cache_dir='./')
print(f"模型下载路径: {model_dir}")
# 初始化推理管道
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model=model_dir # 使用下载的模型路径
)
# 加载音频文件
audio_path = "asr_example_en.wav"
if not os.path.exists(audio_path):
raise FileNotFoundError(f"音频文件未找到: {audio_path}")
waveform, sample_rate = torchaudio.load(audio_path)
# 执行推理
rec_result = inference_pipeline(audio_in=waveform)
print("识别结果:", rec_result)
asr_example_en.wav 是有效的 WAV 格式文件。如果文件损坏或格式不支持,可以使用工具(如 ffmpeg)进行转换。如果上述方法仍无法解决问题,请提供具体的报错信息(如错误堆栈)。常见的报错原因包括: - 模型文件缺失:可能是下载过程中中断或路径错误。 - 依赖冲突:不同版本的库之间可能存在兼容性问题。 - 硬件限制:某些模型可能需要 GPU 支持,而当前环境仅支持 CPU。
通过以上步骤,您可以有效解决 ModelScope 示例代码中的问题。如果仍有疑问,请提供更多上下文信息以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
