
Flink CDC有谁知道oceanbase cdc这里为什么要先读changeRecords再读snapshotRecords么?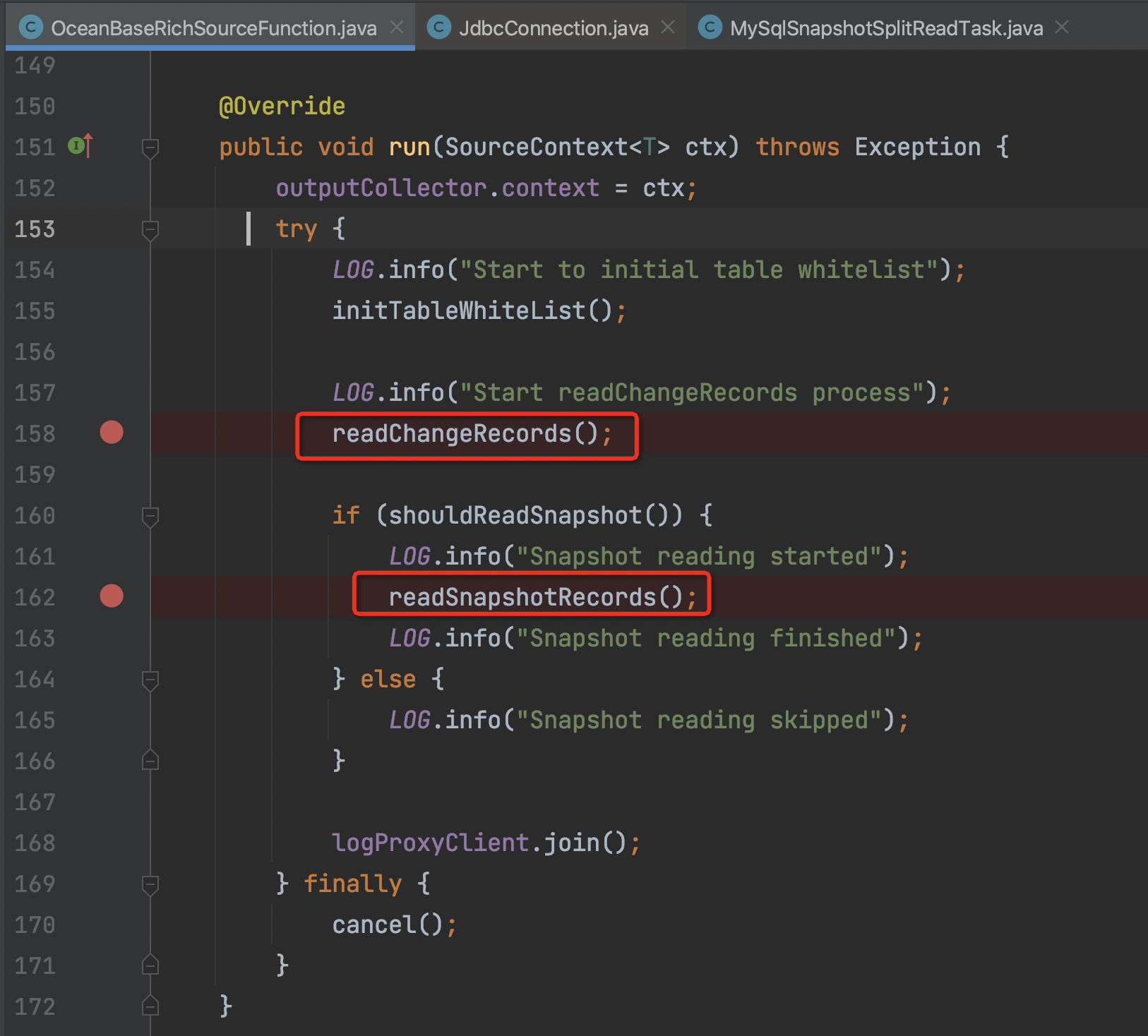
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用 Flink CDC 连接 OceanBase 数据库时,可能会遇到先读取 changeRecords(增量数据)再读取 snapshotRecords(全量数据)的情况。这种行为通常与 OceanBase 的 Binlog 服务机制以及 Flink CDC 的实现逻辑有关。以下是详细的原因分析和解释:
OceanBase 的 Binlog 服务支持两种数据拉取模式:基于 filename + offset 和基于 GTID 的订阅模式。
- Binlog 日志的生成:OceanBase 会将租户内的所有库表的增量数据(即变更记录)实时转储为 Binlog 日志,并持久化存储。 - 日志回收策略:默认情况下,OceanBase 的 Binlog 日志仅保留 18 小时或 50GB 的存储空间,任一条件满足后会触发日志回收。
因此,如果 Flink CDC 在启动时未能及时消费增量数据(changeRecords),可能会导致部分增量数据丢失。为了避免这种情况,Flink CDC 会优先读取增量数据以确保数据完整性。
Flink CDC 在处理 OceanBase 数据源时,通常分为两个阶段: 1. Snapshot 阶段:读取数据库的全量数据(snapshotRecords)。 2. Incremental 阶段:读取数据库的增量数据(changeRecords)。
然而,在某些场景下,Flink CDC 可能会调整这两个阶段的执行顺序,原因如下: - 避免数据丢失:如果 Flink CDC 启动时检测到 Binlog 中存在未消费的增量数据,它会优先读取这些增量数据,以防止因日志回收而导致数据丢失。 - 保证数据一致性:通过先读取增量数据,Flink CDC 可以确保在切换到全量数据读取时,增量数据已经被完整捕获,从而避免数据重复或遗漏。
在 OceanBase 的只读副本场景中,只读副本作为观察者(Observer)实时追赶主集群的日志并回放。
- 如果 Flink CDC 连接到的是 OceanBase 的只读副本,可能会因为日志同步延迟而导致增量数据的读取优先级高于全量数据。 - 此外,只读副本不参与 Paxos 投票,其日志同步可能存在一定的滞后性,这也可能导致 Flink CDC 优先处理增量数据以减少延迟。
如果您希望跳过全量数据读取(snapshotRecords),直接从增量数据(changeRecords)开始读取,可以通过以下方式配置: - 配置参数:在 Flink CDC 的配置中,设置 scan.startup.mode 参数为 latest-offset,以跳过全量数据读取阶段。 - 注意事项:跳过全量数据读取可能会导致历史数据的缺失,请确保业务场景允许这种操作。
Flink CDC 先读取 changeRecords 再读取 snapshotRecords 的行为主要是为了: - 避免数据丢失:优先捕获增量数据,防止因日志回收导致的数据丢失。 - 保证数据一致性:确保增量数据在全量数据读取前已被完整捕获。
如果您希望调整读取顺序或跳过全量数据读取,请根据业务需求合理配置 Flink CDC 参数,并确保 OceanBase 的 Binlog 服务已正确开启且日志保留时间满足业务需求。
如有进一步疑问,请提供更多上下文信息以便更精准地解答。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

